Kubernetes 网络是其体系中公认的复杂部分,尤其 CNI 更是让许多工程师望而却步。尽管我们日常使用 Calico、Flannel 等 CNI 插件,但其底层工作原理却常常不甚明了。许多人满足于“能用即可”,但作为工程师,若不理解底层机制,在排查网络问题时便会束手无策。实际上,抛开复杂的控制平面,数据平面的核心原理可归结为几种固定的实现模式。本文旨在揭示这些底层技术,不谈抽象理论,而是通过手动实践,复现 Host-GW、VXLAN 和 IPIP 这三种经典的数据平面模型,展示其背后由哪些基础的 Linux 网络功能所支撑。
基础知识:容器基础通信原理 veth pair 和 bridge
一、Host-GW
Host-GW 是一种简洁而强大的网络模型,它通过基础的路由转发功能即可构建出高效容器网络。该模型不仅性能出色,而且架构清晰、易于排查故障。因此,对于网络环境简单且无特殊需求的场景,Host-GW 是实现容器网络的理想选择。
先上配置:
#!/bin/bash
set -v
sudo clab destroy -t clab.yaml --cleanup
brctl addbr switch
ip link set switch up
cat <<EOF > clab.yaml && clab deploy -t clab.yaml
name: host-gw-lab
topology:
nodes:
# 模拟连接所有主机的二层交换机 (底层网络)
switch:
kind: bridge
host1:
kind: linux
image: nicolaka/netshoot
network-mode: none
exec:
- sysctl -w net.ipv4.ip_forward=1
- ip addr add 192.168.0.100/24 dev eth1
- ip link set eth1 up
# 设置 Pod 连接宿主机的网桥
- brctl addbr cni0
- ip addr add 10.0.1.1/24 dev cni0
- ip link set cni0 up
# 把 Pod 的 vveth-pair-pair 网卡挂载到 cni0 上。
- ip link set pod1-veth-pair master cni0
- ip link set pod1-veth-pair up
# host-gw 核心路由: 告诉 host1 如何到达 host2 上的 Pod 网络
- ip route add 10.0.2.0/24 via 192.168.0.200
# NAT 规则, 用于 Pod 访问外部网络 (可选)
- iptables -t nat -A POSTROUTING -s 10.0.0.0/16 ! -d 10.0.0.0/16 -j MASQUERADE
pod1:
kind: linux
image: nicolaka/netshoot
network-mode: none
exec:
# Pod 自己的 IP
- ip addr add 10.0.1.2/24 dev eth1
- ip link set eth1 up
# 将默认网关指向其宿主 host1
- ip route replace default via 10.0.1.1
host2:
kind: linux
image: nicolaka/netshoot
network-mode: none
exec:
- sysctl -w net.ipv4.ip_forward=1
- ip addr add 192.168.0.200/24 dev eth1
- ip link set eth1 up
# 设置 Pod 连接宿主机的网桥
- brctl addbr cni0
- ip addr add 10.0.2.1/24 dev cni0
- ip link set cni0 up
# 把 Pod 的 vveth-pair-pair 网卡挂载到 cni0 上。
- ip link set pod2-veth-pair master cni0
- ip link set pod2-veth-pair up
# host-gw 核心路由: 告诉 host1 如何到达 host2 上的 Pod 网络
- ip route add 10.0.1.0/24 via 192.168.0.100
# NAT 规则, 用于 Pod 访问外部网络 (可选)
- iptables -t nat -A POSTROUTING -s 10.0.0.0/16 ! -d 10.0.0.0/16 -j MASQUERADE
pod2:
kind: linux
image: nicolaka/netshoot
network-mode: none
exec:
- ip addr add 10.0.2.2/24 dev eth1
- ip link set eth1 up
# 将默认网关指向其宿主 host2
- ip route replace default via 10.0.2.1
links:
# 将 host1 和 host2 连接到交换机上
- endpoints: ["host1:eth1", "switch:eth1"]
- endpoints: ["host2:eth1", "switch:veth-pair2"]
# 将 pod 连接到 host
- endpoints: ["host1:pod1-veth-pair", "pod1:eth1"]
- endpoints: ["host2:pod2-veth-pair", "pod2:eth1"]
EOF
sudo clab deploy -t clab.yaml
上面拓扑图如下所示:
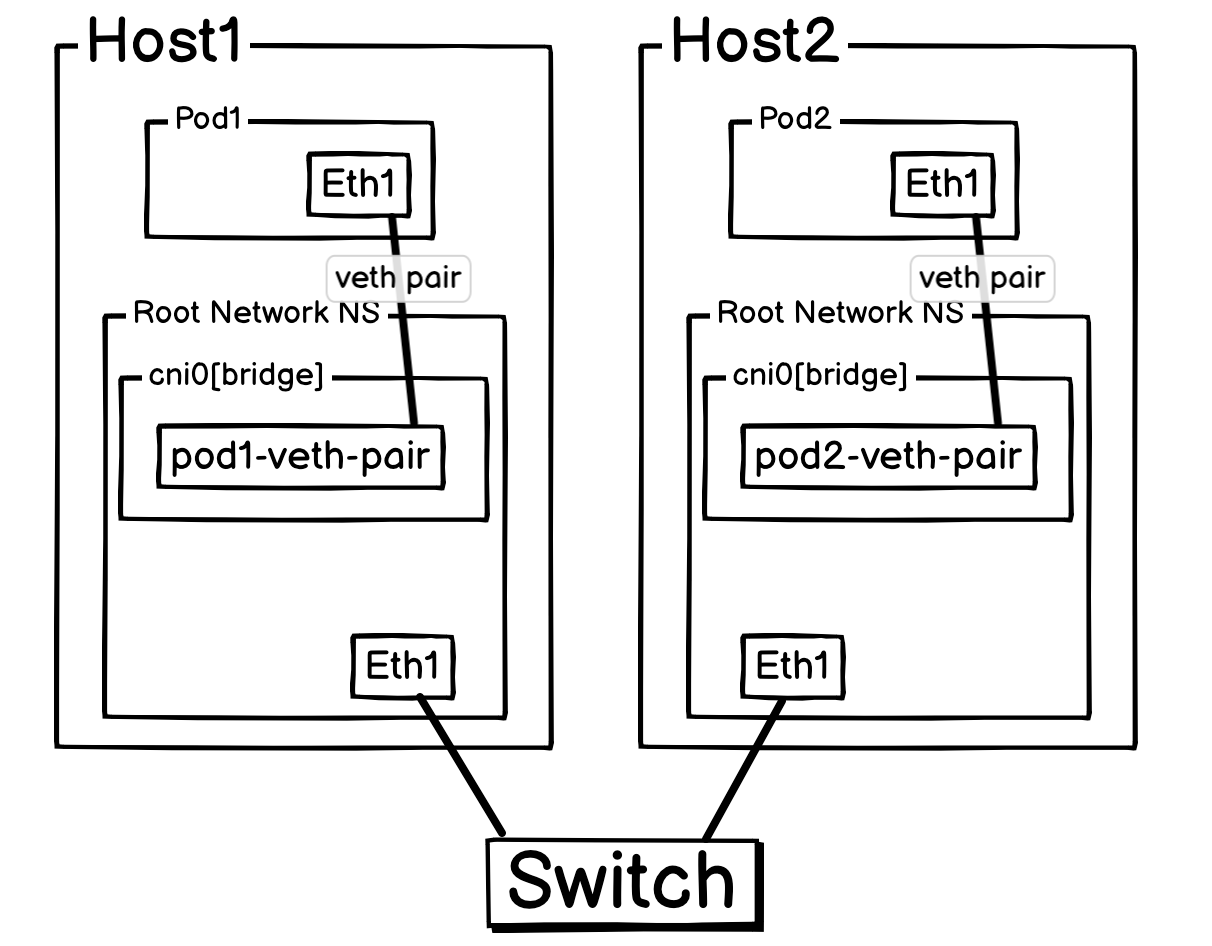
这里将想象 Pod1 是运行在 Host1 中的。
当 Pod1 想把一个报文发送给 Pod2 的时候(架构很简单,就不提及二层交换了。):
-
pod1(IP:10.0.1.2) 要找pod2(IP:10.0.2.2),发现其网段不同,所以Pod1报文发送给了网关cni0。- 报文到达
cni0后,Host1收到报文,由于开启了net.ipv4.ip_forward,所以Host1会根据路由表把报文转出去。 - 查看路由表后,
Host1直接将报文转发给了Host2,整个过程源 IP 依旧是Pod1 IP,目标 IP 依旧是Pod2IP,因为Host1上路由ip route add 10.0.2.0/24 via 192.168.2.100指明了对应报文应该送给Host2。 - 报文到达
Host2之后,发现有一条路由把Host的目标指向了cni0(命令ip addr add 10.0.2.1/24 dev cni0会默认增加一个route 10.0.2.0/24 dev cni0的路由),所以就把报文通过cni0转给了Pod2。 Pod2回报文的时候也会经过同样的规则。
至此,一次完整的通信就成功了。这个流程完美地展示了 Host-GW 模型如何利用主机本身的三层路由能力来实现跨主机容器通信,无需任何 Overlay 封装(如 VXLAN),因此性能非常高。
Pod1 Ping Pod2 时,Host2 eth1 抓包情况:
host2:~# tcpdump -pne -i eth1
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on eth1, link-type EN10MB (Ethernet), snapshot length 262144 bytes
17:22:03.610097 aa:c1:ab:f7:d2:17 > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 192.168.0.200 tell 192.168.0.100, length 28
17:22:03.610127 aa:c1:ab:ea:fe:2e > aa:c1:ab:f7:d2:17, ethertype ARP (0x0806), length 42: Reply 192.168.0.200 is-at aa:c1:ab:ea:fe:2e, length 28
17:22:03.610193 aa:c1:ab:f7:d2:17 > aa:c1:ab:ea:fe:2e, ethertype IPv4 (0x0800), length 98: 10.0.1.2 > 10.0.2.2: ICMP echo request, id 225, seq 1, length 64
17:22:03.610265 aa:c1:ab:ea:fe:2e > aa:c1:ab:f7:d2:17, ethertype IPv4 (0x0800), length 98: 10.0.2.2 > 10.0.1.2: ICMP echo reply, id 225, seq 1, length 64
可以看到报文是 Pod1 IP -> Pod2 IP 直接送到了 Host2 上面。
总而言之,如果是构建一个稳定、高速且易于理解和管理的容器网络,那么 Host-GW 凭借其无封装、无额外组件的原生路由方式,无疑是优先考虑的高性价比之选。
尽管 Host-GW 模型高效简洁,但其优点也带来了最主要的局限性:它强依赖于一个扁平的二层(L2)网络环境,要求所有集群节点都位于同一广播域内。
问题根源:
一旦网络拓扑中出现三层(L3)路由器来隔离节点,标准的 Host-GW 模型便会失效。这是因为中间的路由器仅拥有主机网络的路由信息(例如 192.168.0.0/24),而对各主机内部的 Pod 网络(例如 10.0.1.0/24)一无所知。当它收到一个目标地址为 Pod IP 的数据包时,会因缺少路由而无法转发。
潜在解决方案:
虽然存在一些技术手段可以“打通”这种三层壁垒,但这通常意味着引入了更高的复杂性:
- 动态路由学习:例如,借助 Calico 的 BGP 模式,可以让节点将 Pod 路由动态地通告给物理路由器,使路由器能够学习到这些路由。
- 静态路由配置:在极端情况下,也可以通过自定义控制器从 Kubernetes API Server 同步各节点的 PodCIDR,并将其转换成静态路由配置到网络设备上。
最终建议 :
上述方案已超出了 Host-GW 模型本身的设计范畴。因此,在规划网络时,如果已预见到必须跨越多个路由域进行通信,更稳妥的选择是采用原生支持三层网络的方案,例如基于 VXLAN 的 Overlay 网络,或是能够结合 Host-GW 和 VXLAN 的混合模式。
二、VXLAN
如果说 Host-GW 是在平坦开阔的高速公路上开车,那么 VXLAN 就是把整辆车开进一个集装箱,通过货运铁路送到目的地。
实验配置:
#!/bin/bash
set -v
sudo clab destroy -t clab.yaml --cleanup
cat <<EOF> clab.yaml | clab deploy -t clab.yaml -
name: flannel-VXLAN
topology:
nodes:
gw1:
kind: linux
image: nicolaka/netshoot
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=1
- sysctl -w net.ipv6.conf.default.disable_ipv6=1
- sysctl -w net.ipv6.conf.lo.disable_ipv6=1
- sysctl -w net.ipv4.ip_forward=1
- ip addr add 192.168.0.100/24 dev eth1
- ip link set eth1 up
- ip addr add 10.0.1.1/24 dev eth2
- ip link set eth2 up
- ip route add 10.0.2.0/24 via 192.168.0.200
host1:
kind: linux
image: nicolaka/netshoot
network-mode: none
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=1
- sysctl -w net.ipv6.conf.default.disable_ipv6=1
- sysctl -w net.ipv6.conf.lo.disable_ipv6=1
# 1. 在宿主机上开启IP转发。
#- sysctl -w net.ipv4.conf.all.proxy_arp=1
- sysctl -w net.ipv4.ip_forward=1
- ip addr add 10.0.1.2/24 dev eth1
- ip link set eth1 up
- ip route replace default via 10.0.1.1 dev eth1
# 2. 设置VXLAN接口。
- ip link add flannel.1 type vxlan id 1 dev eth1 local 10.0.1.2 dstport 4789
- ip link set dev flannel.1 up
# 3. 设置连接本地Pod的网桥。
- brctl addbr cni0
- ip addr add 172.16.0.1/24 dev cni0
- ip link set dev cni0 up
- brctl addif cni0 pod1-veth-paic
- ip link set dev pod1-veth-paic up
# 4. 添加到对端Pod子网的路由。
# 给 flannel.1 增加上 IP 后,下一跳设置为对端 flannel.1 IP 也可行。
#- ip addr add 172.16.0.0/32 dev flannel.1
#- ip route add 172.16.1.0/24 via 172.16.1.0 dev flannel.1 onlink
- ip route add 172.16.1.0/24 via 172.16.1.1 dev flannel.1 onlink
# 5. 添加静态FDB条目,用于引导广播(如初始ARP请求)。
- bridge fdb append to 00:00:00:00:00:00 dst 10.0.2.2 dev flannel.1
pod1:
kind: linux
image: nicolaka/netshoot
network-mode: none
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=1
- sysctl -w net.ipv6.conf.default.disable_ipv6=1
- sysctl -w net.ipv6.conf.lo.disable_ipv6=1
- ip addr add 172.16.0.2/24 dev eth1
- ip link set eth1 up
- ip route replace default via 172.16.0.1 dev eth1
gw2:
kind: linux
image: nicolaka/netshoot
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=1
- sysctl -w net.ipv6.conf.default.disable_ipv6=1
- sysctl -w net.ipv6.conf.lo.disable_ipv6=1
- sysctl -w net.ipv4.ip_forward=1
- ip addr add 192.168.0.200/24 dev eth1
- ip link set eth1 up
- ip addr add 10.0.2.1/24 dev eth2
- ip link set eth2 up
- ip route add 10.0.1.0/24 via 192.168.0.100
host2:
kind: linux
image: nicolaka/netshoot
network-mode: none
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=1
- sysctl -w net.ipv6.conf.default.disable_ipv6=1
- sysctl -w net.ipv6.conf.lo.disable_ipv6=1
# 1. 在宿主机上开启IP转发。
- sysctl -w net.ipv4.ip_forward=1
- ip addr add 10.0.2.2/24 dev eth1
- ip link set eth1 up
- ip route replace default via 10.0.2.1 dev eth1
# 2. 设置VXLAN接口。
- ip link add flannel.1 type vxlan id 1 dev eth1 local 10.0.2.2 dstport 4789
- ip link set dev flannel.1 up
# 3. 设置连接本地Pod的网桥。
- brctl addbr cni0
- ip addr add 172.16.1.1/24 dev cni0
- ip link set dev cni0 up
- brctl addif cni0 pod2-veth-paic
- ip link set dev pod2-veth-paic up
# 4. 添加到对端Pod子网的路由。
#- ip addr add 172.16.1.0/32 dev flannel.1
- ip route add 172.16.0.0/24 via 172.16.0.1 dev flannel.1 onlink
# 5. 添加指向另一台宿主机的静态FDB条目。
- bridge fdb append to 00:00:00:00:00:00 dst 10.0.1.2 dev flannel.1
# 使用组播
# - ip link add flannel.1 type VXLAN id 1 dev eth1 group 239.1.1.1 dstport 4789
pod2:
kind: linux
image: nicolaka/netshoot
network-mode: none
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=1
- sysctl -w net.ipv6.conf.default.disable_ipv6=1
- sysctl -w net.ipv6.conf.lo.disable_ipv6=1
- ip addr add 172.16.1.2/24 dev eth1
- ip link set eth1 up
- ip route replace default via 172.16.1.1 dev eth1
links:
- endpoints: ["gw1:eth1", "gw2:eth1"]
- endpoints: ["gw1:eth2", "host1:eth1"]
- endpoints: ["gw2:eth2", "host2:eth1"]
- endpoints: ["host1:pod1-veth-paic", "pod1:eth1"]
- endpoints: ["host2:pod2-veth-paic", "pod2:eth1"]
EOF
sudo clab deploy -t clab.yaml
- 模拟外部网络/公网网段: 192.168.0.100/16
- 模拟跨机房网段:
- 10.0.0.0/24
- 10.0.1.0/24
- Pod 网段: 172.16.0.0/16
架构图:
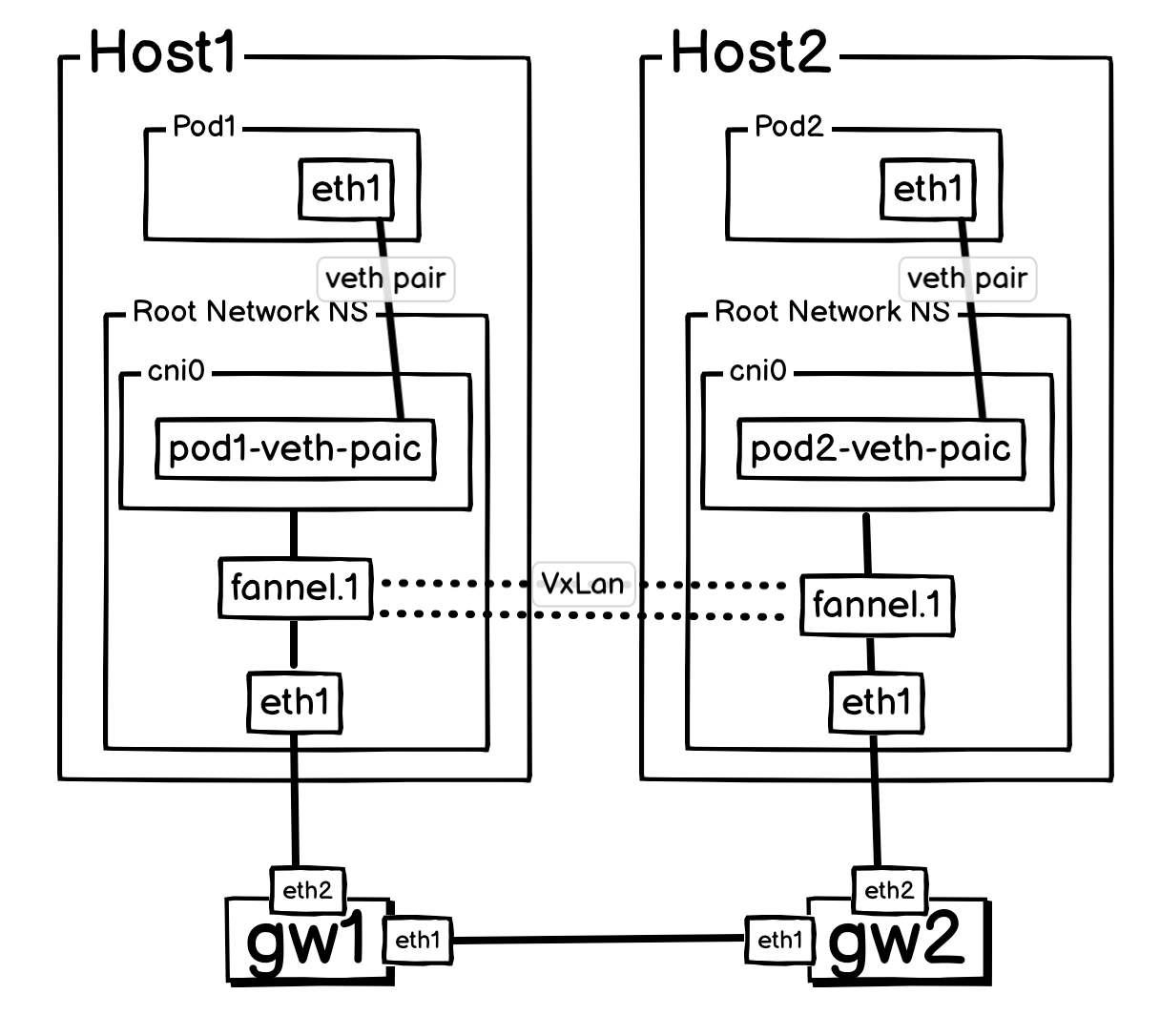
gw 层: 模拟跨路由、跨机房或者跨公网连接。
这个架构下,Pod1 把报文发送给 Pod2 流程:
- 初次请求
Pod1(172.16.0.2) 发出 ICMP 请求包给Pod2(172.16.1.2)。数据包经由cni0网桥进入Host1内核。 - 路由指向隧道
Host1内核查询路由表,发现一条规则(ip route add 172.16.1.0/24 ... dev flannel.1),指示它:要想到达Pod2所在的网络,必须通过flannel.1这个虚拟隧道设备。 - 触发“问路”(ARP 请求) 有网关,有出口设备 (
flannel.1),所以内核生成了一个 ARP 广播请求:“谁能告诉我172.16.1.0这个网关的 MAC 地址?” - 广播的“定向封装” 这个 ARP 广播请求被发往
flannel.1设备。此时,一个预设的关键规则 (bridge fdb append to 00:00:00:00:00:00 dst 10.0.2.2 dev flannel.1) 发挥了作用,它告诉flannel.1设备:“所有广播帧,都不要在本地泛洪,而是将它封装成一个单播 UDP 包,发往Host2(10.0.2.2)”。 - 远端响应
Host2收到 VXLAN 包,解封装后得到内部的 ARP 请求。Host2的内核一看,这个请求查询的172.16.1.1正是自己cni0接口的 IP,于是立刻用自己flannel.1的 MAC 地址进行了应答。 - 学习路径并转发
Host1收到Host2发回的 ARP 应答。 - 正式通信:
Host1将原始的 ICMP 包(源:Pod1, 目标:Pod2),使用刚刚学到的Host2的 MAC 地址进行二层封装,然后将这整个帧再次通过flannel.1设备进行 VXLAN 封装(IP -> UDP -> VXLAN -> IP),再通过正常网络发往Host2。- 封装包情况:
- 外层 MAC(一直变动):
- 源 Mac: Host1 eth1 MAC
- 目标 MAC: Host1 去 Host2 下一跳网关 MAC
- 外层 IP:
- 源 IP: 10.0.1.2 (Host1’s VTEP IP)
- 目标 IP: 10.0.2.2 (Host2’s VTEP IP)
- UDP 封装:
- 源 Port: 随机
- 目标 Port: 4789
- VXLAN 封装, VNI: 1
- 原始数据(Pod 发出,Host1 上封装)
- Mac层: Src MAC: Host1 cni0 MAC, Dst: Host2 cni0 MAC
- IP 层:Src IP: Pod1 IP, Dst: Pod2 IP
- 数据: 应用层数据报文
- 外层 MAC(一直变动):

- 最终送达
Host2解封装后,将原始 ICMP 包通过本地的cni0网桥转发给Pod2,通信成功。 - Pod2 返回: 相同路径返回报文即可。
为了更形象地理解这个过程,我们可以把它想象成一次“驾车乘船”的跨河旅行。
整个通信过程就像这样(上面的1、2、7、8步。):
- 出发上车:
Pod1发出的原始数据包 📖,就像一位乘客坐上了一辆汽车 🚗。 - 抵达码头,开车上船:这辆“汽车”行驶到主机 (
host1) 的网络“码头”(tunnel设备),在这里,整辆车 🚗 被直接开上了一艘巨大的渡轮 🛳️(VXLAN 封装)。这艘渡轮有自己的航行目标——对岸的码头。 - 渡轮过河:渡轮 🛳️ 在广阔的“河流”(物理网络)上航行。河上的航标和灯塔(路由器)只识别渡轮,完全不在意里面装的是什么车。
- 抵达对岸,开车下船:渡轮抵达
host2的码头后,汽车 🚗 从船上开下来(VXLAN 解封装),准备驶向最终目的地。 - 到达终点:汽车 🚗 最终将乘客 📖 安全送达
Pod2。
对于乘客 📖 来说,他只感觉自己一直在车里,根本没有意识到中间经历了“乘船过河”的环节。这正是 VXLAN 的精髓:为 Pod 通信构建无缝的虚拟隧道,完全屏蔽了底层网络的复杂性。
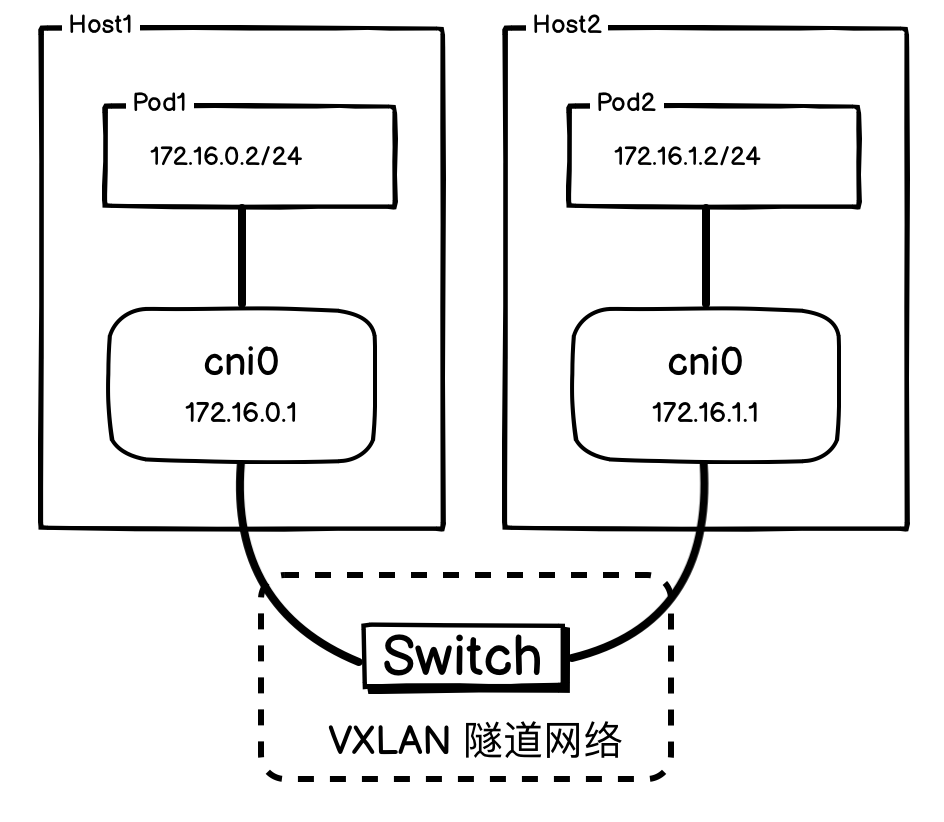
要理解 Kubernetes 中的 VXLAN 网络模型,可从两个层面分析:
-
从 Pod 与 cni0 的视角(应用层):VXLAN 的核心作用是屏蔽底层物理网络的复杂性。它通过封装技术构建出一个扁平化的虚拟二层网络(Overlay),让所有节点上的 Pod 都如同直连在同一个巨型交换机上,从而实现无缝的跨主机通信。
-
从 VTEP 设备的视角(网络层):VXLAN 隧道端点(VTEP)的处理机制非常纯粹,它只负责封装与解封装。
- 封装:将离开本机的报文封装成 VXLAN 格式。
- 解封装:对收到的、VNI 匹配的外部报文进行解封装,然后交由内核处理。
VTEP 并不关心其承载的数据是来自 Pod 还是其他服务。因此,无论是 Pod 之间,还是主机 cni0 网桥之间,都可以利用这条隧道正常通信。
具体通信时候报文情况
Pod1 Ping Pod2 时,Host2 eth1 抓包情况:
host2:~# tcpdump -pne -i eth1
# Underlay 网络建立通信
17:28:27.281580 aa:c1:ab:fb:b2:32 > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 10.0.2.2 tell 10.0.2.1, length 28
17:28:27.281596 aa:c1:ab:3f:9e:a2 > aa:c1:ab:fb:b2:32, ethertype ARP (0x0806), length 42: Reply 10.0.2.2 is-at aa:c1:ab:3f:9e:a2, length 28
# VXLAN 封装的广播请求。(实际上是单播)
17:28:27.281600 aa:c1:ab:fb:b2:32 > aa:c1:ab:3f:9e:a2, ethertype IPv4 (0x0800), length 92: 10.0.1.2.52326 > 10.0.2.2.4789: VXLAN, flags [I] (0x08), vni 1
92:2a:0a:03:e0:d5 > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 172.16.1.0 tell 172.16.0.0, length 28
17:28:27.281646 aa:c1:ab:3f:9e:a2 > aa:c1:ab:fb:b2:32, ethertype IPv4 (0x0800), length 92: 10.0.2.2.52326 > 10.0.1.2.4789: VXLAN, flags [I] (0x08), vni 1
da:9d:2a:11:e4:fc > 92:2a:0a:03:e0:d5, ethertype ARP (0x0806), length 42: Reply 172.16.1.0 is-at da:9d:2a:11:e4:fc, length 28
# VXLAN 封装真正的 ICMP 报文。
17:28:27.281704 aa:c1:ab:fb:b2:32 > aa:c1:ab:3f:9e:a2, ethertype IPv4 (0x0800), length 148: 10.0.1.2.55235 > 10.0.2.2.4789: VXLAN, flags [I] (0x08), vni 1
92:2a:0a:03:e0:d5 > da:9d:2a:11:e4:fc, ethertype IPv4 (0x0800), length 98: 172.16.0.2 > 172.16.1.2: ICMP echo request, id 226, seq 1, length 64
17:28:27.281773 aa:c1:ab:3f:9e:a2 > aa:c1:ab:fb:b2:32, ethertype IPv4 (0x0800), length 148: 10.0.2.2.55235 > 10.0.1.2.4789: VXLAN, flags [I] (0x08), vni 1
da:9d:2a:11:e4:fc > 92:2a:0a:03:e0:d5, ethertype IPv4 (0x0800), length 98: 172.16.1.2 > 172.16.0.2: ICMP echo reply, id 226, seq 1, length 64
host2 cni0 抓包情况:
host2:~# tcpdump -pne -i cni0
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on cni0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
01:45:43.131762 aa:c1:ab:df:b9:1a > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 172.16.1.2 tell 172.16.1.1, length 28
01:45:43.131782 aa:c1:ab:62:7a:01 > aa:c1:ab:df:b9:1a, ethertype ARP (0x0806), length 42: Reply 172.16.1.2 is-at aa:c1:ab:62:7a:01, length 28
01:45:43.131793 aa:c1:ab:df:b9:1a > aa:c1:ab:62:7a:01, ethertype IPv4 (0x0800), length 98: 172.16.0.2 > 172.16.1.2: ICMP echo request, id 228, seq 1, length 64
01:45:43.131812 aa:c1:ab:62:7a:01 > aa:c1:ab:df:b9:1a, ethertype IPv4 (0x0800), length 98: 172.16.1.2 > 172.16.0.2: ICMP echo reply, id 228, seq 1, length 64
01:45:48.337412 aa:c1:ab:62:7a:01 > aa:c1:ab:df:b9:1a, ethertype ARP (0x0806), length 42: Request who-has 172.16.1.1 tell 172.16.1.2, length 28
01:45:48.337494 aa:c1:ab:df:b9:1a > aa:c1:ab:62:7a:01, ethertype ARP (0x0806), length 42: Reply 172.16.1.1 is-at aa:c1:ab:df:b9:1a, length 28
host1 cni0 抓包情况:
host1:~# tcpdump -pne -i cni0
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on cni0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
01:47:51.114060 aa:c1:ab:00:3c:b9 > aa:c1:ab:a0:f0:76, ethertype IPv4 (0x0800), length 98: 172.16.0.2 > 172.16.1.2: ICMP echo request, id 229, seq 1, length 64
01:47:51.114243 aa:c1:ab:a0:f0:76 > aa:c1:ab:00:3c:b9, ethertype IPv4 (0x0800), length 98: 172.16.1.2 > 172.16.0.2: ICMP echo reply, id 229, seq 1, length 64
本质上,VXLAN 凭借其“隧道”机制,实现了跨越三层网络的组网能力。只要承载“隧道”的物理主机之间 IP 可达,数据包在对端节点被解封装后,对于 Pod 而言,整个通信过程就如同在一个无缝的虚拟内网中进行,彻底屏蔽了底层物理网络的复杂性与边界。
上面的架构是单播模式,VXLAN 支持组播模式,但是需要底层网络设备支持并配置组播。绝大多数生产环境(尤其是公有云)不会开启组播功能。 CNI 的设计目标是在任何网络上都能运行,要求用户去配置底层网络,这种强依赖性是不现实的。
那么,Flannel 是如何绕开这个限制,实现一个普适性方案的呢?答案是:它放弃了对网络功能的依赖,转而建立了一个更高级的“中央通知系统”。
Flannel 引入了一个轻量级的中央控制平面:
-
每个节点上的 flanneld 进程启动后,会向 etcd 注册自己的信息,包括:本节点的 IP(VTEP IP)、分配到的Pod 子网、以及 flannel.1 接口的 MAC 地址。
-
同时,每个 flanneld 进程也会监听(Watch)etcd 中所有其他节点注册的信息。
-
当 host1 上的 flanneld 从 etcd 中发现了 host2 的信息后,它会直接、动态地在 host1 上配置好到达 host2 所需的路由表和 FDB 转发表。
它会自动执行类似如下的命令:
# flanneld 自动在 host1 上执行类似操作
# 1. 添加到对端Pod子网的路由
ip route add 172.16.1.0/24 via 172.16.1.0 dev flannel.1 onlink
# 2. 添加对端VTEP的ARP和FDB信息
# ARP: 172.16.1.0 -> host2 flannel.1 MAC
# FDB: host2 flannel.1 MAC -> host2 IP (VTEP)
ip neigh add 172.16.1.0 lladdr <host2-flannel-MAC> dev flannel.1
bridge fdb append <host2-flannel-MAC> dst <host2-IP> dev flannel.1
除了 Flannel ,Cilium 在实现 VXLAN 的时候也是通过“控制平面”来在所有节点中配置规则。不过不同的是,Flannel 是使用的传统网络协议栈功能实现,而 Cilium 是通过 eBPF 来实现 VXLAN 的封装、解封装和路由。
总而言之,VXLAN 的核心就是“封装”技术。它通过构建一个覆盖在物理网络之上的虚拟“隧道”,彻底解决了 Host-GW 等方案无法跨越路由器的天生缺陷,让应用网络与物理网络彻底解耦。
在 Flannel、Cilium 等现代 CNI 的加持下,它更进一步摆脱了对底层组播的依赖,转而利用 etcd 或 Kubernetes API 作为“中央大脑”来智能地分发路由信息。这种设计在牺牲极小性能开销的前提下,换来了无与伦比的网络适应性和自动化能力,使其成为了云原生网络最常用的模式之一。
三、IPIP
IPIP(IP in IP)是其全称的缩写,顾名思义,它的核心思想就是在一个 IP 包的外面,再套上一个 IP 包。它是一种非常直接的隧道技术,没有 VXLAN 那么多复杂的头部信息(如 UDP 头和 VXLAN 头)。
实验配置:
#!/bin/bash
set -v
sudo clab destroy -t clab.yaml --cleanup
cat <<EOF> clab.yaml | clab deploy -t clab.yaml -
name: ipip-demo
topology:
nodes:
gw:
kind: linux
image: nicolaka/netshoot
network-mode: none
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=1
- sysctl -w net.ipv6.conf.default.disable_ipv6=1
- sysctl -w net.ipv6.conf.lo.disable_ipv6=1
# 1. 在宿主机上开启IP转发。
- sysctl -w net.ipv4.ip_forward=1
- ip addr add 10.0.1.1/24 dev eth1
- ip link set eth1 up
- ip addr add 10.0.2.1/24 dev eth2
- ip link set eth2 up
- ip addr add 10.0.3.1/24 dev eth3
- ip link set eth3 up
host1:
kind: linux
image: nicolaka/netshoot
network-mode: none
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=1
- sysctl -w net.ipv6.conf.default.disable_ipv6=1
- sysctl -w net.ipv6.conf.lo.disable_ipv6=1
# 1. 在宿主机上开启IP转发。
- sysctl -w net.ipv4.ip_forward=1
- ip addr add 10.0.1.2/24 dev eth1
- ip link set eth1 up
- ip route replace default via 10.0.1.1 dev eth1
# ⭐️ 1. 创建一个通用的IPIP隧道接口
- ip tunnel add tunl1 mode ipip local 10.0.1.2
- ip link set tunl1 up
# ⭐️ 2. 动态路由配置好后,内核路由表的状态
# 注意下一跳是对端Host的IP,而不是隧道接口
- ip route add 172.16.1.0/24 via 10.0.2.2 dev tunl1 onlink
- ip route add 172.16.2.0/24 via 10.0.3.2 dev tunl1 onlink
# 3. 本地Pod网络配置 (不变)
- brctl addbr cni0
- ip addr add 172.16.0.1/24 dev cni0
- ip link set dev cni0 up
- brctl addif cni0 pod1_veth_piar
- ip link set dev pod1_veth_piar up
pod1:
kind: linux
image: nicolaka/netshoot
network-mode: none
exec:
- ip addr add 172.16.0.2/24 dev eth1
- ip link set eth1 up
- ip route replace default via 172.16.0.1 dev eth1
host2:
kind: linux
image: nicolaka/netshoot
network-mode: none
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=1
- sysctl -w net.ipv6.conf.default.disable_ipv6=1
- sysctl -w net.ipv6.conf.lo.disable_ipv6=1
# 1. 在宿主机上开启IP转发。
- sysctl -w net.ipv4.ip_forward=1
- ip addr add 10.0.2.2/24 dev eth1
- ip link set eth1 up
- ip route replace default via 10.0.2.1 dev eth1
# ⭐️ 1. 创建一个通用的IPIP隧道接口
- ip tunnel add tunl1 mode ipip local 10.0.2.2
- ip link set tunl1 up
# ⭐️ 2. 动态路由配置好后,内核路由表的状态
- ip route add 172.16.0.0/24 via 10.0.1.2 dev tunl1 onlink
- ip route add 172.16.2.0/24 via 10.0.3.2 dev tunl1 onlink
# 3. 本地Pod网络配置 (不变)
- brctl addbr cni0
- ip addr add 172.16.1.1/24 dev cni0
- ip link set dev cni0 up
- brctl addif cni0 pod2_veth_piar
- ip link set dev pod2_veth_piar up
pod2:
kind: linux
image: nicolaka/netshoot
network-mode: none
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=1
- sysctl -w net.ipv6.conf.default.disable_ipv6=1
- sysctl -w net.ipv6.conf.lo.disable_ipv6=1
- ip addr add 172.16.1.2/24 dev eth1
- ip link set eth1 up
- ip route replace default via 172.16.1.1 dev eth1
host3:
kind: linux
image: nicolaka/netshoot
network-mode: none
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=1
- sysctl -w net.ipv6.conf.default.disable_ipv6=1
- sysctl -w net.ipv6.conf.lo.disable_ipv6=1
- ip addr add 10.0.3.2/24 dev eth1
- ip link set eth1 up
- ip route replace default via 10.0.3.1 dev eth1
# ⭐️ 1. 创建一个通用的IPIP隧道接口
- ip tunnel add tunl1 mode ipip local 10.0.3.2
- ip link set tunl1 up
# ⭐️ 2. 动态路由配置好后,内核路由表的状态
- ip route add 172.16.0.0/24 via 10.0.1.2 dev tunl1 onlink
- ip route add 172.16.1.0/24 via 10.0.2.2 dev tunl1 onlink
# 3. 本地Pod网络配置 (不变)
- brctl addbr cni0
- ip addr add 172.16.2.1/24 dev cni0
- ip link set dev cni0 up
- brctl addif cni0 pod3_veth_piar
- ip link set dev pod3_veth_piar up
pod3:
kind: linux
image: nicolaka/netshoot
network-mode: none
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=1
- sysctl -w net.ipv6.conf.default.disable_ipv6=1
- sysctl -w net.ipv6.conf.lo.disable_ipv6=1
- ip addr add 172.16.2.2/24 dev eth1
- ip link set eth1 up
- ip route replace default via 172.16.2.1 dev eth1
links:
- endpoints: ["gw:eth1", "host1:eth1"]
- endpoints: ["gw:eth2", "host2:eth1"]
- endpoints: ["gw:eth3", "host3:eth1"]
- endpoints: ["host1:pod1_veth_piar", "pod1:eth1"]
- endpoints: ["host2:pod2_veth_piar", "pod2:eth1"]
- endpoints: ["host3:pod3_veth_piar", "pod3:eth1"]
EOF
sudo clab deploy -t clab.yaml
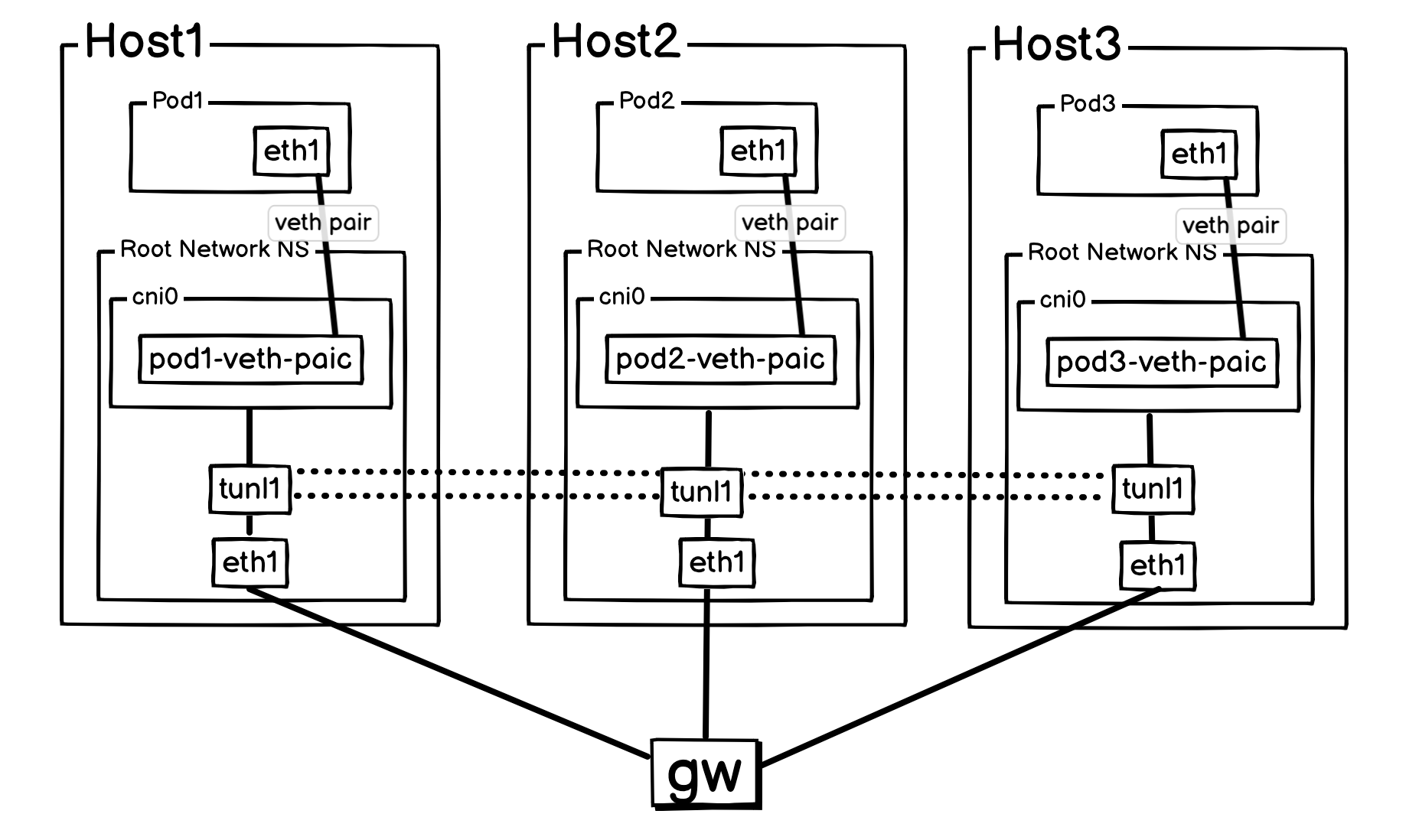
IPIP 模式下的通信流程,以下是 Pod1 与 Pod2 通过 IPIP 隧道完成一次通信的完整步骤:
- 从 Pod 出发
Pod1(172.16.0.2) 发送的 ICMP 请求包穿过 veth pair,进入Host1的内核空间。 - 主机路由决策
Host1内核查询路由表,确定发往172.16.1.2的流量需要通过tunl0这样的 IPIP 隧道接口进行处理。 - IPIP 隧道封装 内核的 IPIP 模块被触发。它将原始 IP 包(源:
Pod1, 目标:Pod2)作为载荷,在其外部封装一个新的 IP 头部(源:Host1, 目标:Host2),并将新头部的协议号设置为 4。这个封装后的新数据包通过主机的物理网卡发出。 - IPIP 隧道解封装
Host2收到数据包,其内核检查外层 IP 头,发现协议号为 4,随即调用 IPIP 模块进行解封装,剥离外层 IP 头。在内核视角看来,这个原始包是直接从本地的tunl0接口发出来的。 - 本地投递
Host2内核此时面对的是原始 IP 包。它根据自己的路由表,发现目标172.16.1.2连接在本地的cni0网桥上,于是将包轻松转发给Pod2。 - 原路返回
Pod2的 ICMP 响应包遵循完全对称的路径,经过Host2的封装和Host1的解封装,最终安全抵达Pod1。
Pod1 Ping Pod2 时,Host2 eth1 抓包情况:
host2:~# tcpdump -pne -i eth1
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on eth1, link-type EN10MB (Ethernet), snapshot length 262144 bytes
17:31:54.782204 aa:c1:ab:74:8d:d3 > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 10.0.2.2 tell 10.0.2.1, length 28
17:31:54.782219 aa:c1:ab:ea:87:f5 > aa:c1:ab:74:8d:d3, ethertype ARP (0x0806), length 42: Reply 10.0.2.2 is-at aa:c1:ab:ea:87:f5, length 28
17:31:54.782223 aa:c1:ab:74:8d:d3 > aa:c1:ab:ea:87:f5, ethertype IPv4 (0x0800), length 118: 10.0.1.2 > 10.0.2.2: 172.16.0.2 > 172.16.1.2: ICMP echo request, id 227, seq 1, length 64
17:31:54.782304 aa:c1:ab:ea:87:f5 > aa:c1:ab:74:8d:d3, ethertype IPv4 (0x0800), length 118: 10.0.2.2 > 10.0.1.2: 172.16.1.2 > 172.16.0.2: ICMP echo reply, id 227, seq 1, length 64
可以看到 IPIP 的报文封装很简单,就是 IP 套 IP 。
IPIP(IP in IP)是一种直接的隧道封装技术,其核心优势在于简洁高效。 它仅在原始 IP 包的外部增加一个标准的 IP 头部,封装开销极低,因此能提供非常高的转发性能。
然而,它的主要缺点是网络兼容性差。由于它使用 IP 协议号 4,而非更常见的 TCP/UDP,其流量容易被公有云的安全策略或企业防火墙拦截。同时,缺乏传输层端口信息也使其难以穿越网络地址转换(NAT)设备。
正是由于这种兼容性的差异,导致 IPIP 在现阶段的云原生环境中,实际采用的案例相对较少。
总结
至此,Host-gw、VXLAN 和 IPIP 三种主流 CNI 数据平面模型的实践搭建已经完成。从基础的路由表配置到构建复杂的 Overlay 网络可以发现,CNI 数据平面的实现并非依赖特定技术,而是对 Linux 内核既有功能的组合与封装。对这些基础原理的理解,是清晰剖析各种成熟 CNI 插件的关键。掌握这些底层原理,是进行有效故障排查和制定可靠网络规划的前提。