随着云原生生态的发展,各种新技术、新项目层出不穷,而在容器网络领域,以 eBPF 为核心的 Cilium 已成为性能最强的容器网络方案之一,它显著提升了网络性能与可观测性。然而,eBPF 在带来强大的性能的同时,也带来了数据路径的复杂性。理解其内部工作原理对于故障排查至关重要。因此,本文旨在详细剖析 Cilium 原生路由模式的 eBPF 数据路径,阐明其报文转发流程,为生产实践提供参考。
一、前置信息
1. 什么是 eBPF
eBPF 本质上是一个运行在内核空间的轻量级沙盒虚拟机。它允许开发者使用 C 语言等编写程序,编译为 eBPF 字节码,并在通过内核的严格验证后,动态加载至内核执行。这种设计巧妙地平衡了灵活性、性能与安全性,使得在不修改内核源码或重启系统的前提下,动态扩展内核功能、实时调整系统行为成为可能。
2. Cilium 场景下,eBPF 运行在哪些地方
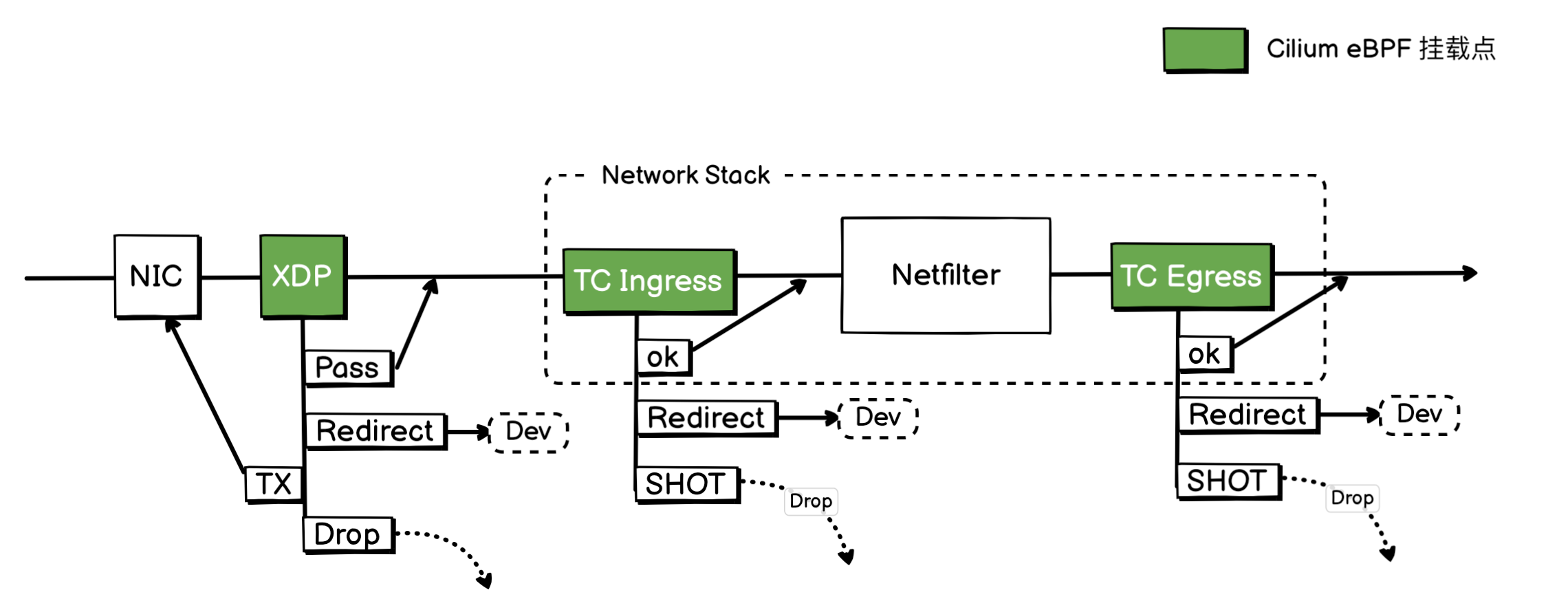
上面是一个简化 Linux 网络路径图,上面绿色部分,就是 Cilium 会挂载 eBPF 的挂载点。
XDP (eXpress Data Path):
XDP 是在报文还没有进入网络协议栈之前就介入的 Hook,这样能使得 XDP 性能超强,但是同时它也有一个缺点,就是它只能运行在物理网卡上。
XDP 主要有以下三种工作模式:
- Offloaded XDP (卸载模式):
- 工作原理: 这是性能最高的模式。整个 eBPF 程序被卸载到支持该功能的智能网卡(SmartNIC)上执行。数据包的处理完全在网卡硬件上完成,根本不占用主机的 CPU 资源。
- 优点: 极致的性能,CPU 零开销。
- 要求: 需要有支持 XDP 卸载的特定智能网卡硬件。
- Native XDP (原生模式):
- 工作原理: 这是 XDP 最常用也是默认的模式。eBPF 程序直接挂载到网络接口(NIC)的驱动程序中,在驱动程序的早期接收路径上执行。
- 优点: 性能非常高,因为它绕过了内核网络协议栈的大部分开销。
- 要求: 需要网络驱动程序的显式支持。目前,主流的 10G 及以上速率的网卡驱动大多已支持 Native XDP。
- Generic XDP (通用模式):
- 工作原理: 这是一种兜底或备用模式。当驱动程序既不支持 Native 模式也不支持 Offloaded 模式时,XDP 程序会作为内核网络协议栈的一部分在稍晚的阶段执行。
- 优点: 无需任何特殊的驱动或硬件支持,只要内核版本高于 4.12 即可运行,非常适合用于开发和测试。
- 缺点: 性能远不如 Native 和 Offloaded 模式,因为它没有绕过内核协议栈的关键部分。
如果 Cilium 启用了 XDP 加速,那么 Cilium 会自动按性能由高到低进行加载,优先使用性能较高的模式。
XDP 主要应用场景包括:
- DDoS 防御:在驱动层直接丢弃恶意流量,避免消耗系统资源。
- 防火墙与过滤:根据 IP、端口等信息高效地过滤数据包。
- 负载均衡:通过
XDP_TX或XDP_REDIRECT将数据包快速转发到其他服务器或网络接口。 - 性能监控:在不显著影响性能的情况下对网络流量进行采样和分析。
TC Ingress
TC Ingress 是属于网络协议栈内的 Hook,所以所有网络设备,都可以使用此 Hook 。
数据包从网卡驱动程序处理完毕,内核为其成功分配了核心的 sk_buff 结构后,便正式进入了内核协议栈,此时就会触发 TC Ingress 钩子。
Cilium 在这里可以对数据包进行高效处理,例如执行网络策略、实现负载均衡、将流量重定向到其他网络设备或丢弃非法报文。这是 Cilium 中最核心、最常用的挂载点之一。
TC Ingress 的主要返回值有三个:
TC_ACT_OK: 放行,允许数据包继续向上层协议栈传递,进入 Netfilter 等后续处理流程TC_ACT_REDIRECT: 重定向,将数据包转发到另一个网络接口。TC_ACT_SHOT: 丢弃,因违反策略等原因将数据包直接丢弃。
TC Egress
当一个数据包已经走完了整个内核协议栈(包括路由决策、Netfilter 等所有处理),在即将被交给网卡驱动程序、发送到物理网络之前的最后一刻,就会触发 TC Egress 钩子。
这里是数据包离开节点的最后一道“关卡”,也是执行出口流量控制的理想位置。Cilium 在这里可以实现出口网络策略 (Egress Policy)、执行 SNAT (源地址转换),或者对数据包进行服务质量(QoS)标记。
TC Egress 的返回值与 TC Ingress 完全相同,其主要含义为:
TC_ACT_OK: 放行,允许数据包被交给网卡驱动程序进行最终的发送。TC_ACT_REDIRECT: 重定向,在最后一刻改变数据包的出口,例如将其重定向到一个隧道接口。TC_ACT_SHOT: 丢弃,如果数据包违反了出口策略,则在发送前的最后一刻将其拦截并丢弃。
二、Cilium 到底优化了什么
在传统的 HostGW 模式中,或者其他没有开启 eBPF 特性的 Cilium Native Routing 模式中,流量从外部进入 Pod,或者 Pod 从内部把流量发出去,都会需要经过两层网络协议栈,一层是宿主机的,一层是 Pod 自身的。
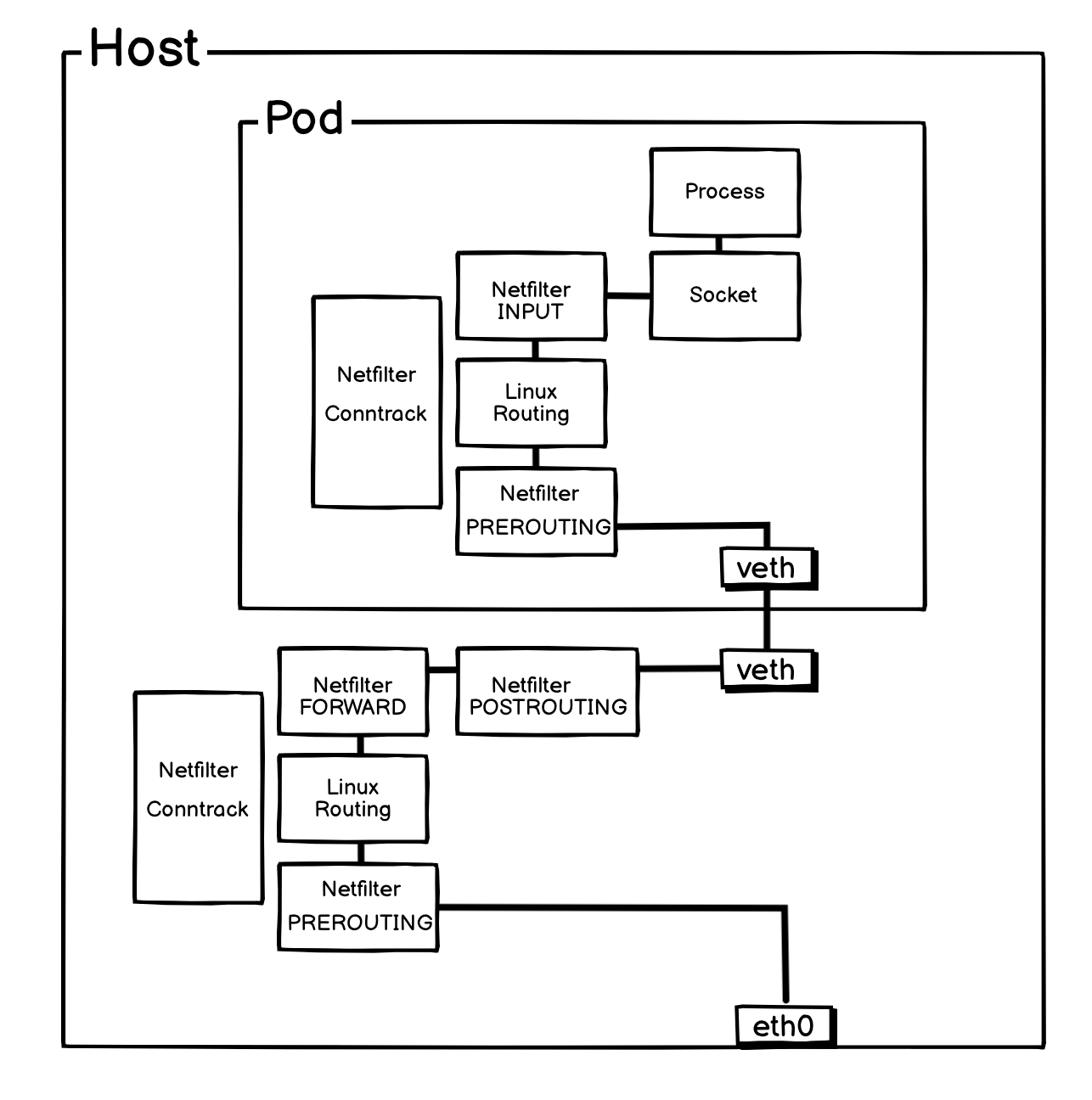
如果上图所示,流量从外部进入后,会先进入宿主机的 Netfilter 框架,然后由内核根据路由表,转给 cni0 网桥,或者 pod 的 veth-pair 网卡,最后到达 Pod,Pod 再自身还会经过自己的网络协议栈。这样就造成了资源的浪费,因为在报文的转发流程上,Netfilter 是非常消耗资源的。
Cilium 利用 eBPF 做了什么路径优化呢?
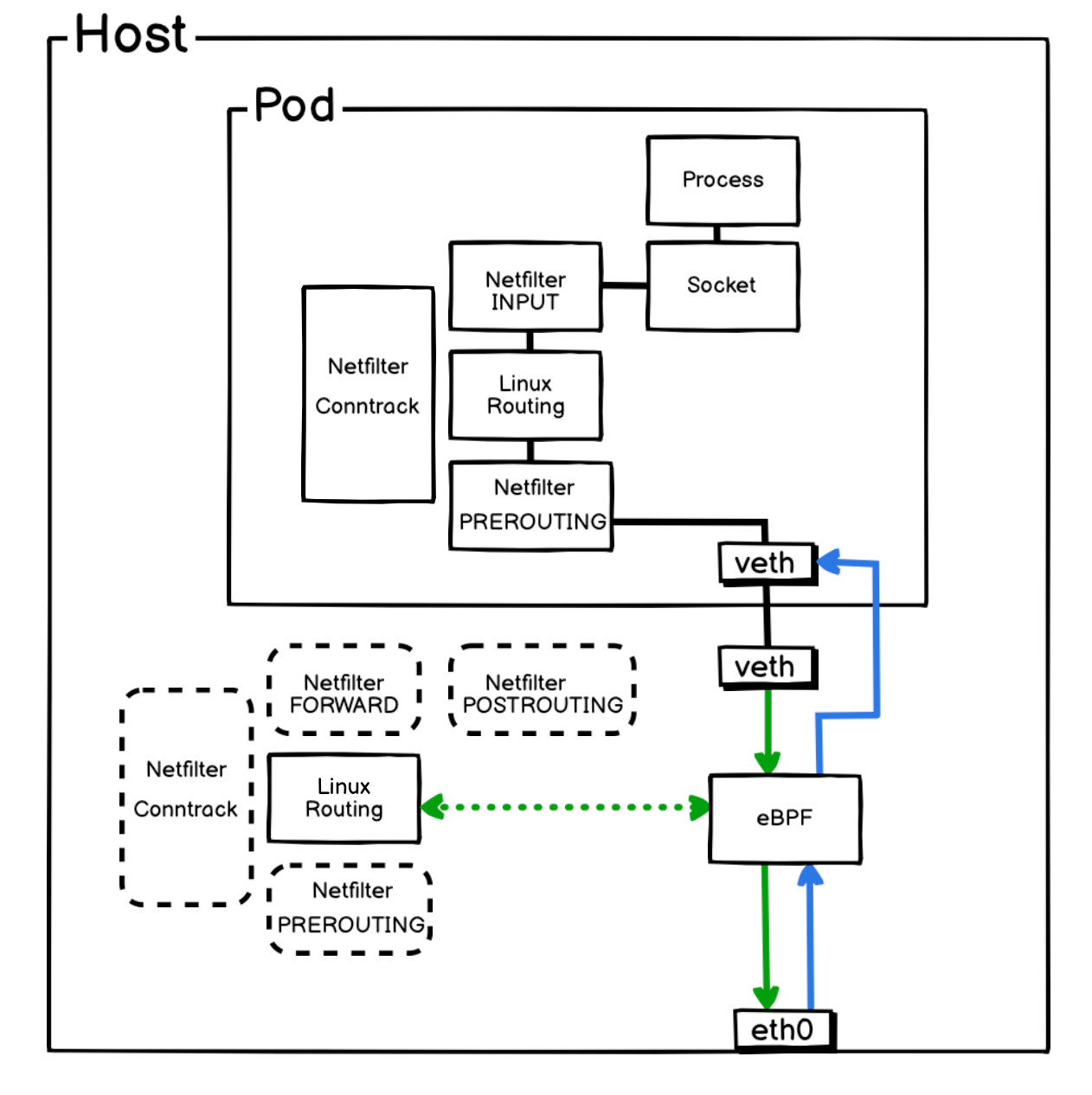
如上图所示:
- 入向流量:外部报文抵达主机网卡 (
eth0) 后,会被eth0 TC Ingress Hook上的 eBPF 程序立即捕获,并绕过内核协议栈,直接转发至目标 Pod 的虚拟网卡。 - 出向流量:从 Pod 发出的报文经由
veth-pair到达主机侧,由Pod veth-pair 网卡 TC Ingress Hook上的 eBPF 程序处理。该程序会自主查询路由信息,然后将报文直接转发至主机网卡 (eth0)。
通过该路径,Cilium 完全绕过了宿主机的 Netfilter 框架,显著提升了 Pod 网络的报文转发效率。
报文是如何被 eBPF 程序接管的?
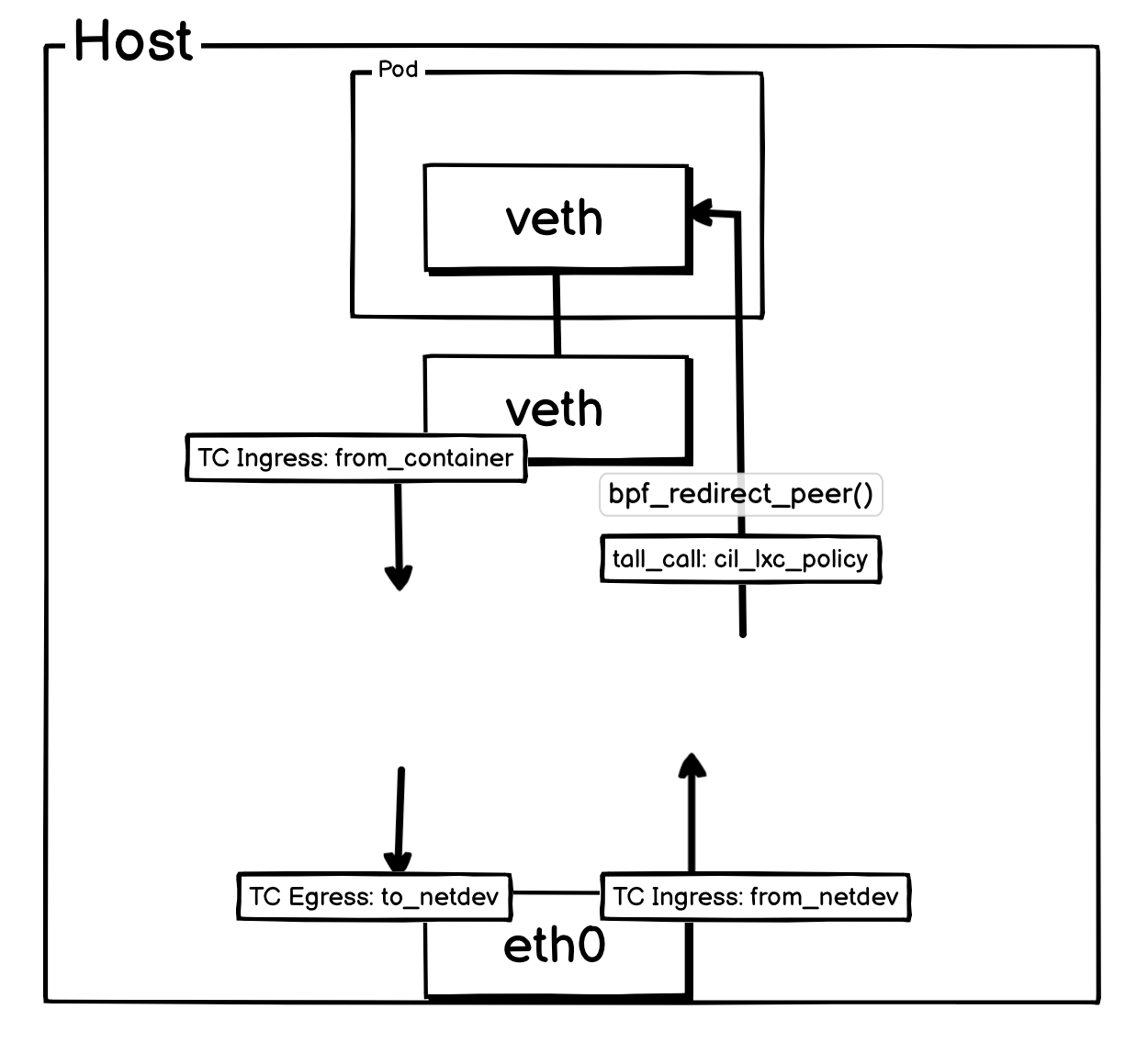
上面中 Cilium 实现跳过宿主机的 Netfilter ,核心是利用了图片上的两个 eBPF 程序。
from_container:- 处理方向: 处理所有从 Pod 出来的报文
- 挂载点: Pod
veth-pair网卡对宿主机端网卡的TC Ingress Hook - 核心职责:负责执行出口策略、进行服务负载均衡 (ClusterIP)、判断目标并高效地将数据包路由或重定向到最终目的地。
from_netdev:- 处理方向: 处理从外部进入宿主机的流量。
- 挂载点:物理网卡的
TC Ingress Hook - 核心职责: 负责 IPsec 解密、NodePort 服务处理、入口方向的主机防火墙策略,并对流量进行初步分发(是送往本地 Pod、宿主机本身,还是需要其他处理),在分发前,还会根据网络策略判断报文是否应该 DROP。
特殊 eBPF 程序:
cil_lxc_policy:- 处理方向: 进入 Pod 的流量。
- 被调用方式: 其他 Hook 在将报文准备发送给 Pod 前,就会调用对应 Pod 的
cil_lxc_policy,将报文全部交由cil_lxc_policy处理。 - 核心职责: 校验报文是否应该被放行,如果可以被放行,最后会通过
bpf_redirect_peer()传输到 Pod 内部的 veth 网卡。
图片上还有一个 Egress Hook,相对来说就不是那么重要了,也不会对 Cilium 的 eBPF 数据路径产生影响。
to_netdev:- 处理方向:处理从宿主机发出,即将进入外部网络的流量。
- 挂载点:物理网卡的
TC Egress hook。 - 核心职责:它是流量离开节点的最后一道关卡,主要为某些流量(如 NodePort)执行 SNAT,还有出口方向的主机防火墙策略、Egress Gateway、带宽管理、IPsec/WireGuard 加密。
TC Ingress Hook 上 eBPF 转发报文有两个核心的内核调用函数:
bpf_redirect_peer(): 专门为veth-pair做的 redirect 函数,可以将报文直接塞给veth-pair网卡对的对端,在这里体现出来的就是,报文被直接转给了 Pod 网络名称空间的 veth 网卡,专用与和 Pod 相关的报文的转发。Kernel 5.10开始支持,之前只有bpf_redirect,报文只能到当前namepsace的veth-pair网卡。- 解决“如何进出容器”的问题,追求的是极致的效率。
bpf_redirect_neigh(): 用于需要进行三层(IP)路由决策的转发,主要负责将数据包从主机正确地路由到外部网络或其他节点,这个过程会查询宿主机内核的路由表。- 解决了“如何离开主机”的问题,追求的是与内核协议栈的兼容与正确性。
三、数据路径
1. Pod 出宿主机
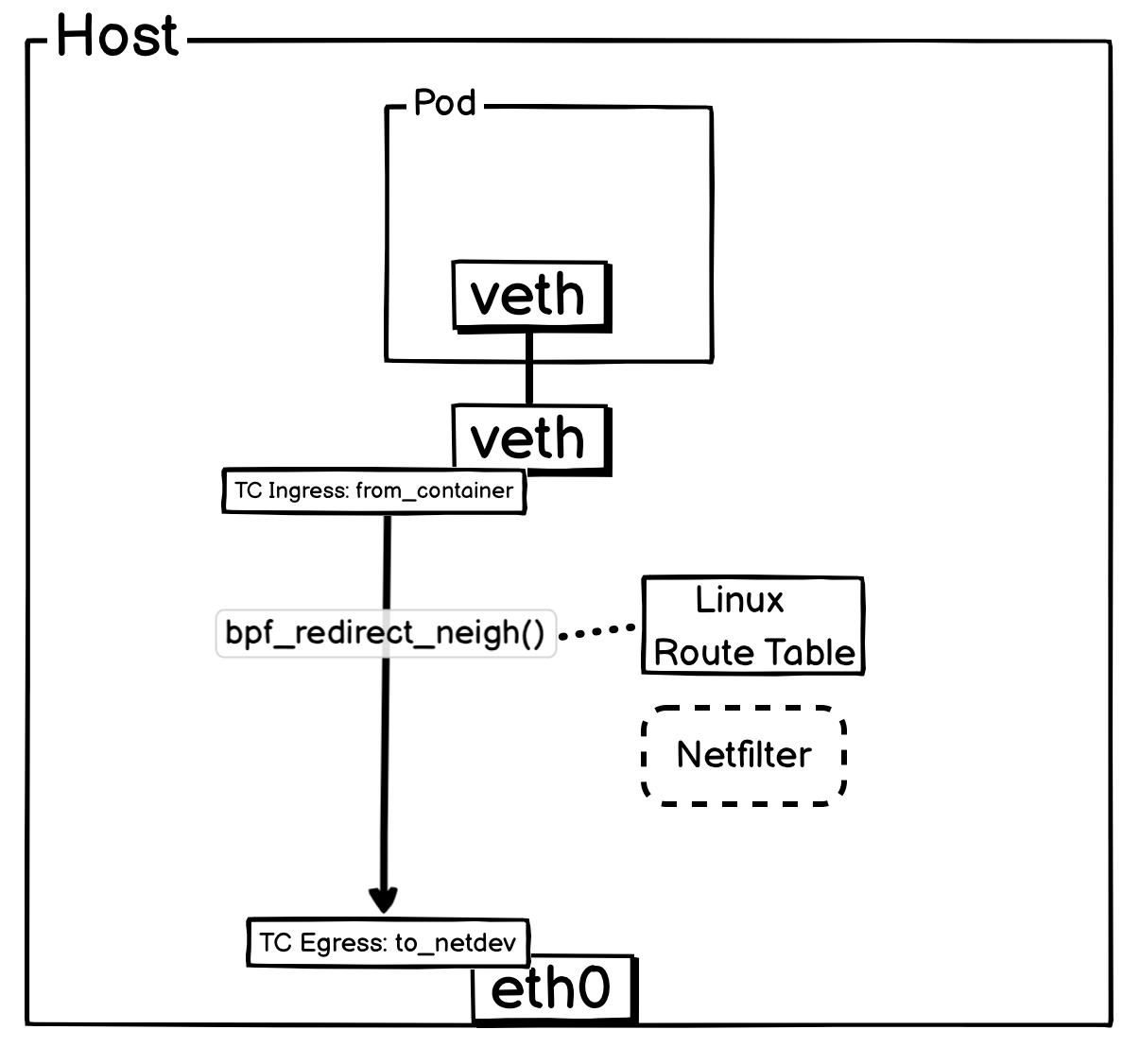
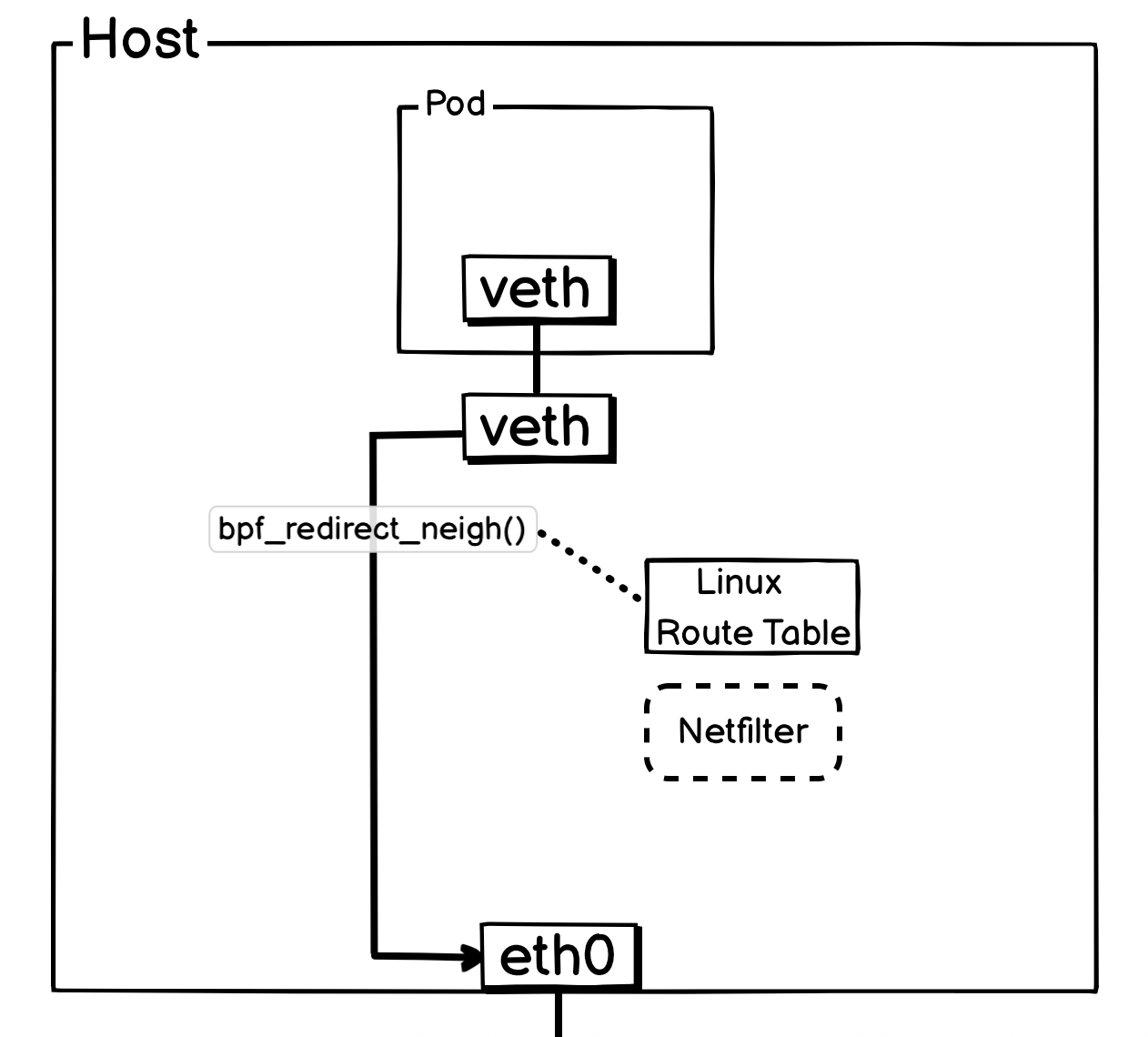
所有 Pod 出流量都会通过 Pod 所在 veth-paic 宿主机测挂载的 TC Ingress Hook 上的 from_container 接管并处理。如果是发往其他宿主机的流量,将会通过 bpf_redirect_neigh()函数,查询宿主机的路由表信息。最终将报文通过物理网卡转出,其中有关于 SNAT 相关工作,会通过eth0上面的 TC Ingress to_netdev完成。
简化后方便理解的网络流转图:
2. 外部流量进入 Pod
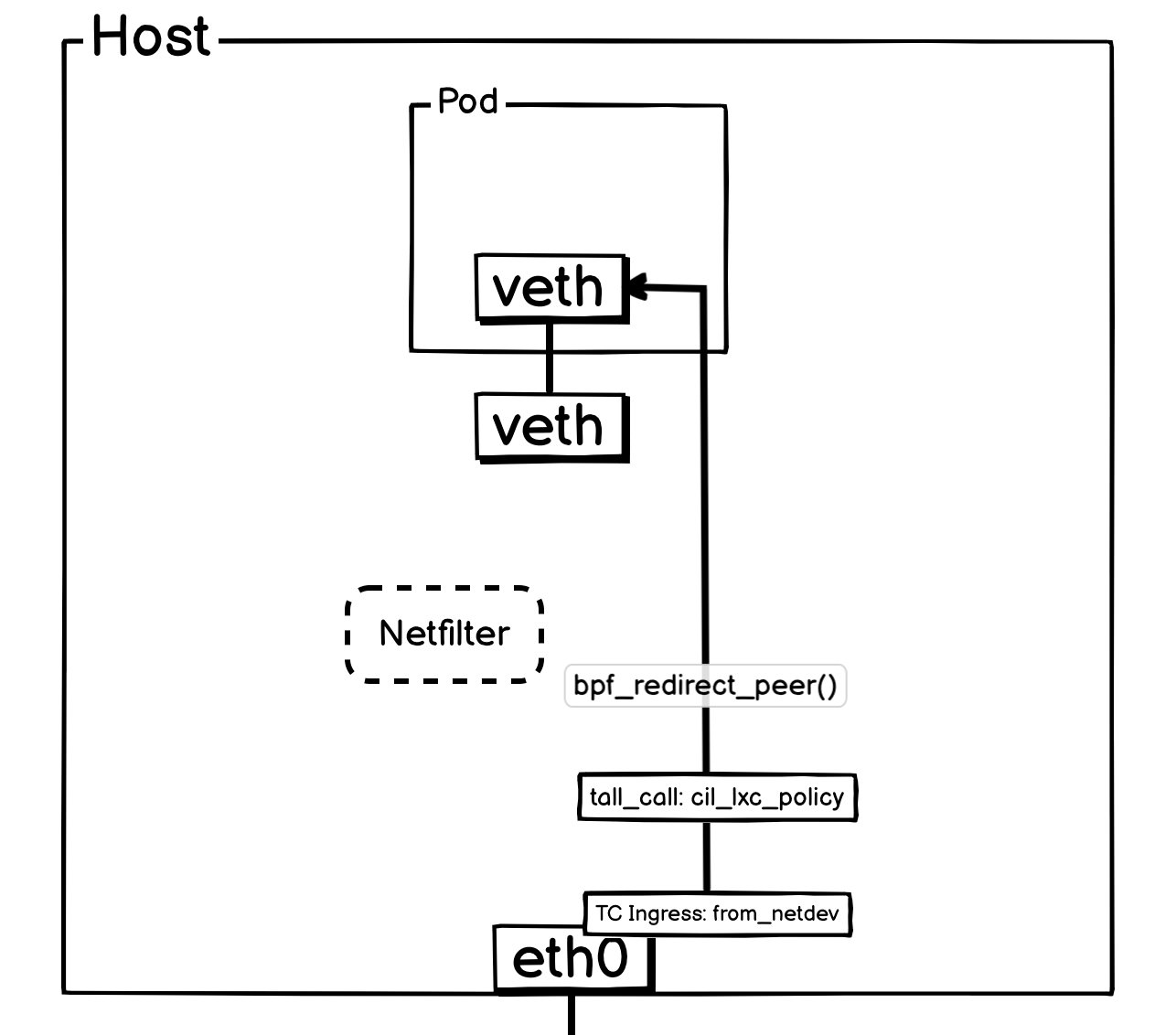
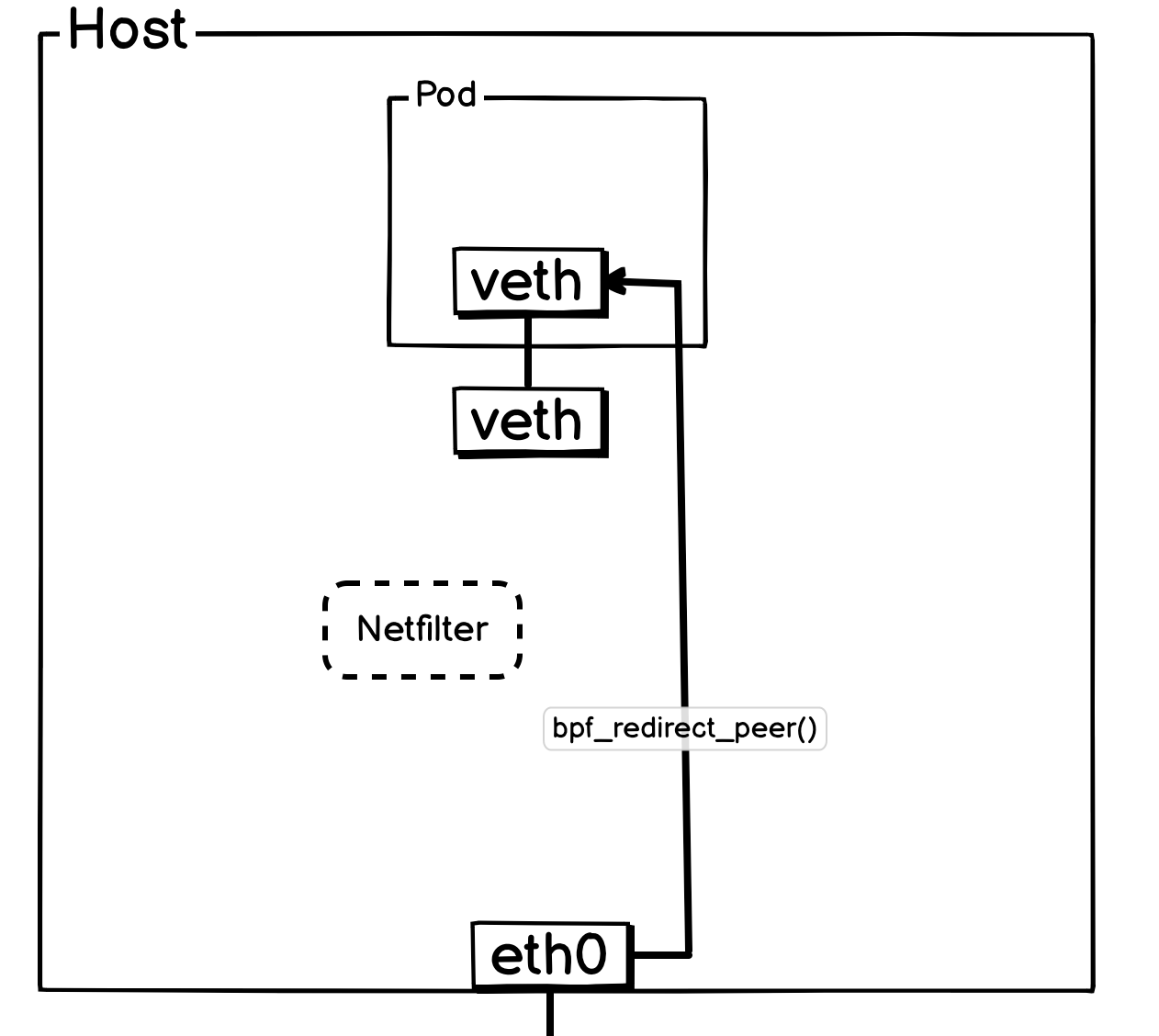
而外部流量进入 Pod,会通过宿主机网卡TC Ingress Hook上面挂载的from_netdev进行处理,在这里实现连接追踪等功能。如果是 Pod 的报文,会通过指定endpoint信息,尾调对应 Pod 的 cil_lxc_policy函数。将所有逻辑都交由cil_lxc_policy处理。
cil_lxc_policy在收到报文会,会进行策略判断是否放行,最终Drop或者使用bpf_redirect_peer()将报文转给 Pod 网络名称空间的的 veth 网卡。
简化后方便理解的网络流转图:
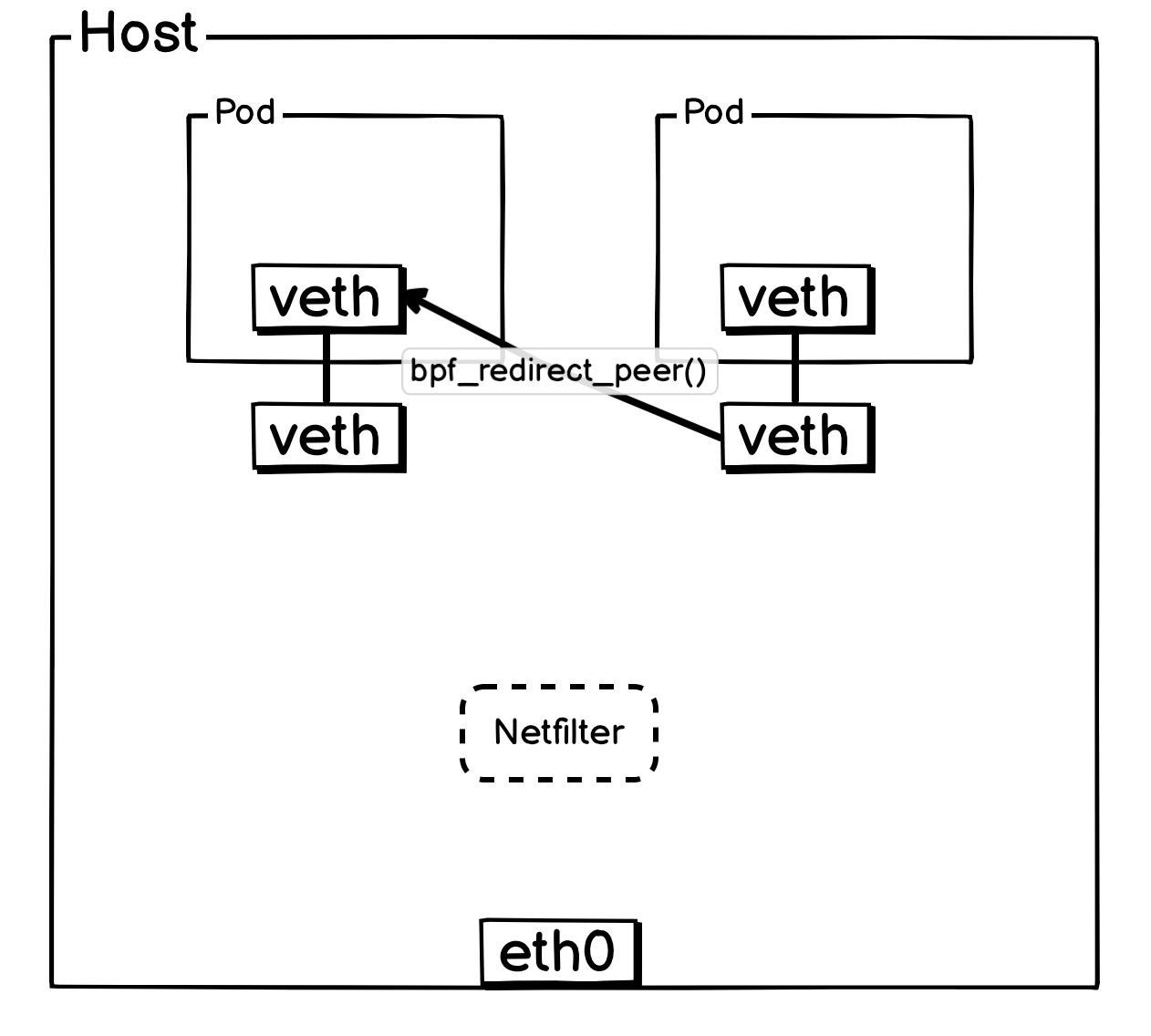
3. 同宿主机 Pod 与 Pod 通信
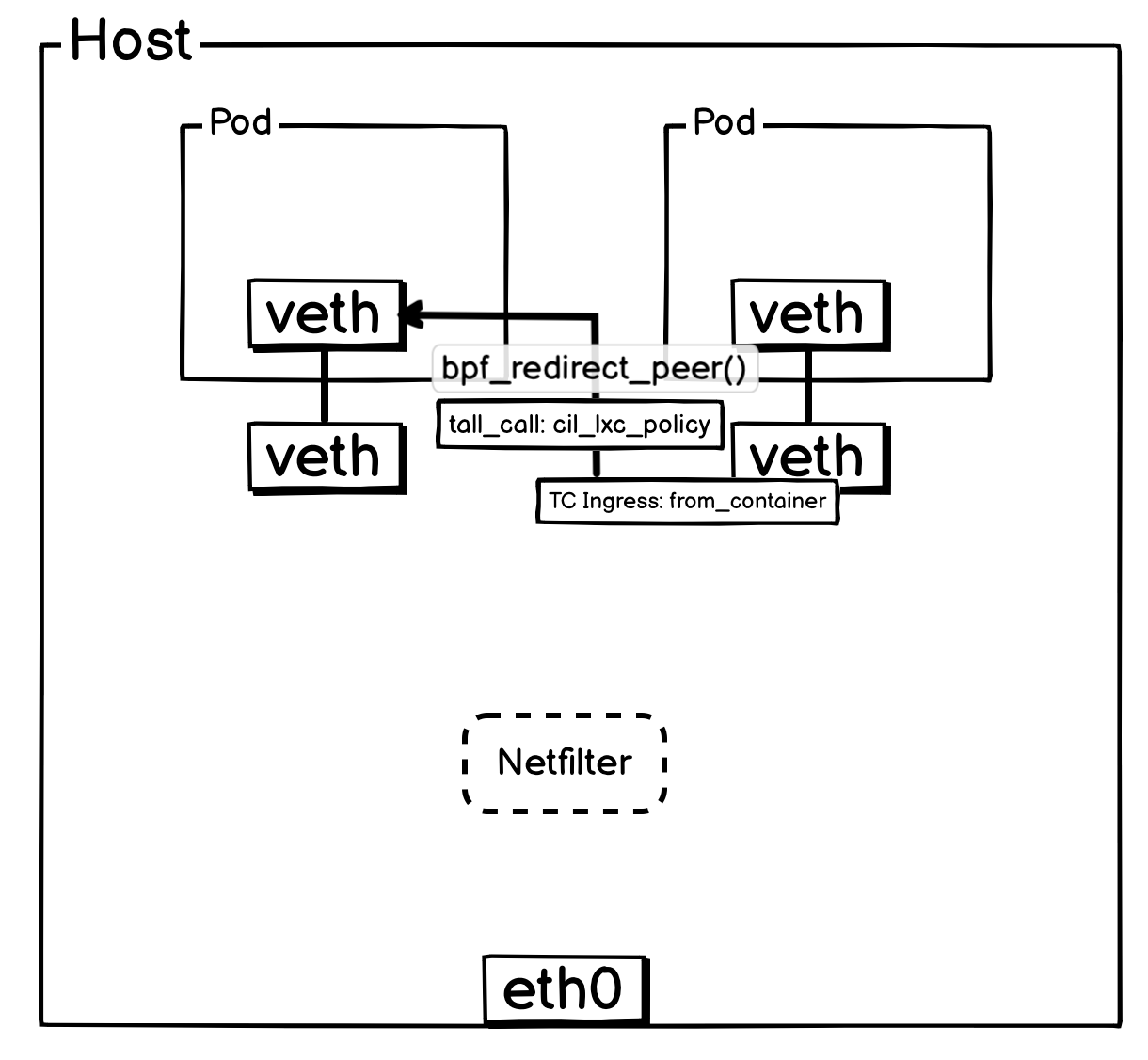
当报文离开 Pod 后,会立即由其所在宿主机上的 veth-pair 网卡进行处理,具体由 from_container 这个 eBPF 程序接管。
判断如果是同宿主机 Pod ,会通过尾调调用 ipv4_local_delivery 函数,而 ipv4_local_delivery 就负责同宿主机 Pod 报文的投递,ipv4_local_delivery 后续会通过尾调调用目标 Pod 的 cil_lxc_policy 的 eBPF 程序,目标 Pod 的 cil_lxc_policy 经过策略判断后是否放行后,会调用 bpf_redirect_peer() 将报文转发到目标 Pod 内部 veth 网卡。
简化后方便理解的网络流转图:
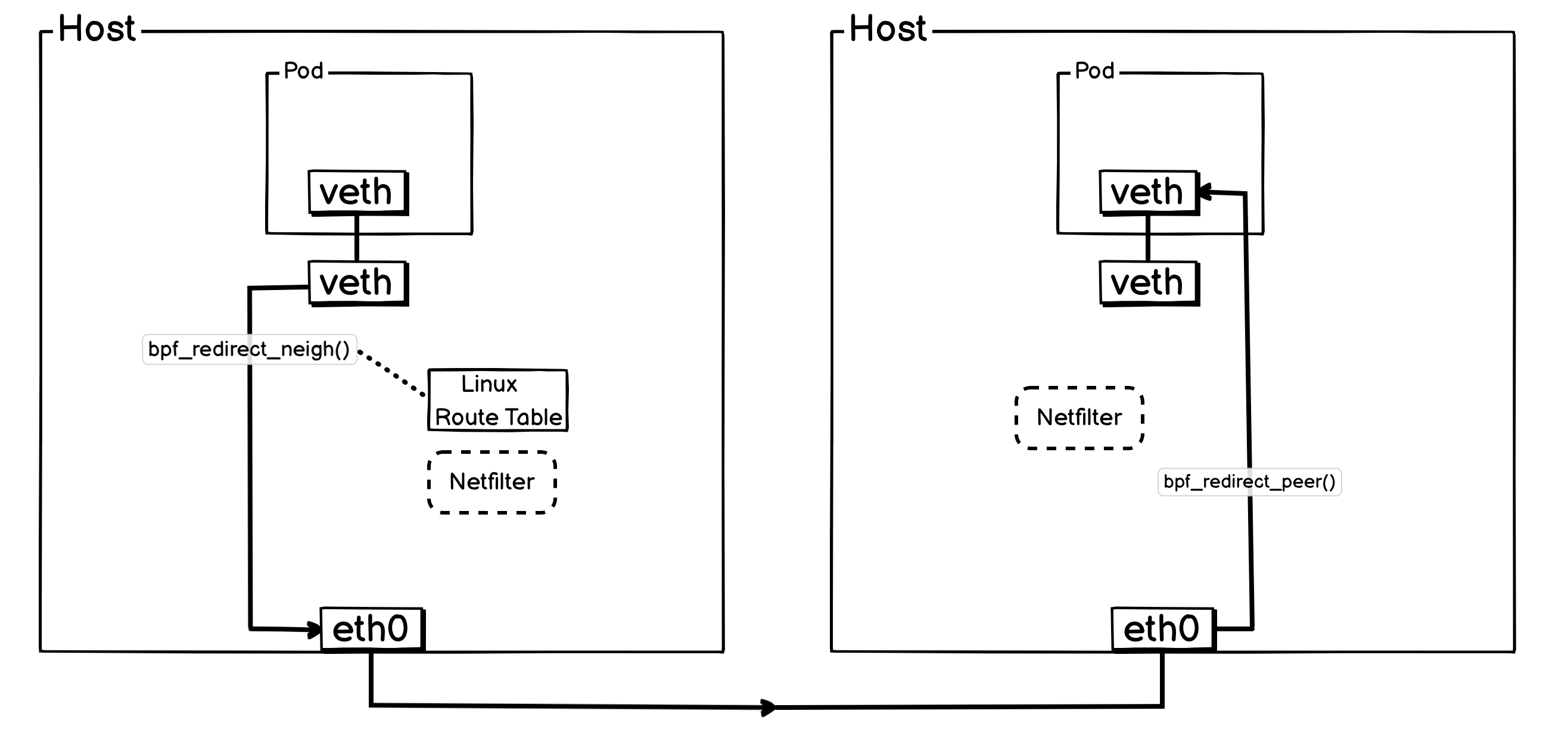
4. Pod 与 Pod 跨宿主机通信
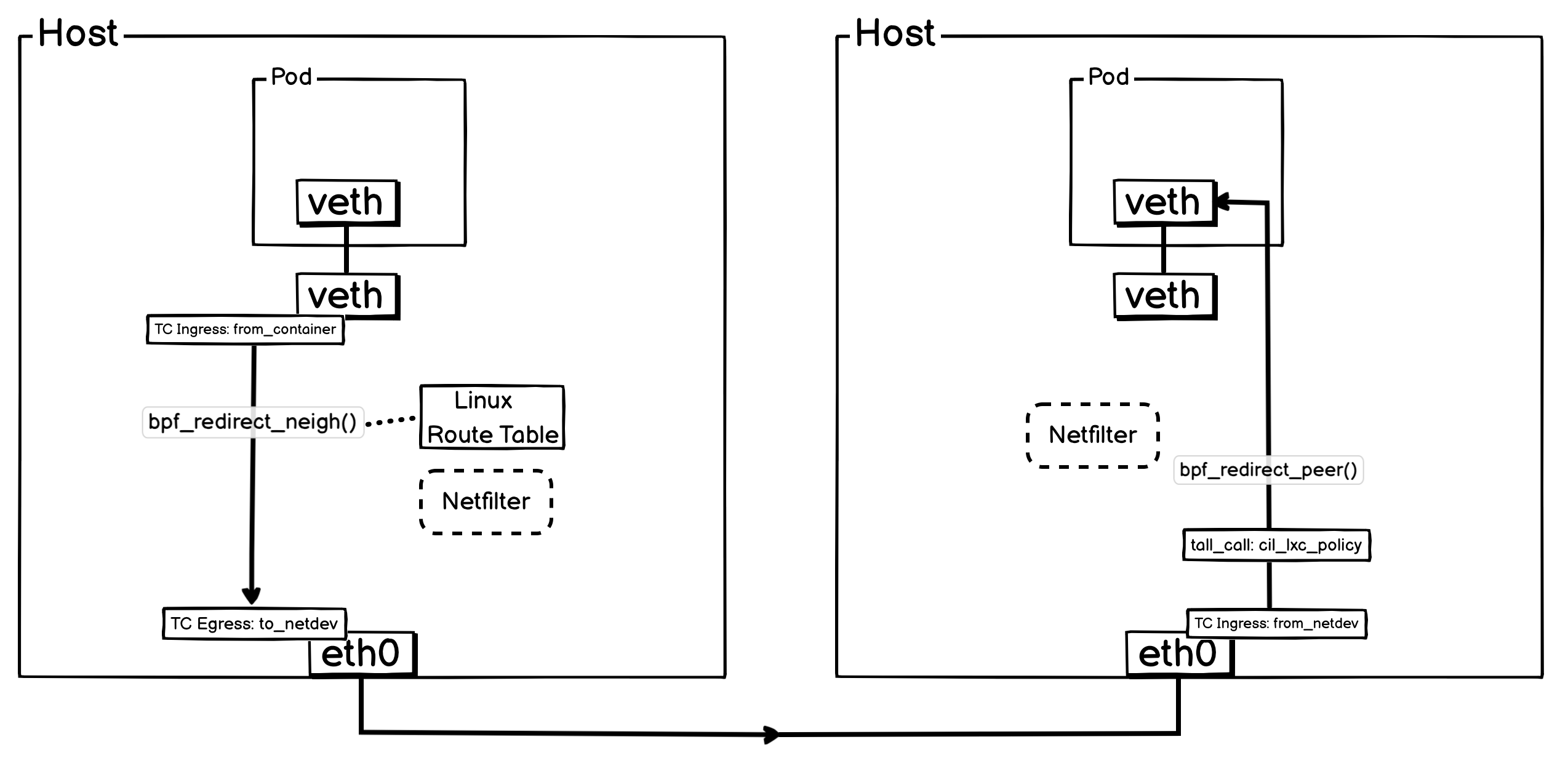
Pod 跨通信的时候,其实就是 Pod 出入宿主机通信的组合,Pod 先通过bpf_redirect_neigh()跳过本机 Netfilter ,然后从 eth0 转出去,最终在到达对端宿主机后,被bpf_redirect_peer()直接转给目标 Pod 。
简化后方便理解的网络流转图:
四、性能提升情况
根据isovalent的给出的测试数据:
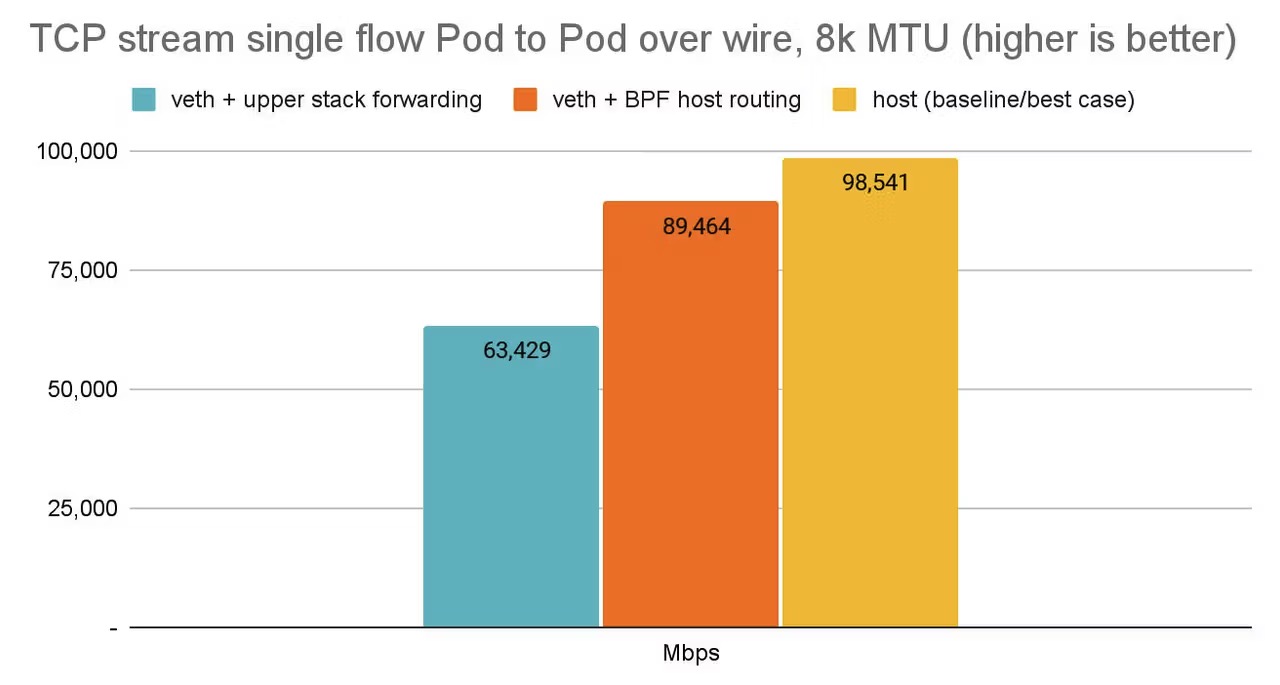
- veth + upper stack forwarding: 传统方案,通过内核网络协议栈和 Netfilter 进行路由和报文转发。
- veth + BPF host routing: 使用 eBPF 跳过 Netfilter,文中所使用的模式。
- host: 宿主机原生网络最佳情况。
传统方案与物理机原生性能差距巨大(约36%的损耗),而 eBPF 方案将这个差距显著缩小到了仅有约 9%,是传统方法性能的 1.41 倍。这意味着在容器中运行的应用几乎可以获得与直接在物理机上运行相媲美的网络性能。
当然,isovalent 毕竟是 Cilium的商业化公司,不能尽信,真想要获取Cilium的性能提升,还是要自己对其进行详尽的性能测试。
题外话1: 这里为什么会特意标注 veth 呢?veth-pair 不是容器网络构建的标准方案吗?为什么还需要写出来呢?
其实又出了一个新东西,在Cilium的支持下,能把性能提升至和宿主机几乎同一个层次,不过版本要求较高,对于Cilium本身,1.16就开始支持了,但是对于 Linux 内核来说,要 Linux Kernel 6.7 版本才支持。
这个东西叫netkit,给的数据说比veth-pair提升了 12% 的性能。也是非常恐怖的性能提升。
题外话2: 其实 HostNetwork 也是一种很好的方式。
如果现在使用的 Flannel 或者 Calico,在完全不动网络架构的情况下,不管是 Pod 网络是 Overlay 还是Underlay,都可以直接将超高网络需求的 workload 设置为 HostNetwork 模式,不要以为这种方式不优雅,不少大厂都这么干,简单直接的性能提升方式。(当然,用之前先规划清楚是否有安全方面或者端口方面、以及服务注册方面的内容需要注意。)
结束语
综上所述,Cilium 借助 eBPF 技术在 Linux 内核中构建了一条高效的数据路径,这是其实现高性能网络的基础。对于在生产环境中部署和维护 Cilium 而言,深入理解原生路由模式下的报文转发细节并非可有可无,而是保障系统稳定、实现快速故障定位的关键。掌握其核心原理,是充分发挥云原生网络优势的必要前提。