在本地环境中复现 Kubernetes 的复杂网络拓扑(例如 L2/L3 互联和 BGP 动态路由),常常是一项繁琐的任务。本文旨在介绍一种解决方案:结合使用网络实验工具 ContainerLab 与轻量级 Kubernetes 集群 Kind。通过详尽的实操步骤,文章将展示如何搭建一个功能完备的实验环境,以支持各类复杂网络场景的测试与验证。
一、Kind 和 ContainerLab 分别是什么
Kind (Kubernetes in Docker) 是一个使用 Docker 容器来快速创建和销毁 Kubernetes 集群的工具。Kind 会依据用户的配置,启动一个或者多个 Docker 容器,并让它们分别运行为控制平面节点和工作节点,在镜像正常下载之后,整个集群启动时间一般来说在一分钟以内。
ContainerLab 是一个开源的“网络实验室即代码”(Lab-as-Code)工具。它允许你通过一个 YAML 文件来定义和启动一个包含各种网络设备的复杂网络拓扑。
而 ContainerLab 可以通过创建容器时指定使用 Kind 创建的容器的网络名称空间,来将 Kind 创建的 Kubernetes 节点纳入 ContainerLab 的管理范畴。
二、二层基础网络
拓扑图:
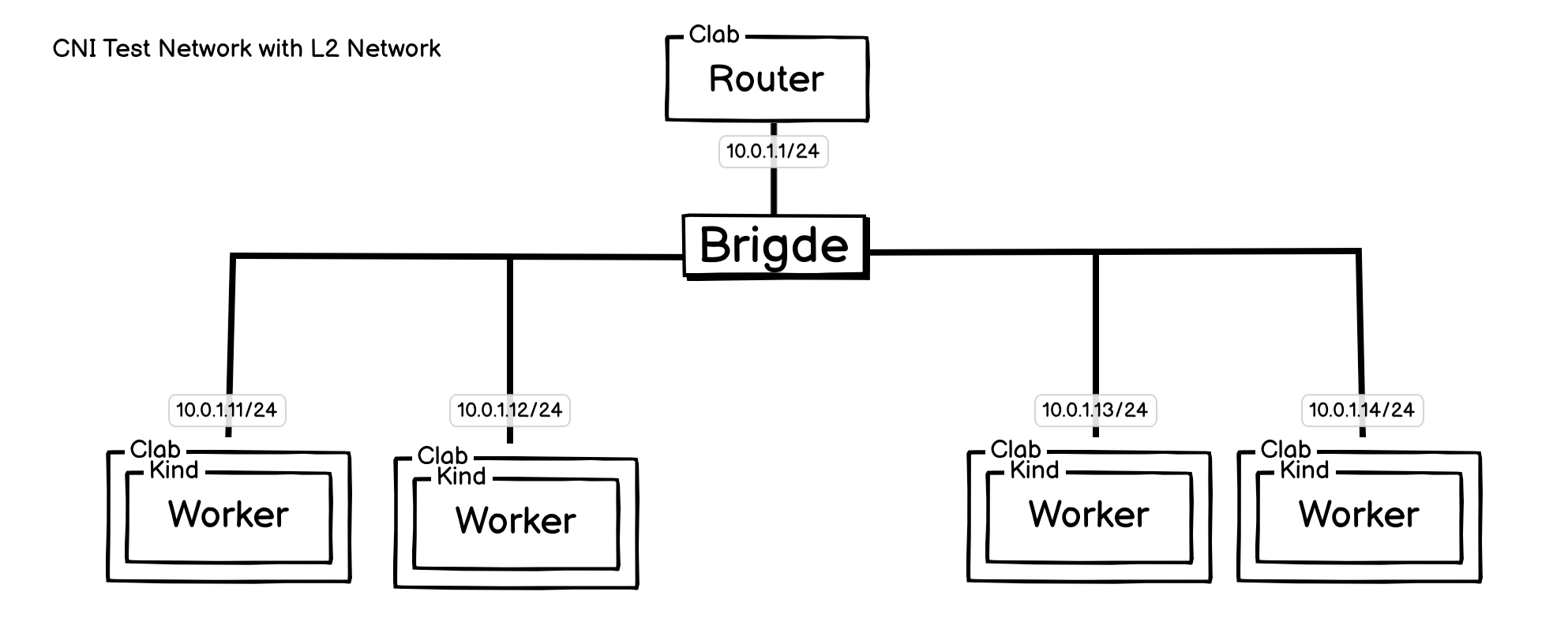
其实使用 Kind 创建的默认架构,就是连在同一个 L2 层网络,这里配置这个架构,只是为了让结构更清晰,并且能展示最基础的网络配置是如何实现的。
Worker 节点,是 Kind 创建的 Kubernetes 节点,然后 ContainerLab 会接管所有的网络设置。
2.1 使用 Kind 创建 Kubernetes 集群
创建一个 Kubernetes 集群,这里采用的 Kubernetes 版本是 v1.33.1 ,可以根据需求自行修改。
cat <<EOF | kind create cluster --name=l2-network --image=kindest/node:v1.33.1 --config=-
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
networking:
# 无 CNI
disableDefaultCNI: true
#kubeProxyMode: "none"
podSubnet: "10.1.0.0/16"
serviceSubnet: "10.96.0.0/12"
nodes:
- role: control-plane
kubeadmConfigPatches:
- |
kind: InitConfiguration
nodeRegistration:
kubeletExtraArgs:
node-ip: 10.0.1.11
- role: worker
kubeadmConfigPatches:
- |
kind: JoinConfiguration
nodeRegistration:
kubeletExtraArgs:
node-ip: 10.0.1.12
- role: worker
kubeadmConfigPatches:
- |
kind: JoinConfiguration
nodeRegistration:
kubeletExtraArgs:
node-ip: 10.0.1.13
- role: worker
kubeadmConfigPatches:
- |
kind: JoinConfiguration
nodeRegistration:
kubeletExtraArgs:
node-ip: 10.0.1.14
EOF
运行后,会创建几个容器,这就是一个 Kubernetes 集群。
root@server:~/cluster-mesh# kubectl get nodes
NAME STATUS ROLES AGE VERSION
l2-network-control-plane NotReady control-plane 4m3s v1.33.1
l2-network-worker NotReady <none> 3m50s v1.33.1
l2-network-worker2 NotReady <none> 3m50s v1.33.1
l2-network-worker3 NotReady <none> 3m51s v1.33.1
root@server:~/cluster-mesh# sudo docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d177fbc51154 kindest/node:v1.33.1 "/usr/local/bin/entr…" 4 minutes ago Up 4 minutes l2-network-worker2
8154b7774b5c kindest/node:v1.33.1 "/usr/local/bin/entr…" 4 minutes ago Up 4 minutes l2-network-worker3
ad2c67bc787b kindest/node:v1.33.1 "/usr/local/bin/entr…" 4 minutes ago Up 4 minutes 127.0.0.1:42831->6443/tcp l2-network-control-plane
e85070483e63 kindest/node:v1.33.1 "/usr/local/bin/entr…" 4 minutes ago Up 4 minutes l2-network-worker
2.2 使用 ContainerLab 构建网络
# 创建网桥
brctl addbr l2-network-br
ip link set l2-network-br up
cat <<EOF> l2-network-clab.yaml
name: l2-network
mgmt:
ipv4-subnet: 172.16.100.0/24
topology:
nodes:
l2-network-br:
kind: bridge
router:
kind: linux
image: nicolaka/netshoot
exec:
- ip addr add 10.0.1.1/24 dev net0
- ip link set net0 up
# SNAT 设置
- sysctl -w net.ipv4.ip_forward=1
- iptables -t nat -A POSTROUTING -s 10.0.0.0/8 -j MASQUERADE
control-plane:
kind: linux
image: nicolaka/netshoot
# 使用 Kind 创建的 K8S 节点的网络名称空间
network-mode: container:l2-network-control-plane
exec:
- ip addr add 10.0.1.11/24 dev net0
# 替代默认路由
- ip route replace default via 10.0.1.1
worker:
kind: linux
image: nicolaka/netshoot
network-mode: container:l2-network-worker
exec:
- ip addr add 10.0.1.12/24 dev net0
- ip route replace default via 10.0.1.1
worker2:
kind: linux
image: nicolaka/netshoot
network-mode: container:l2-network-worker2
exec:
- ip addr add 10.0.1.13/24 dev net0
- ip route replace default via 10.0.1.1
worker3:
kind: linux
image: nicolaka/netshoot
network-mode: container:l2-network-worker3
exec:
- ip addr add 10.0.1.14/24 dev net0
- ip route replace default via 10.0.1.1
links:
# 网卡是如何连接的。
- endpoints: [l2-network-br:l2-network-br-eth1, router:net0]
- endpoints: [l2-network-br:l2-network-br-eth2, control-plane:net0]
- endpoints: [l2-network-br:l2-network-br-eth3, worker:net0]
- endpoints: [l2-network-br:l2-network-br-eth4, worker2:net0]
- endpoints: [l2-network-br:l2-network-br-eth5, worker3:net0]
EOF
sudo clab deploy -t l2-network-clab.yaml
需要注意的是,连在 l2-network-br 上面的网卡,一侧连在 ContainerLab,一侧创建在宿主机侧的的 veth-pair 网卡,所以名字不能和宿主机现有的网卡名冲突。
有两个关键设置需要解释一下:
- topology.ClabContainerName.network-mode: container:RunContainerName: 这个配置的作用,是 ClabContainerName 容器,将使用 RunContainerName 的网络名称空间。这样配置就能实现 ContainerLab 接管 Kind 节点的网络。
- topology.router.exec: “sysctl -w net.ipv4.ip_forward=1; iptables -t nat -A POSTROUTING -s 10.0.0.0/8 -j MASQUERADE”: 这个是做 SNAT使用,因为 Kind 创建的 K8S 节点默认路由已经被修改,所以需要其他地方能让其访问到外部网络,这样才能拉镜像和连接外网。
查看容器情况:
root@server:~/cni-test-network/l2-network# sudo docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ea5689b36810 nicolaka/netshoot "zsh" 13 seconds ago Up 12 seconds clab-l2-network-worker3
12b724e5e2c8 nicolaka/netshoot "zsh" 13 seconds ago Up 13 seconds clab-l2-network-worker
46b443753325 nicolaka/netshoot "zsh" 14 seconds ago Up 13 seconds clab-l2-network-control-plane
c82882c9628b nicolaka/netshoot "zsh" 14 seconds ago Up 13 seconds clab-l2-network-worker2
0f0137fe790b nicolaka/netshoot "zsh" 17 seconds ago Up 16 seconds clab-l2-network-router
d177fbc51154 kindest/node:v1.33.1 "/usr/local/bin/entr…" 25 minutes ago Up 25 minutes l2-network-worker2
8154b7774b5c kindest/node:v1.33.1 "/usr/local/bin/entr…" 25 minutes ago Up 25 minutes l2-network-worker3
ad2c67bc787b kindest/node:v1.33.1 "/usr/local/bin/entr…" 25 minutes ago Up 25 minutes 127.0.0.1:42831->6443/tcp l2-network-control-plane
e85070483e63 kindest/node:v1.33.1 "/usr/local/bin/entr…" 25 minutes ago Up 25 minutes l2-network-worker
2.3 验证
看下 ContainerLab 创建的容器和 Kind 创建的容器的网络状况:
root@server:~/cni-test-network/l2-network# docker exec -it clab-l2-network-control-plane ip r s
default via 10.0.1.1 dev net0
10.0.1.0/24 dev net0 proto kernel scope link src 10.0.1.11
172.20.0.0/16 dev eth0 proto kernel scope link src 172.20.0.6
root@server:~/cni-test-network/l2-network# docker exec -it l2-network-control-plane ip r s
default via 10.0.1.1 dev net0
10.0.1.0/24 dev net0 proto kernel scope link src 10.0.1.11
172.20.0.0/16 dev eth0 proto kernel scope link src 172.20.0.6
root@server:~/cni-test-network/l2-network# docker exec -it clab-l2-network-control-plane curl -k https://127.0.0.1:6443
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {},
"status": "Failure",
"message": "forbidden: User \"system:anonymous\" cannot get path \"/\"",
"reason": "Forbidden",
"details": {},
"code": 403
}
可以看到 clab-l2-network-control-plane 和 l2-network-control-plane 融和到一起了,其实就是相当于一个 Pod 中的两个容器,使用的同一个网络名称空间,其中 172.20.0.0/16 是 Kind 自带的网络配置。
在 l2-network-br抓包看下(注意,抓网桥的包的时候不要 -p (非混杂模式),不然抓不到 ICMP 包):
root@server:~# tcpdump -ne -i l2-network-br
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on l2-network-br, link-type EN10MB (Ethernet), snapshot length 262144 bytes
23:28:05.532015 aa:c1:ab:3d:2a:a1 > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 10.0.1.12 tell 10.0.1.11, length 28
23:28:05.532065 aa:c1:ab:a4:fd:81 > aa:c1:ab:3d:2a:a1, ethertype ARP (0x0806), length 42: Reply 10.0.1.12 is-at aa:c1:ab:a4:fd:81, length 28
23:28:05.532075 aa:c1:ab:3d:2a:a1 > aa:c1:ab:a4:fd:81, ethertype IPv4 (0x0800), length 98: 10.0.1.11 > 10.0.1.12: ICMP echo request, id 188, seq 1, length 64
23:28:05.532127 aa:c1:ab:a4:fd:81 > aa:c1:ab:3d:2a:a1, ethertype IPv4 (0x0800), length 98: 10.0.1.12 > 10.0.1.11: ICMP echo reply, id 188, seq 1, length 64
从上面抓包情况可以看到,Kind 节点间的报文流通,已经是通过 ContainerLab 创建的网桥进行的了。
而且 Kind 节点也可以正常连接外网。
root@server:~/cni-test-network/l2-network# docker exec -it clab-l2-network-control-plane ping -c 1 223.5.5.5
PING 223.5.5.5 (223.5.5.5) 56(84) bytes of data.
64 bytes from 223.5.5.5: icmp_seq=1 ttl=111 time=52.6 ms
然后就可以安装 CNI 进行测试了。
2.4 清理实验环境
测试完之后,清理环境也非常简单。
clab destroy -t l2-network-clab.yaml --cleanup
kind delete clusters l2-network
ip link set l2-network-br down
brctl delbr l2-network-br
三、跨子网网络
拓扑图:
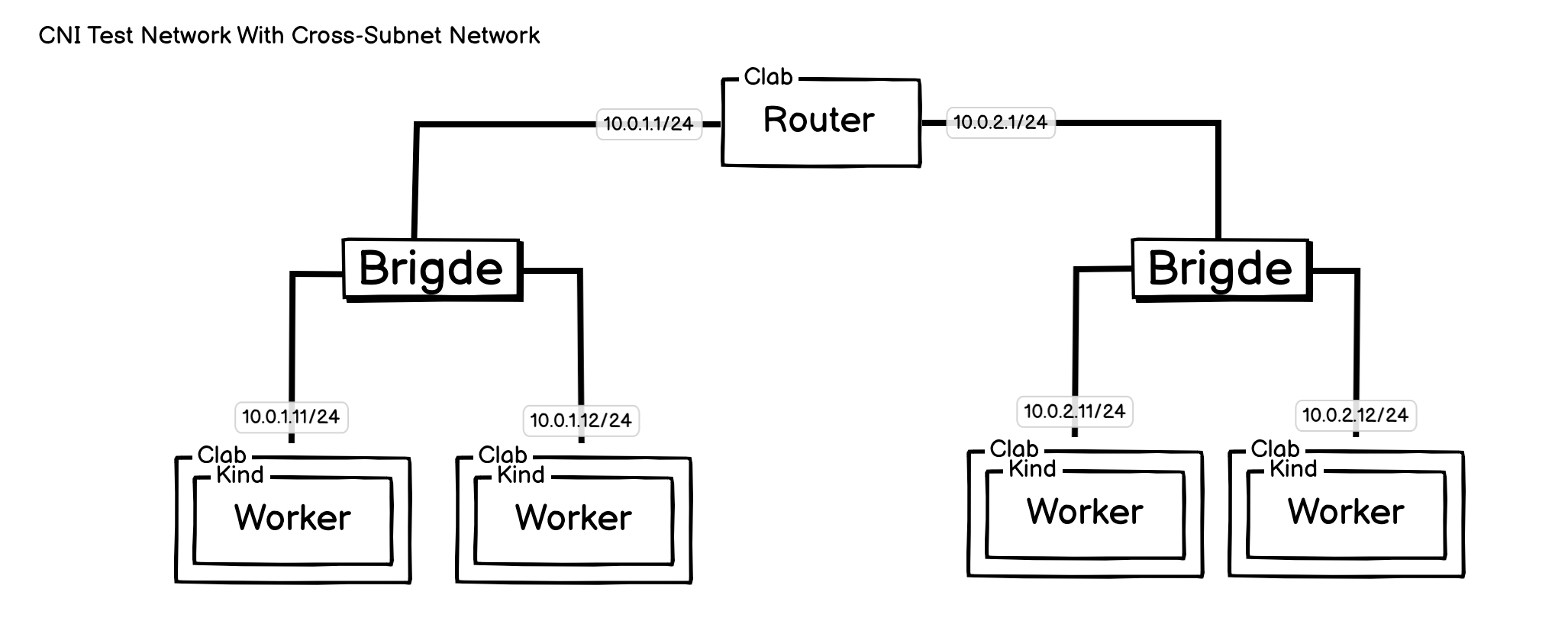
跨子网网络,也是非常常见的网络架构,可以测试各个 CNI 的 Overlay 模式,还可以用于测试 Calico 的 CrossSubnet 模式,或者 Flannel 的混杂模式,甚至是 Cilium 的 Cluster Mesh 或者其他的 K8S 多集群管理、互联方案。
3.1 Kind 创建集群
Kind 创建的集群和上面网络创建的基本无任何区别,只有节点 IP 更换了。
cat <<EOF | kind create cluster --name=cross-subnet --image=kindest/node:v1.33.1 --config=-
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
networking:
disableDefaultCNI: true
#kubeProxyMode: "none"
podSubnet: "10.1.0.0/16"
serviceSubnet: "10.96.0.0/12"
nodes:
- role: control-plane
kubeadmConfigPatches:
- |
kind: InitConfiguration
nodeRegistration:
kubeletExtraArgs:
node-ip: 10.0.5.11
- role: worker
kubeadmConfigPatches:
- |
kind: JoinConfiguration
nodeRegistration:
kubeletExtraArgs:
node-ip: 10.0.5.12
- role: worker
kubeadmConfigPatches:
- |
kind: JoinConfiguration
nodeRegistration:
kubeletExtraArgs:
node-ip: 10.0.10.12
- role: worker
kubeadmConfigPatches:
- |
kind: JoinConfiguration
nodeRegistration:
kubeletExtraArgs:
node-ip: 10.0.10.13
EOF
3.2 ContainerLab 配置
cat <<EOF> cross-subnet-clab.yaml
name: cross-subnet
mgmt:
ipv4-subnet: 172.16.100.0/24
topology:
nodes:
clab-br1:
kind: bridge
clab-br2:
kind: bridge
router:
kind: linux
image: nicolaka/netshoot
exec:
- ip addr add 10.0.5.1/24 dev net0
- ip link set net0 up
- ip addr add 10.0.10.1/24 dev net1
- ip link set net0 up
# SNAT 设置
- sysctl -w net.ipv4.ip_forward=1
- iptables -t nat -A POSTROUTING -s 10.0.0.0/8 -j MASQUERADE
control-plane:
kind: linux
image: nicolaka/netshoot
# 使用 Kind 创建的 K8S 节点的网络名称空间
network-mode: container:cross-subnet-control-plane
exec:
- ip addr add 10.0.5.11/24 dev net0
# 替代默认路由
- ip route replace default via 10.0.5.1
worker:
kind: linux
image: nicolaka/netshoot
network-mode: container:cross-subnet-worker
exec:
- ip addr add 10.0.5.12/24 dev net0
- ip route replace default via 10.0.5.1
worker2:
kind: linux
image: nicolaka/netshoot
network-mode: container:cross-subnet-worker2
exec:
- ip addr add 10.0.10.11/24 dev net0
- ip route replace default via 10.0.10.1
worker3:
kind: linux
image: nicolaka/netshoot
network-mode: container:cross-subnet-worker3
exec:
- ip addr add 10.0.10.12/24 dev net0
- ip route replace default via 10.0.10.1
links:
- endpoints: [clab-br1:clab-br1-eth1, router:net0]
- endpoints: [clab-br1:clab-br1-eth2, control-plane:net0]
- endpoints: [clab-br1:clab-br1-eth3, worker:net0]
- endpoints: [clab-br2:clab-br2-eth1, router:net1]
- endpoints: [clab-br2:clab-br2-eth2, worker2:net0]
- endpoints: [clab-br2:clab-br2-eth3, worker3:net0]
EOF
sudo clab deploy -t cross-subnet-clab.yaml
3.3 测试
Kind 节点与节点间网络无问题,且可以看到过路由器的报文 TTL 少了 1 :
root@server:~/cni-test-network/cross-subnet# docker exec -it clab-cross-subnet-control-plane /bin/bash
cross-subnet-control-plane:~# ping -c 1 10.0.10.11
PING 10.0.10.11 (10.0.10.11) 56(84) bytes of data.
64 bytes from 10.0.10.11: icmp_seq=1 ttl=63 time=0.207 ms
--- 10.0.10.11 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.207/0.207/0.207/0.000 ms
cross-subnet-control-plane:~# ping -c 1 10.0.5.11
PING 10.0.5.11 (10.0.5.11) 56(84) bytes of data.
64 bytes from 10.0.5.11: icmp_seq=1 ttl=64 time=0.046 ms
--- 10.0.5.11 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.046/0.046/0.046/0.000 ms
3.4 清理环境
clab destroy -t cross-subnet-clab.yaml --cleanup
kind delete clusters cross-subnet
ip link set clab-br1 down
brctl delbr clab-br1
ip link set clab-br2 down
brctl delbr clab-br2
四、基础 BGP 网络
BGP 已成为 Kubernetes 中各种 CNI(容器网络接口)事实上的标准动态路由协议。对此,Calico 在其文章《Why BGP?》中给出了详细阐述。
Calico 选择 BGP 的原因可归结为三点:
- 简洁性:在 CNI 的应用场景中,BGP 的配置与运行十分简单。
- **成熟可靠:作为互联网的核心技术,BGP 久经考验,是公认的行业最佳实践。
- 卓越的扩展性:这一点至关重要。BGP 是唯一能够满足现代数据中心和云原生环境中海量端点路由需求的协议。
因此,理解并搭建基于 BGP 的网络,是深入学习 CNI 网络模型的一项关键基础。
拓扑图:
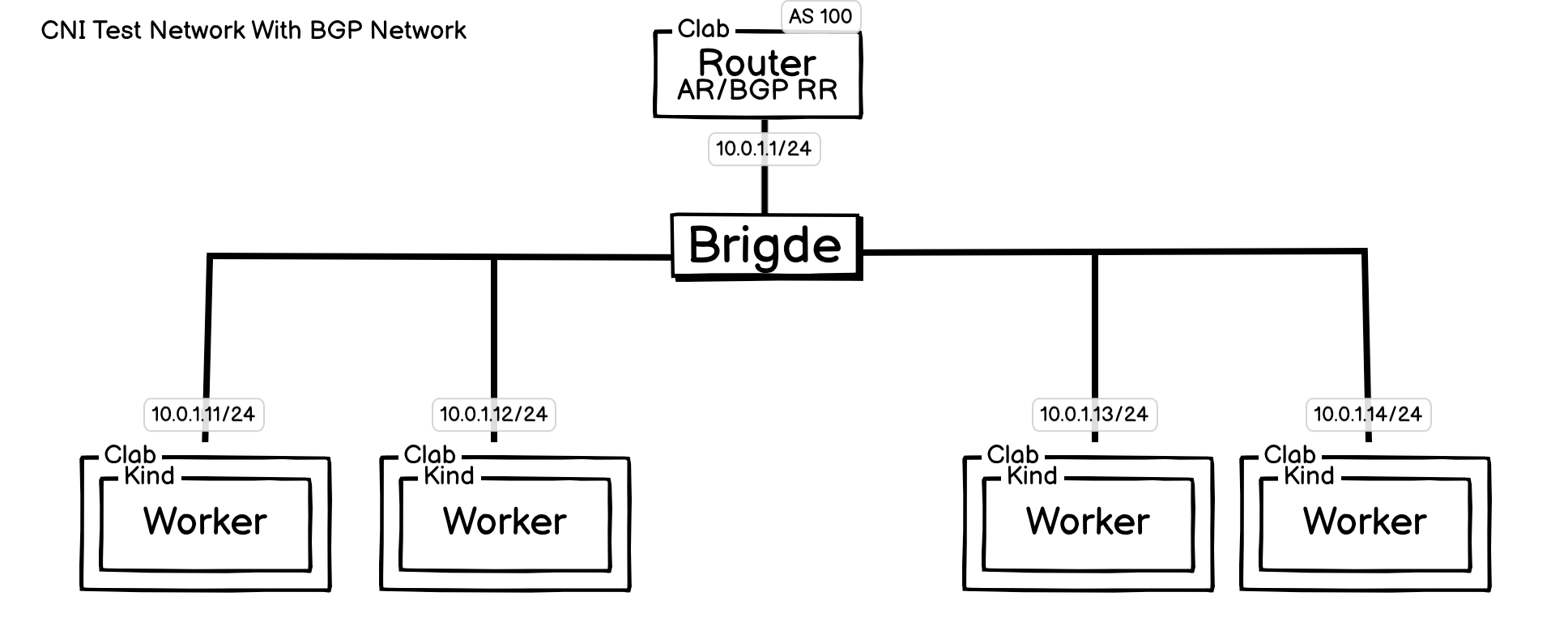
此网络和 l2-network的区别是,Router 除了路由功能,还作为网络中的 BGP 路由反射器,此项功能,使用普通容器并不是很好支持,这里将采用 Vyos 来实现路由反射器功能。
4.1 Vyos
VyOS 是一个基于 Debian Linux 的开源网络操作系统,是一个功能完整、资源占用低的纯软件路由器,能轻松地在任何虚拟环境(如 Docker、VMware、VirtualBox、KVM)中创建复杂的、可随时重置的虚拟网络拓扑,是进行网络功能测试和实验的理想沙箱。
自 VyOS 1.2.0 版本以后,项目团队改变了其发布策略,旨在为专职开发人员提供资金。并不直接对外提供可用的 LTS 版本的 IOS 和 Docker 镜像,只能自己制作。
这里参考官网文档制作了 1.5 版本的镜像(文档中的 Vyos 配置命令也是 Vyos 1.5 版)。
相关文档: Vyos官网源码下载链接, Vyos官网 Docker 镜像制作文档
Vyos 镜像执行步骤:
$ mkdir vyos && cd vyos
$ curl -o vyos-1.5-stream-2025-Q1-generic-amd64.iso https://community-downloads.vyos.dev/stream/1.5-stream-2025-Q1/vyos-1.5-stream-2025-Q1-generic-amd64.iso
$ mkdir rootfs
$ sudo mount -o loop vyos-1.5-stream-2025-Q1-generic-amd64.iso rootfs
$ sudo apt-get install -y squashfs-tools
$ mkdir unsquashfs
$ sudo unsquashfs -f -d unsquashfs/ rootfs/live/filesystem.squashfs
$ sudo tar -C unsquashfs -c . | docker import - vyos:1.5-stream-2025-Q1-generic-amd64
$ sudo umount rootfs
$ cd ..
$ sudo rm -rf vyos
可以参考上面的方法制作镜像,也可以使用我制作好的镜像:hihihiai/vyos:1.5-stream-2025-Q1-generic-amd64
4.2 Kind 配置
Kind 采用的是 l2-network 中的配置:
cat <<EOF | kind create cluster --name=bgp-network --image=kindest/node:v1.33.1 --config=-
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
networking:
# 无 CNI
disableDefaultCNI: true
#kubeProxyMode: "none"
podSubnet: "10.1.0.0/16"
serviceSubnet: "10.96.0.0/12"
nodes:
- role: control-plane
kubeadmConfigPatches:
- |
kind: InitConfiguration
nodeRegistration:
kubeletExtraArgs:
node-ip: 10.0.1.11
- role: worker
kubeadmConfigPatches:
- |
kind: JoinConfiguration
nodeRegistration:
kubeletExtraArgs:
node-ip: 10.0.1.12
- role: worker
kubeadmConfigPatches:
- |
kind: JoinConfiguration
nodeRegistration:
kubeletExtraArgs:
node-ip: 10.0.1.13
- role: worker
kubeadmConfigPatches:
- |
kind: JoinConfiguration
nodeRegistration:
kubeletExtraArgs:
node-ip: 10.0.1.14
EOF
4.3 ConatinerLab 配置
# vyos 配置持久化
mkdir -pv ./vyos-boot-conf
touch ./vyos-boot-conf/config.boot
# 创建网桥
brctl addbr bgp-network-br
ip link set bgp-network-br up
cat <<EOF> bgp-network-clab.yaml
name: bgp-network
mgmt:
ipv4-subnet: 172.16.100.0/24
topology:
nodes:
bgp-network-br:
kind: bridge
router:
kind: linux
image: hihihiai/vyos:1.5-stream-2025-Q1-generic-amd64
cmd: /sbin/init
binds:
# 使用宿主机的 modules ,不需要特别处理,直接使用即可。
- /lib/modules:/lib/modules
# 将配置文件持久化,后续重建环境就不再需要交互式配置
#- ./vyos-boot-conf/config.boot:/opt/vyatta/etc/config/config.boot
control-plane:
kind: linux
image: nicolaka/netshoot
# 使用 Kind 创建的 K8S 节点的网络名称空间
network-mode: container:bgp-network-control-plane
exec:
- ip addr add 10.0.1.11/24 dev net0
# 替代默认路由
- ip route replace default via 10.0.1.1
worker:
kind: linux
image: nicolaka/netshoot
network-mode: container:bgp-network-worker
exec:
- ip addr add 10.0.1.12/24 dev net0
- ip route replace default via 10.0.1.1
worker2:
kind: linux
image: nicolaka/netshoot
network-mode: container:bgp-network-worker2
exec:
- ip addr add 10.0.1.13/24 dev net0
- ip route replace default via 10.0.1.1
worker3:
kind: linux
image: nicolaka/netshoot
network-mode: container:bgp-network-worker3
exec:
- ip addr add 10.0.1.14/24 dev net0
- ip route replace default via 10.0.1.1
links:
# 网卡是如何连接的。
- endpoints: [bgp-network-br:bgp-network-br-eth1, router:net0]
- endpoints: [bgp-network-br:bgp-network-br-eth2, control-plane:net0]
- endpoints: [bgp-network-br:bgp-network-br-eth3, worker:net0]
- endpoints: [bgp-network-br:bgp-network-br-eth4, worker2:net0]
- endpoints: [bgp-network-br:bgp-network-br-eth5, worker3:net0]
EOF
sudo clab deploy -t bgp-network-clab.yaml
Vyos 网络配置:
上面只是搭建了网络组件,里面具体的协议还未执行。
Vyos 配置方法:
docker exec -it clab-bgp-network-router /bin/bash
# 如果 su vyos 提示用户不存在,级 vyos 还没启动完成,等待一会即可。
root# su vyos
vyos$ configure
# 开始配置
vyos$
# 保存并退出
vyos$ commit
vyos$ save
vyso$ exit
Router Vyos 配置命令:
set interfaces ethernet eth1 address 10.0.1.1/24
# 配置 BGP AS 信息。
set protocols bgp system-as '100'
set protocols bgp parameters router-id '10.0.1.1'
# 配置 BGP 路由反射器,10.0.1.0/24 网段,只需要指定当前节点为路由反射器,就能建立 BGP Peer 连接。
set protocols bgp peer-group RR-CLIENTS-DYNAMIC remote-as '100'
# 将此 peer-group 设置为 IPv4 单播的路由反射器
set protocols bgp peer-group RR-CLIENTS-DYNAMIC address-family ipv4-unicast route-reflector-client
## 设置BGP监听来自 10.0.1.0/24 网段的连接请求
## 并将成功建立的邻居自动加入 RR-CLIENTS-DYNAMIC 组
set protocols bgp listen range 10.0.1.0/24 peer-group 'RR-CLIENTS-DYNAMIC'
# 如果设置了复杂的 BGP 网络,需要通过此配置通告当前 AS 的网段。
# set protocols bgp address-family ipv4-unicast network 10.0.5.0/24
# SNAT 配置
set nat source rule 10 description 'Do NOT NAT traffic to private networks'
# 目的地是您整个内部网络的大网段,比如 10.0.0.0/8
set nat source rule 10 destination address '10.0.0.0/8'
# 关键命令:'exclude' 告诉系统,如果匹配这条规则,就直接跳过后续的NAT处理
set nat source rule 10 exclude
# 源 IP 如果属于 10.0.0.0/8,使用 SNAT 转发。
set nat source rule 100 source address '10.0.0.0/8'
set nat source rule 100 translation address 'masquerade'
commit
save
vyos 配置现在都是非持久化配置,需要持久化 vyos 配置:
复制 vyos router 容器中 /opt/vyatta/etc/config/config.boot 到外部 ./vyos-boot-conf/config.boot ,并将 router 中 config.boot 映射配置打开,后续启动此环境,就不再需要手动配置 vyos 配置。
4.4 测试
这里测试,需要采用支持 BGP 的 CNI,并且需要使用 BGP 路由反射器。
kubectl taint nodes $(kubectl get nodes -o name | grep control-plane) node-role.kubernetes.io/control-plane:NoSchedule-
kubectl get nodes -o wide
helm repo add cilium https://helm.cilium.io/ > /dev/null 2>&1
helm repo update > /dev/null 2>&1
# --set bgpControlPlane.enabled=true 启用 BPG 策略。
# --set autoDirectNodeRoutes=true 如果你的所有 Kubernetes 节点都连接在同一个交换机上(或者在同一个VLAN里,可以相互直接通信而无需经过路由器),那么就打开这个功能。
helm install cilium cilium/cilium --version 1.17.4 --namespace kube-system --set operator.replicas=1 \
--set routingMode=native --set ipv4NativeRoutingCIDR="10.1.0.0/16" --set autoDirectNodeRoutes=true \
--set debug.enabled=true --set debug.verbose=datapath --set monitorAggregation=none \
--set ipam.mode=kubernetes \
--set bgpControlPlane.enabled=true
# 3. wait all pods ready
kubectl wait --timeout=100s --for=condition=Ready=true pods --all -A
# 4. cilium status
kubectl -nkube-system exec -it ds/cilium -- cilium status
kubectl get crds | grep ciliumbgppeeringpolicies.cilium.io
配置 Cilium CiliumBGPPeeringPolicy:
cat <<EOF | kubectl apply -f -
apiVersion: "cilium.io/v2alpha1"
kind: CiliumBGPPeeringPolicy
metadata:
name: "as100"
spec:
# 这个策略应用到哪些Kubernetes节点上。
nodeSelector: {}
virtualRouters:
- localASN: 100 # 这些Worker节点所在的 ASN
# 导出您想宣告的Pod CIDR。必须设置。
exportPodCIDR: true
# 配置 BGP 路由反射器
neighbors:
- peerAddress: "10.0.1.1/24" # BGP 路由反射器 的IP地址
peerASN: 100
EOF
查看路由通告情况:
root@server:~# docker exec -it clab-bgp-network-router /bin/bash
root@router:/# ip r s
default via 172.16.100.1 dev eth0
10.0.1.0/24 dev eth1 proto kernel scope link src 10.0.1.1
10.1.0.0/24 nhid 17 via 10.0.1.11 dev eth1 proto bgp metric 20
10.1.1.0/24 nhid 14 via 10.0.1.13 dev eth1 proto bgp metric 20
10.1.3.0/24 nhid 18 via 10.0.1.14 dev eth1 proto bgp metric 20
10.1.4.0/24 nhid 20 via 10.0.1.12 dev eth1 proto bgp metric 20
172.16.100.0/24 dev eth0 proto kernel scope link src 172.16.100.2
可以发现路由信息都被通告到了 BGP 路由反射器上。
清理 CNI,之后就可以安装其他 CNI 进行测试了:
root@server:~# helm uninstall cilium -n kube-system
release "cilium" uninstalled
4.5 清理
clab des -t bgp-network-clab.yaml --cleanup
kind delete clusters bgp-network
ip link set bgp-network-br down
brctl delbr bgp-network-br
五、多 AS BGP 网络
ContainerLab 不仅可以用于配置和测试基础的 BGP 路由反射器,也能支持更为复杂的跨 AS (自治系统) 生产网络环境。
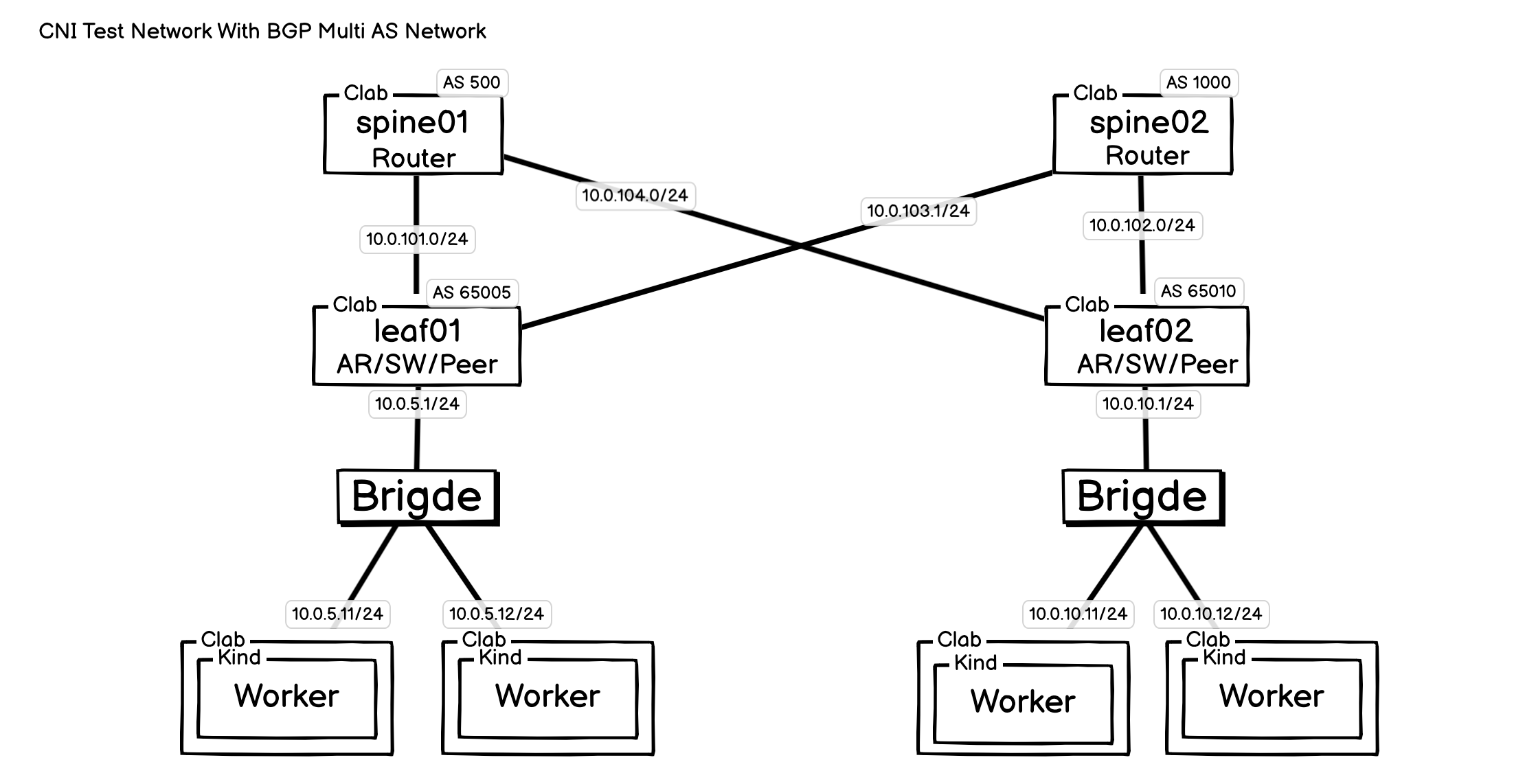
上图展示的 Spine-Leaf(脊叶)架构,是现代数据中心与云原生环境中的一种主流网络设计。它通过让 Leaf(接入层)与 Spine(核心层)完全互联,带来了极高带宽、低延迟和强大水平扩展能力等核心优势。
我曾基于上述网络拓扑撰写过一篇关于 Cilium BGP 的文章。如需了解该方案的详细配置,请参阅《Cilium: 构建跨 BGP AS 域的 Kubernetes 集群网络》。
结束语
至此,一套轻量且功能强大的 Kubernetes 网络实验室便搭建完成。该方案通过 ContainerLab 模拟外部网络,并与 Kind 集群建立连接,最终实现了从 Pod 到外部网络的 L3 及 BGP 通信。这个低成本、高效率的“沙箱”环境,使得 CNI 插件测试、网络策略验证、生产级 BGP 路由模拟等复杂任务变得直观可行,为在学习和测试验证各类网络架构提供了一个便捷有效的路径。