之前的一篇文章探讨了 Cilium 在 Native Routing 模式下的数据路径。然而,该模式对底层网络环境有特定要求,使其无法适用于所有场景,因此,不依赖底层网络、具有更强兼容性的 VXLAN 模式成为了一种重要的替代方案。VXLAN 会引入额外的封装与解封装开销,其具体实现过程值得关注:当数据包离开 Pod 时,eBPF 程序如何在内核中拦截该数据包,对其进行 VXLAN 封装,并最终将其发送至目标节点?本文旨在深入解析 Cilium VXLAN 模式的数据路径实现细节。
关联文章:
-
VXLAN 原理和手动实现方案:Host-GW, VXLAN, IPIP:K8s 跨节点通信原理与手动复现
-
eBPF 相关一些前置知识点:Cilium: 原生路由 (Native Routing) 模式下的 eBPF 数据路径
这两篇文章中已经说明了 VXLAN 的具体作用,以及本文所需要 eBPF 的相关前置知识,这里也不准备进行细致抓包演示(后续会做),所以这里直接进入主题,说明白 VXLAN 模式下 eBPF 的数据路径。
一、VXLAN 模式下所使用到的 TC HOOK
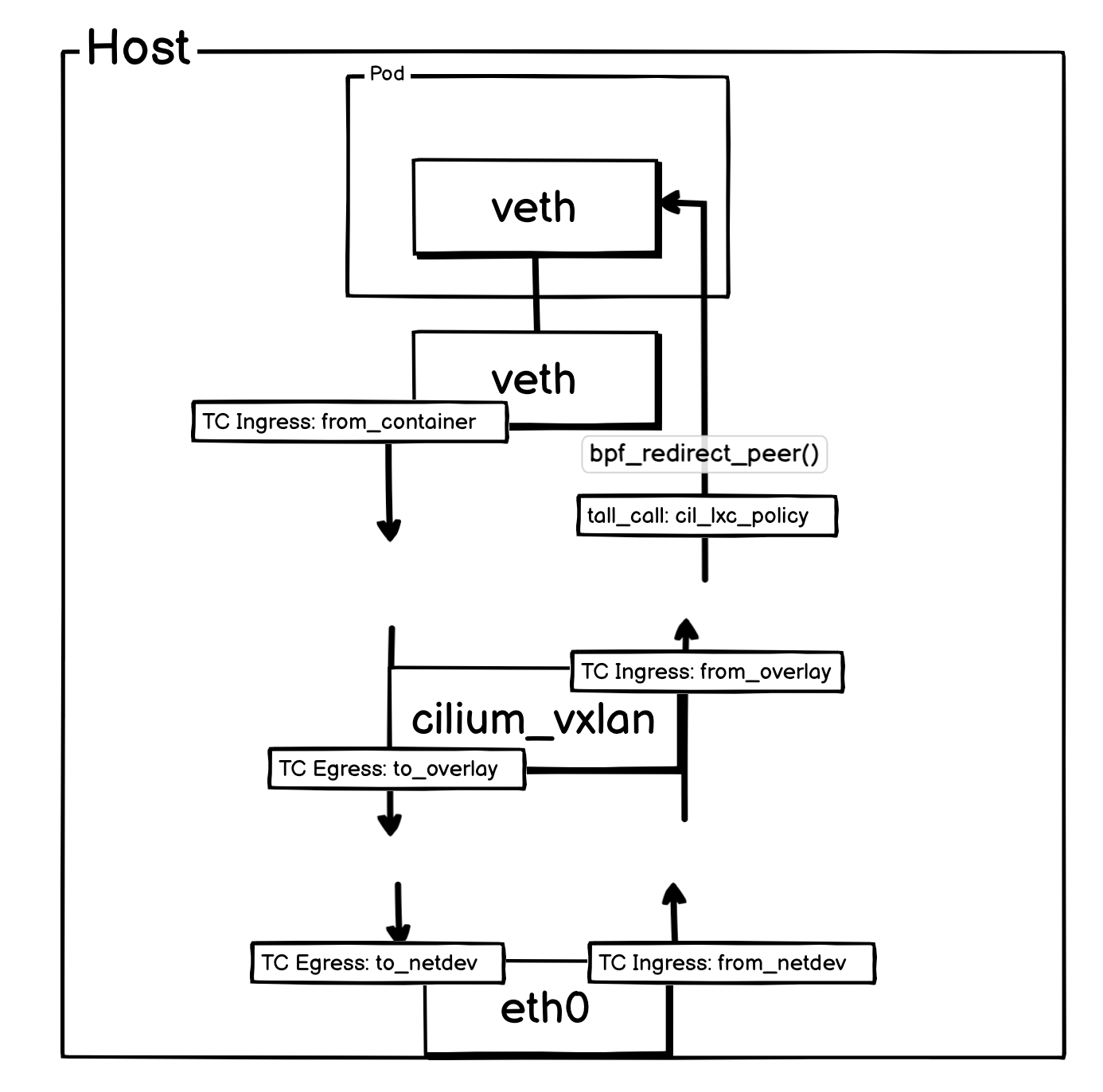
除了 cilium_vxlan 设备上的两个 TC Hook,其他 TC Hook 都在前文中有过介绍,这里就不再赘述。
和其他 CNI 一样,cilium 在VXLAN模式,也新增了 vxlan 设备。并且在其上 TC Ingress 和 TC Egress 上,分别挂载了两个 eBPF 程序。
from_overlay:- 处理方向: 接收从其他节点通过 Overlay 通道传来的数据包
- 挂载点: 宿主机
cilium_vxlan网卡的TC Ingress Hook - 核心职责:解析数据包的来源身份,并将数据包转发到 Pod 或宿主机网络协议栈。
to_overlay:- 处理方向: 接收 Pod 将通过 Overlay 通道发送到其他 Pod 的数据包
- 挂载点: 宿主机
cilium_vxlan网卡的TC Egress Hook - 核心职责:为数据包打上正确的标记、处理带宽管理、以及在需要时执行 NAT 转换。
一、同宿主机 Pod 间通信
通宿主机 Pod 与 Pod 间通信,VXLAN 模式和 Native Routing 模式并无区别,这里复制的 Native Routing 的
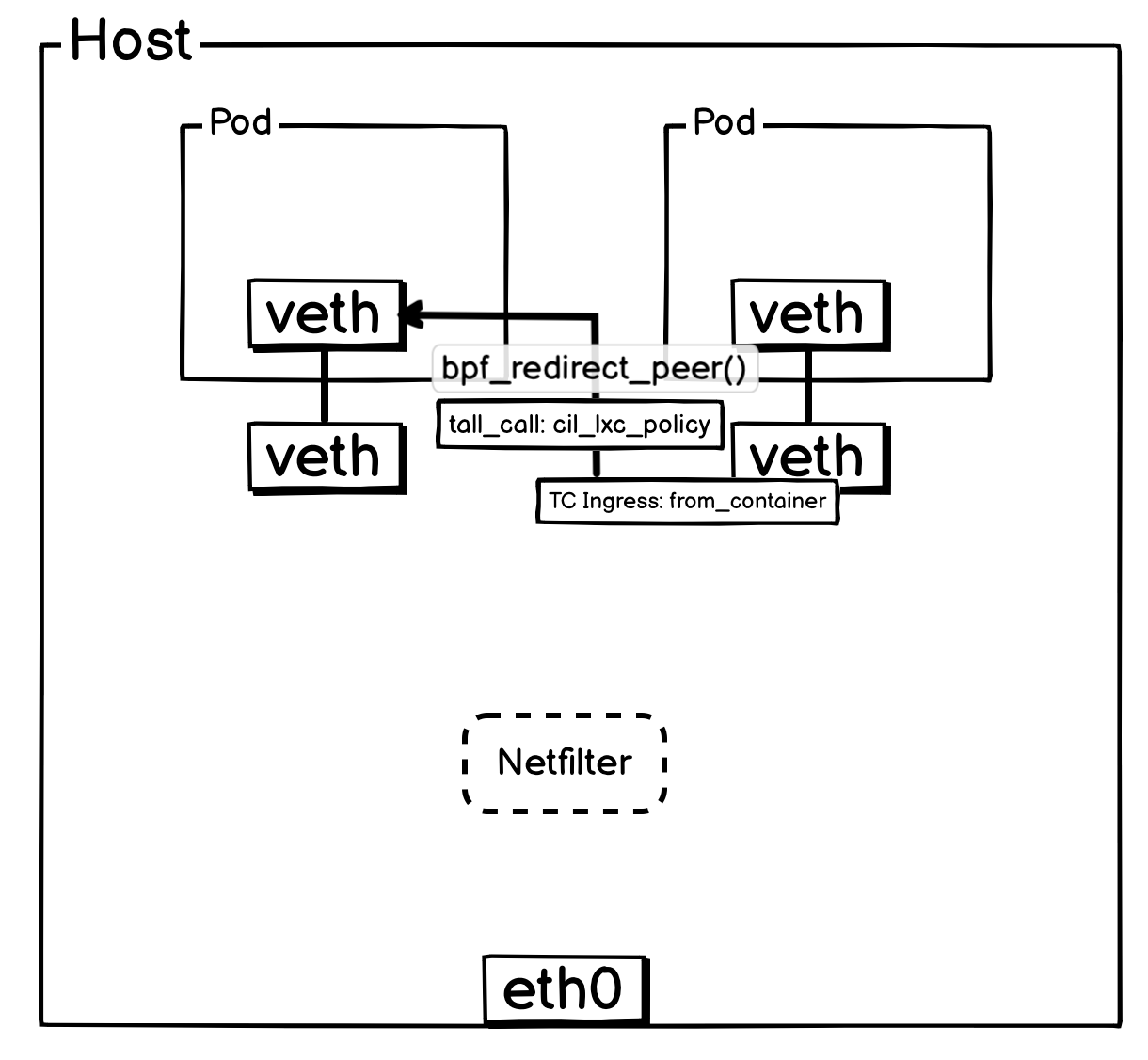
当报文离开 Pod 后,会立即由其所在宿主机上的 veth-pair 网卡TC Ingress Hook 处挂载的 from_container 序接管。
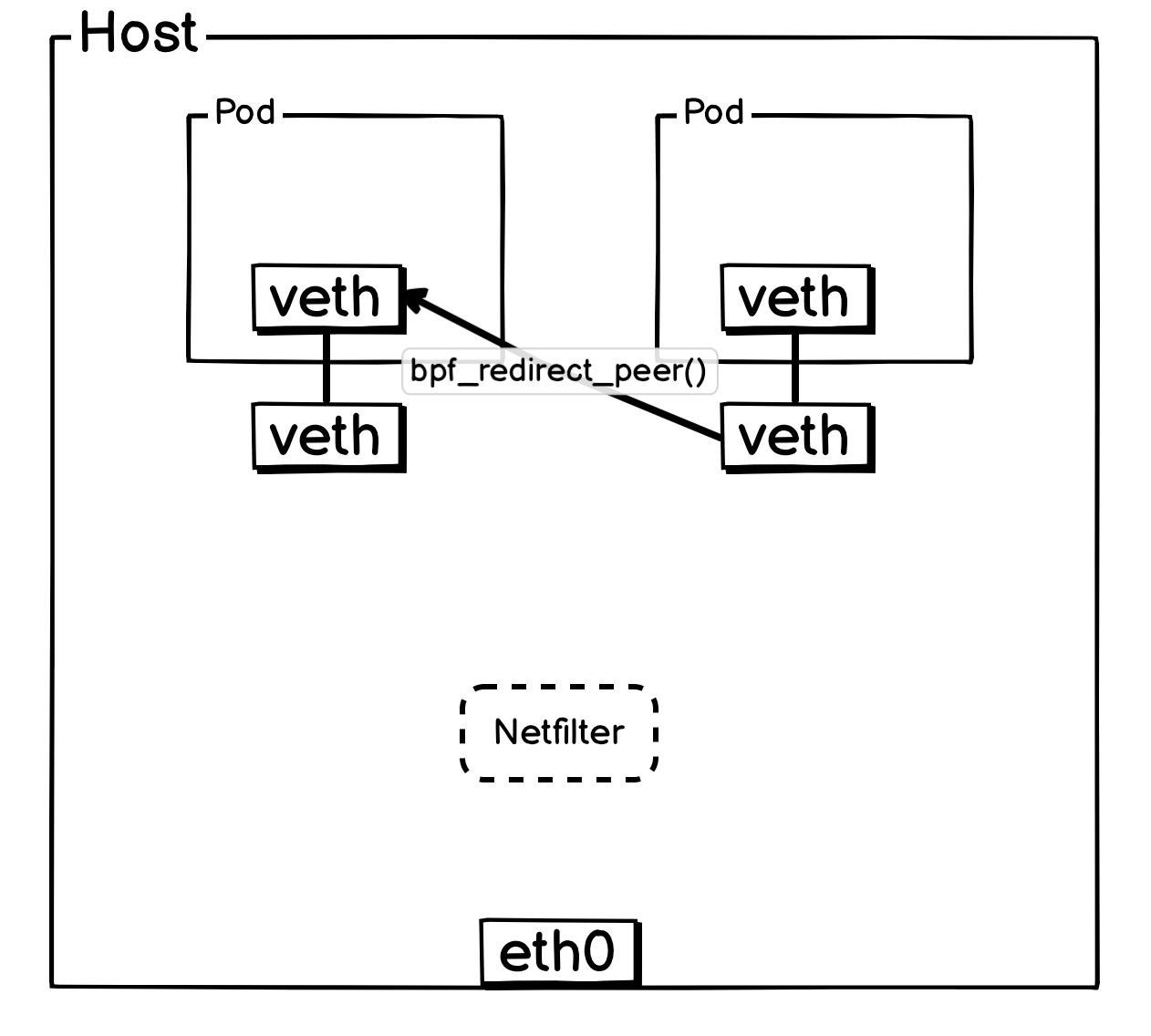
判断如果是同宿主机 Pod ,会通过尾调调用 ipv4_local_delivery 函数,而 ipv4_local_delivery 就负责同宿主机 Pod 报文的投递,ipv4_local_delivery 后续会通过尾调调用目标 Pod 的 cil_lxc_policy 的 eBPF 程序,目标 Pod 的 cil_lxc_policy 经过策略判断后是否放行后,会调用 bpf_redirect_peer() 将报文转发到目标 Pod 内部 veth 网卡。
简化后方便理解的网络流转图:
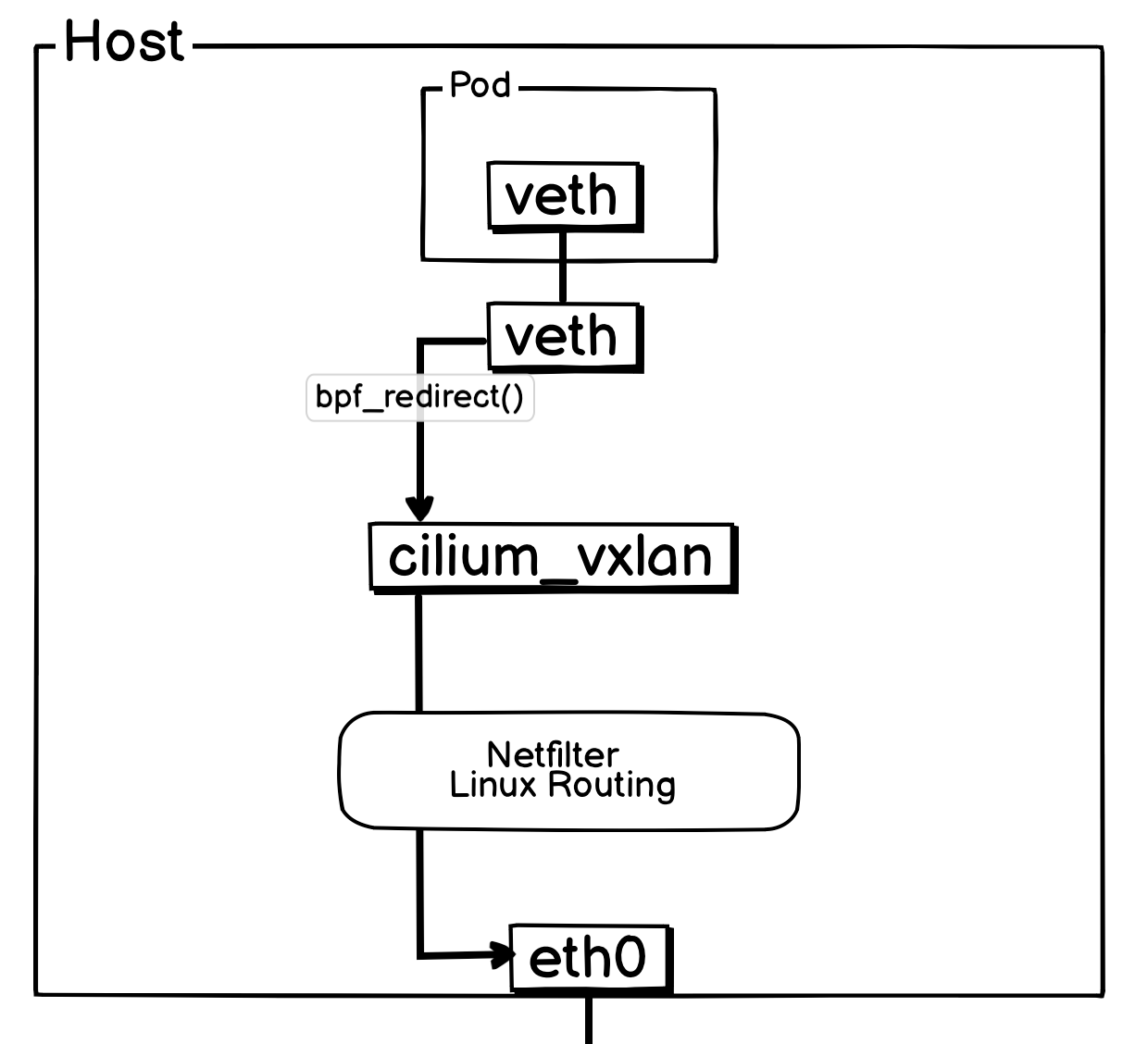
二、同宿主机 Pod 间通信之出向流量
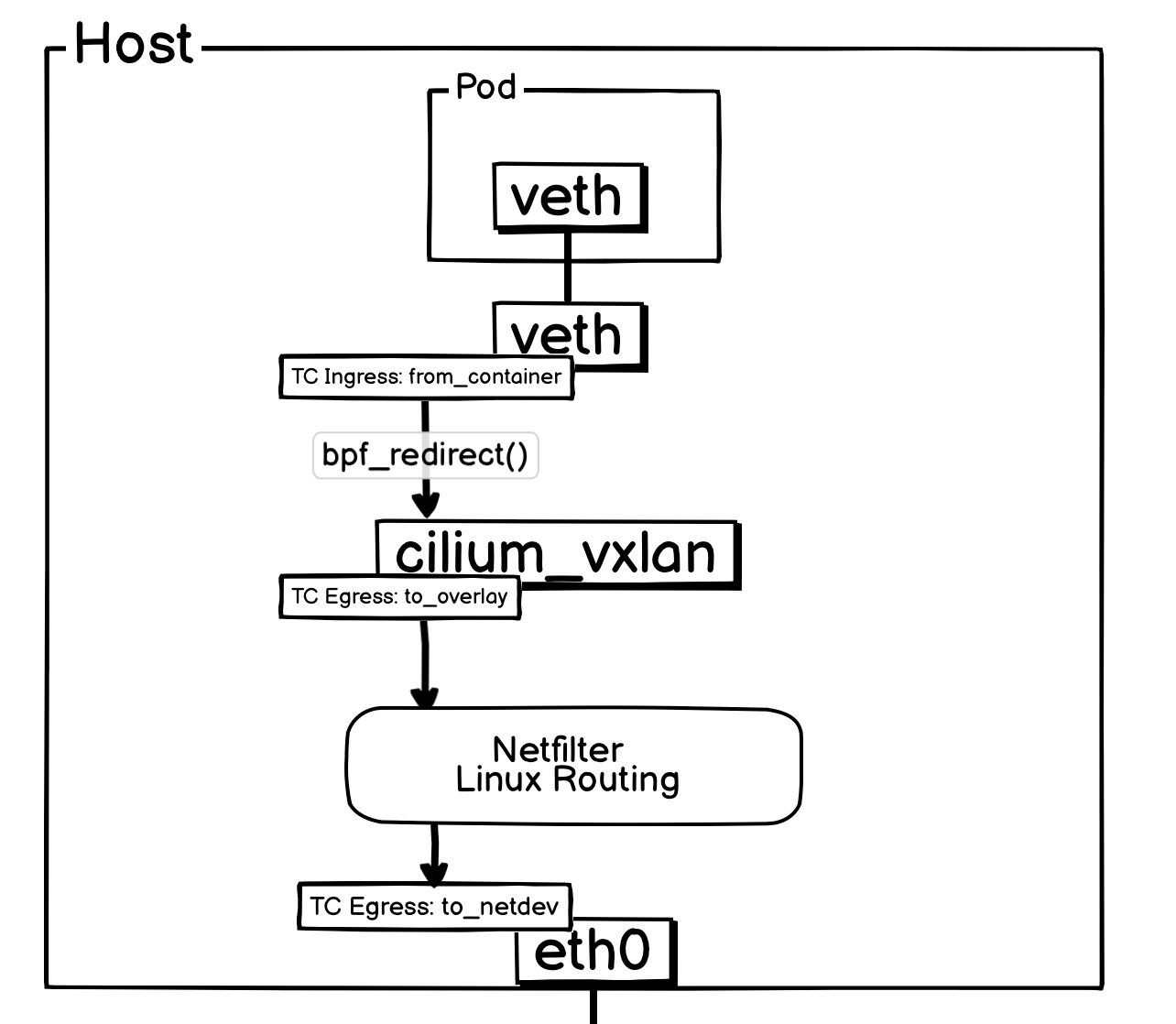
和上面一样,当报文离开 Pod 后,会立即由其所在宿主机上的 veth-pair 网卡TC Ingress Hook 处挂载的 from_container 序接管。
from_container 程序会依据目标地址,检查网络策略是否允许该通信。若策略允许,在 VXLAN 模式下,程序会调用 encap_and_redirect_lxc 函数,为报文附加隧道元数据(包括远程 VTEP IP 和 VXLAN VNI),并通过 bpf_redirect() 函数将报文重定向至 cilium_vxlan 网卡。
bpf_redirect()的作用是将报文直接转发至指定网卡并由其发出。因此,报文抵达cilium_vxlan网卡时,并未触发其 TC Ingress Hook,而是直接进入了 TC Egress Hook,由to_overlay程序处理。
在 Cilium 的 VXLAN 模式下,封装报文时使用的 VXLAN VNI 直接源自源工作负载的 Identity ID。这种设计使得网络策略的校验变得高效:只需检查报文的 VNI 是否有权限发送至目标 Pod 即可。
在当前流程中,to_overlay 程序的主要工作是确认元数据信息,并检查是否需要执行 NAT(通常仅在 NodePort 场景下触发)。完成这些检查后,它便将报文递交给内核网络协议栈。
由于报文来自 cilium_vxlan 这个虚拟设备且已携带完整的隧道元数据,内核协议栈会依据这些元数据自动进行 VXLAN 封装。封装完成后,报文的最外层 IP 头部为宿主机 IP,因此该报文将经过宿主机的 OUTPUT -> POSTROUTING 链。
最终,报文准备通过物理网卡 eth0 发出,此时会触发挂载在 eth0 上的 to_netdev eBPF 程序。该程序同样会执行网络策略检查,但在当前场景下,对于这个已经过层层验证的报文,其操作通常是直接放行。
至此,一个数据包从 Pod 发出并离开宿主机的完整流程便告完成。
简化后方便理解的网络流转图:
三、同宿主机 Pod 间通信之入向流量
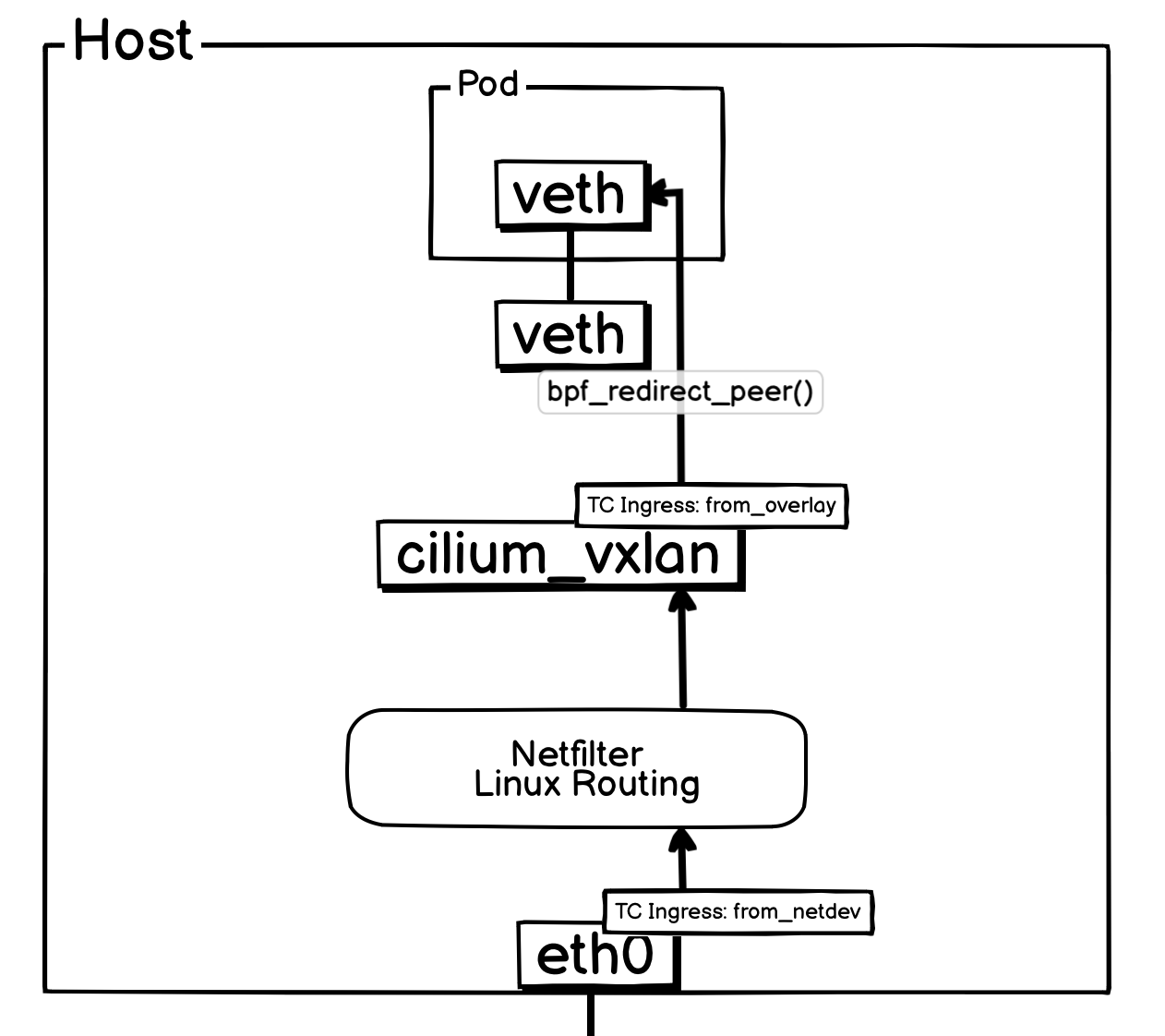
当一个外部 VXLAN 报文(即一个目标为宿主机的 UDP 报文)抵达 eth0 网卡时,将首先由挂载在其 TC Ingress Hook 上的 from_netdev eBPF 程序进行处理。该程序主要负责检查主机防火墙是否存在限制,确认无误后,便将报文放行至内核网络协议栈。
由于报文的外层 IP 地址是宿主机自身,它会依次经过内核的 PREROUTING 和 INPUT 链。随后,内核的 VXLAN 模块识别并解封装该报文,并将解封后的内部报文转发至 cilium_vxlan 虚拟网卡。
这一转发动作会触发 cilium_vxlan 网卡 TC Ingress Hook 上的 from_overlay 程序。该程序利用报文元数据中携带的 VNI 来执行网络策略检查。若策略允许通信,from_overlay 便会调用 ipv4_local_delivery 函数,并最终通过 bpf_redirect_peer() 将报文直接、高效地重定向至目标 Pod。
入方向的报文从进入宿主机到送达目标 Pod 的完整处理流程到这里就结束了。
简化后方便理解的网络流转图:
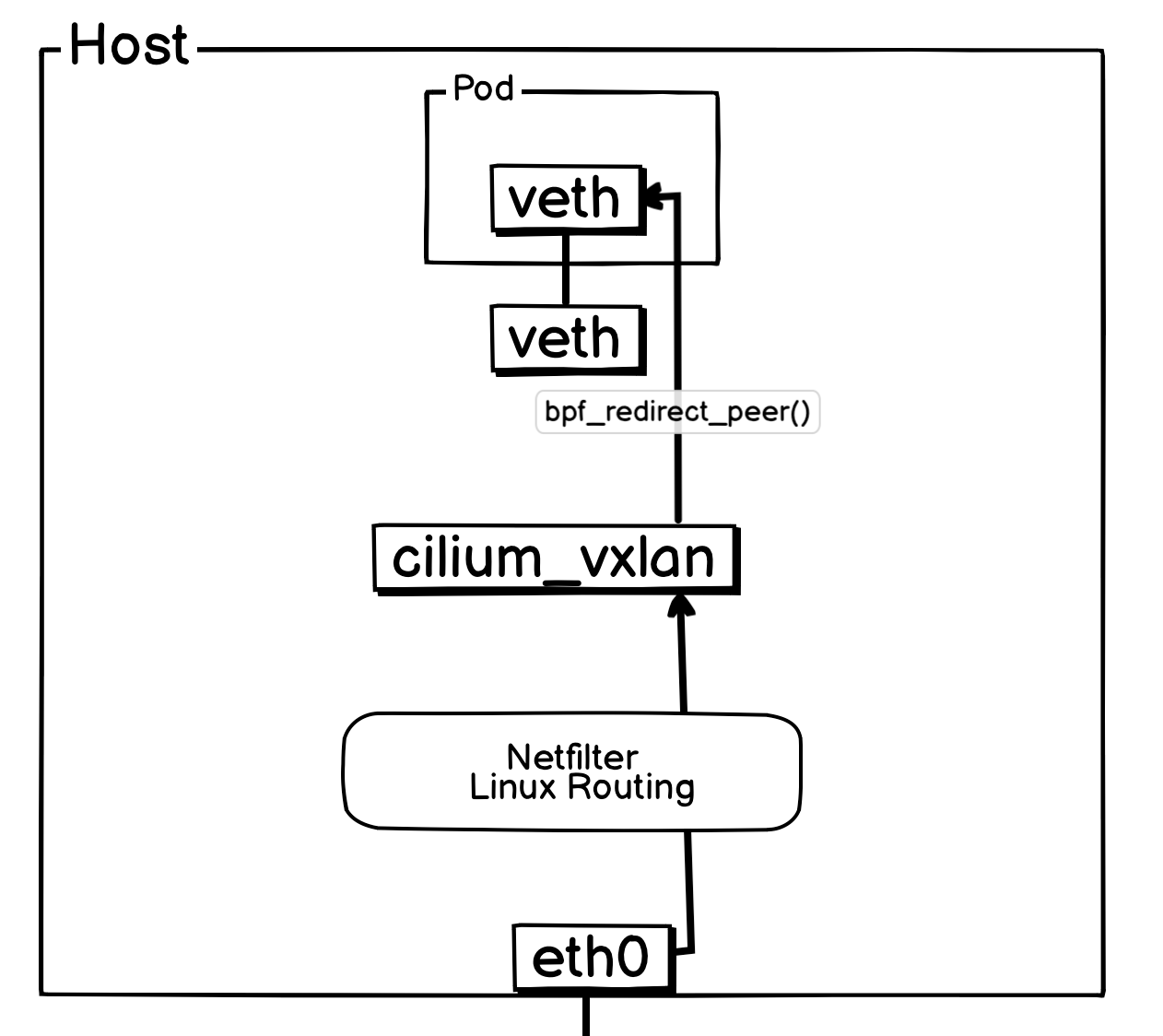
至此,整个 Cilium VXLAN 模式下的 eBPF 数据路径已经梳理完了。
四、杂谈
其实可以看到,整个数据流转流程,除了同宿主机 Pod to Pod 之外,其他路径根本没有优化多少。
优化的部分:从 Pod 到 eth0,或者从 eth0 到 Pod ,每次报文转发,都跳过了一次网络协议栈,即 veth 到 cilium_vxlan 中间,如果报文不 redirect ,是需要再过一遍宿主机网络协议栈的。
疑问的部分: 为什么报文不从 eth0 出来,就直接通过 eBPF 解封装,然后丢给 cilium_vxlan ,甚至是直接丢给 Pod 内部的 veth 网卡?这才是 Cilium 通常使用的手段啊。
这个问题我去 Cilium Slack 上问过,有个人回复了我,大致意思是,如果所有内容都通过 eBPF 来做,就太笨重了,而且社区本身后面也准备对 VXLAN 模式再进行优化。
但是我觉得这个回答不是很靠谱,从我的感觉里面来说,在网络策略被 Cilium 接管的情况下,内核 Netfilter 并没有超多规则链来拖慢性能,并且 VXLAN 本身也不是那么好轻轻松松就写一个替代出来的,eBPF 程序是有各种限制的,也不能像普通程序那样可以随意的写。真要用 eBPF 实现 VXLAN 的功能,不如重新设计一个 Overlay 的方案。所以综合来看,VXLAN 包丢给内核处理,确实是比较正确的选择。
结束语
与 Native Routing 的直接路由相比,VXLAN 模式虽然引入了一定的性能开销,但其优势在于更好的网络环境兼容性。深入理解其实现原理,有助于更准确地进行网络故障排查与性能调优。此外,Cilium 的能力远不止于数据路径,其网络策略、服务负载均衡等高级功能同样由 eBPF 技术驱动,我们将在后续文章中对这些主题做进一步的探讨。