keepalived最初是为LVS而研发的一款高可用软件,是能对LVS的Director进行高可用保障并且能对后端Real Server进行检测的HA解决方案,现在已经独立出来能对其它服务进行高可用。所以在配置和友好性上,都是针对LVS。相对corosync+packmake或者RHCS这样的高可用集群解决方法来说,keepalived是一个特别轻量级的一个HA解决方案
理论知识:
keepalived是基于VRRP(虚拟路由冗余协议),表面上和其它高可用集群方案不同的是,当主节点出现问题,从节点不单会将vIP接收,还会将vMAC接收,而不用像其它HA实现方案还需要使用类似ARP欺骗让直连的交换机刷新MAC表。实际上和其它集群实现方案完全不同,我下面会介绍
VRRP(虚拟路由冗余协议)是一个开放协议,是为了防止当一个对可用性要求不低的公司防止公司网关单点故障导致整个网络故障而出现的协议,它会将2个或者多个路由器当作一个路由器使用,平时都是使用其中主路由器也就是Master,其它路由器都是Backup,Master是通过选举产生,优先级从0~255,当优先级为255的时候,直接会成为Master。当Master出现故障,Backup会通过VRRP通告得知Master故障,从而自动再选举一个Master。VRRP报文只有Master才可以发送
- 虚拟路由器:所有的Master和backup组合在一起统称虚拟路由器
- Master:虚拟路由器中负责负责转发的路由器
- Backup:备用Master
- vIP:虚拟IP,相信大家都很熟悉
- vMAC:虚拟MAC,作用上面已经解释过了,前面
00-00-5E-00-01-{vRID} - vRID:虚拟路由器标示
- 优先级:决定Master和Backup
- 非抢占:如果Backup工作在非抢占模式。那么就算Backup配置了高于Master的优先级,Backup也不会在Master没有故障的情况下成为Master。
- 抢占:和非抢占相反。
VRRP的工作过程(H3C—VRRP文档):
(1) 虚拟路由器中的路由器根据优先级选举出 Master。Master 路由器通过发送免 费ARP报文,将自己的虚
拟MAC地址通知给与它连接的设备或者主机,从而承担报文转发任务;
(2) Master 路由器周期性发送 VRRP 报文,以公布其配置信息(优先级等)和工作状况;
(3) 如果 Master 路由器出现故障,虚拟路由器中的 Backup 路由器将根据优先级重新选举新的 Master;
(4) 虚拟路由器状态切换时,Master 路由器由一台设备切换为另外一台设备,新的 Master路由器只是简单
地发送一个携带虚拟路由器的MAC地址和虚拟IP地址信息的免费ARP报文,这样就可以更新与它连接的主
机或设备中的ARP相关信息。网络中的主机感知不到Master路由器已经切换为另外一台设备。Backup路
由器的优先级高于 Master路由器时,由Backup路由器的工作方式(抢占方式和非抢占方式)决定是否
重新选举Master。
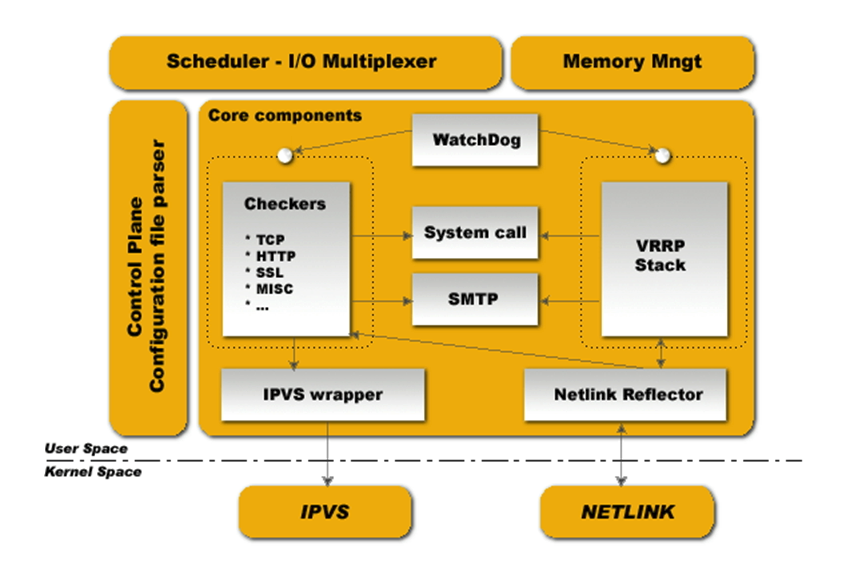
keepalived官方给的图,它自身有内存管理,并且基于I/O复用工作,配置接口就它的配置文件/etc/keepalived/keepalived.conf,当然keepalived可以调用其它脚本,而且很多时候被调用的脚本也有配置作用
- WatchDog:看门狗进程,使用Unix Socket的方式监视Checkers和VRRP Stack进程是否存活
- Checkers:监控进程,通过TCP、HTTP、SSL等方式监控Real Server或者其他服务器。
- VRRP Stack:实现VRRP功能的进程
基础配置:
Centos 6.4已经自带了keepalived软件包,可以使用yum进行安装。如果是不能直接yum安装的系统,请去keepalived.org下载。
[root@controller ~]# ansible lvsDirectors -m yum -a "name=keepalived state=present"
主配置文件keepalived.conf详解
global_defs { //全局配置段,现在只是测试用,只需简单修改默认配置即可
notification_email {
root@localhost
}
notification_email_from keepalived@notify
router_id LVS_DEVEL
}
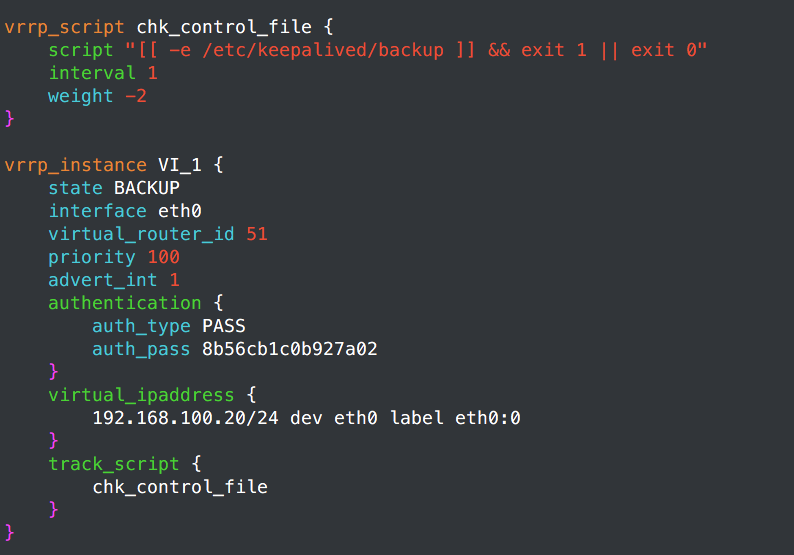
vrrp_script chk_control_file { //定义监控脚本
script "[[ -f /etc/keepalived/backup ]] && exit 1 || exit 0"
interval 1 //间隔,单位为S
weight -2 //如果脚本检测返回值为1,则执行weight-2
}
vrrp_instance VI_1 { //定义一个实例
state BACKUP //初始状态为BACKUP状态,
interface eth0 //通告端口为eth0
virtual_router_id 51 //route id,如果定义多组虚拟组,那这个地方得不同,并且虚拟Mac也是由这个地方控制
priority 99 //优先级
advert_int 1 //通告时间间隔
nopreempt //非抢占(去掉这行为抢占)
authentication { //定义认证
auth_type PASS
auth_pass 8b56cb1c0b927a02
}
virtual_ipaddress { //虚拟IP
192.168.100.20/24 dev eth0 label eth0:0
}
track_script { //调用脚本
chk_control_file //接上面定义过的脚本
}
}
启动服务
# ansible lvsDirectors -m shell -a "service keepalived start"
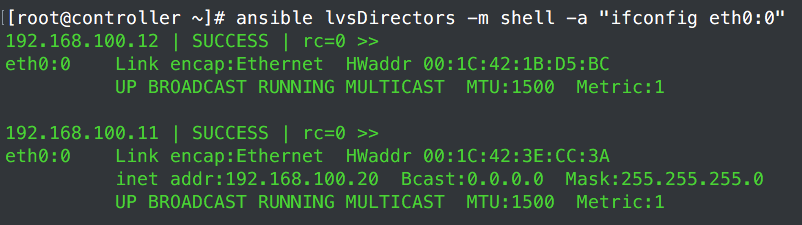
由于192.168.100.11(node1节点)上面配置的优先级为100,192.168.100.12(node2节点)优先级为99,所以192.168.100.11为Master节点。
尝试监控脚本 chk_control_file,在/etc/keepalived/目录下面建立backup。让node1优先级减2,让其优先级低于node2,看资源转不转移。
# echo "==========================Initial state=====================================";
> ansible lvsDirectors -m shell -a "ifconfig eth0:0"|grep 192.168.100.20;\
> ssh 192.168.100.11 "touch /etc/keepalived/backup" ; \
> echo "==========================touch test file=====================================" ;
> sleep 4 ; \
> ansible lvsDirectors -m shell -a "ifconfig eth0:0"|grep 192.168.100.20;\
> ssh 192.168.100.11 "rm -rf /etc/keepalived/backup" ; \
> echo "==========================delete test file=====================================";
> sleep 4 ; \
> ansible lvsDirectors -m shell -a "ifconfig eth0:0"|grep 192.168.100.20;\
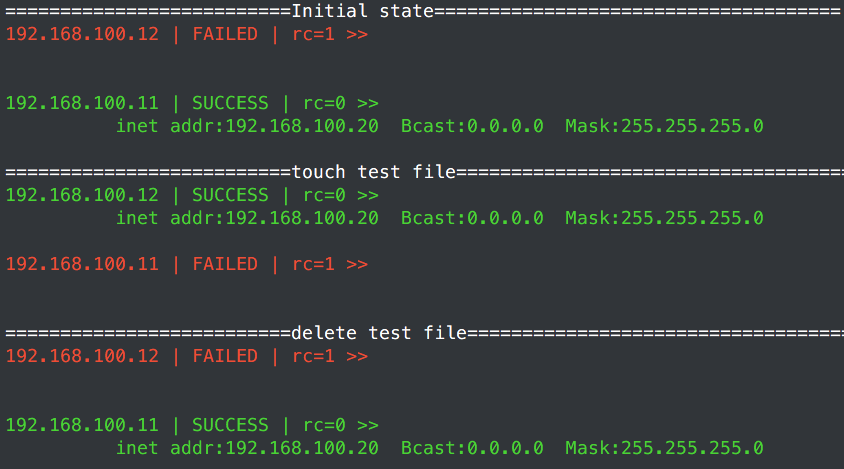
从建立backup文件和删除backup文件之后的效果,看的出来那个weight -2只是在脚本返回值为1时才会临时生效的配置。上面也是经过多次测试。发现需要4秒Master和Backup的角色才会转移(看IP转移),当然也不是100%,有一次过了4S还是没有转移,测试环境:基本相当于无任何干扰的虚拟网段。因为没有真实环境,所以这个测试意义也不大。所以读者要是应用在生产环境还需要自己进行测试
HA LVS.
定义一个Real Server。
virtual_server 192.168.200.100 443 { //定义VIP
delay_loop 6 //延迟几个周期再检测
lb_algo rr //调度算法
lb_kind NAT //LVS模式
nat_mask 255.255.255.0
persistence_timeout 50 //持久连接时长
protocol TCP //协议,好像只支持TCP
real_server 192.168.201.100 443 { //定义一个Real Server
weight 1 //权重
SSL_GET { //定义监控类型
url { //监控1
path / //路径
digest ff20ad2481f97b1754ef3e12ecd3a9cc //校验码
}
url { //监控2
path /mrtg/
digest 9b3a0c85a887a256d6939da88aabd8cd
}
connect_timeout 3 //连接超时时间
nb_get_retry 3 //尝试几次
delay_before_retry 3 //中间间隔几秒
}
}
监控类型分HTTP_GET|SSL_GET|TCP_CHECK|SMTP_CHECK|MISC_CHECK其中前面三种最常用
{HTTP_GET|SSL_GET} { //http和ssl都是给Web Server用的
url{
path /uri //资源路径
status_code 200 //除了上面的校验码,也可以使用响应码
}
connect_port <PORT> //端口,不指定默认使用real_server中定义IP
bindto <IPADDR> //IP地址,不指定默认使用real_server中所定义的IP
//还有三个就是上面介绍过的,其实省略的这2个也没什么卵用。
}
TCP_CHECK { //TCP检测只向对方发起TCP握手包,得到对方的ACK确认包即认为对方在线
connect_port <PORT>
bindto <IPADDR>
connect_timeout <INT> //差不多只有这个连接超时时长有用
}
定义2个Real Server。
- a、修改kernel参数
- b、安装Web Service
- c、建立Real Server测试页面。
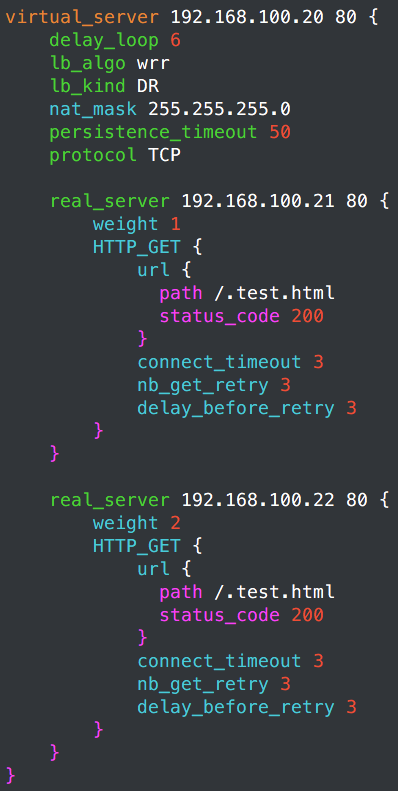
virtual_server 192.168.100.20 80 {
delay_loop 6
lb_algo wrr
lb_kind DR
nat_mask 255.255.255.0
persistence_timeout 50
protocol TCP
real_server 192.168.100.21 80 {
weight 1
HTTP_GET {
url {
path /.test.html
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 192.168.100.22 80 {
weight 2
HTTP_GET {
url {
path /.test.html
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
# ipvsadm -L -n
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.100.20:80 wrr persistent 50
-> 192.168.100.21:80 Route 1 0 0
-> 192.168.100.22:80 Route 2 0 0
从ipvs规则来看,正是之前定义的,我们去把.test.html移走移回,模拟宕机和修复,看监控会不会生效。
# ipvsadm -L -n //移走Real Server .test.html效果
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.100.20:80 wrr persistent 50
-> 192.168.100.21:80 Route 1 0 0
//自动下线满足,测试1次,2秒内下线。
# ipvsadm -L -n //移回Real Server .test.html效果
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.100.20:80 wrr persistent 50
-> 192.168.100.21:80 Route 1 0 0
-> 192.168.100.22:80 Route 2 0 0
//自动上线满足,测试一次,上线时间差不多6秒
因为只是做了一次测试,所以下线和上线的时间并不能给任何借鉴,如果对时间要求比较高的生产环境可以自行进行测试。
建立backup文件测试Director高可用。
# ipvsadm
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.100.20:http wrr persistent 50
-> 192.168.100.21:http Route 1 0 0
-> 192.168.100.22:http Route 2 0 0
还是没有任何问题,直接就转移了。keepalived针对LVS确实不是盖的。
通知机制
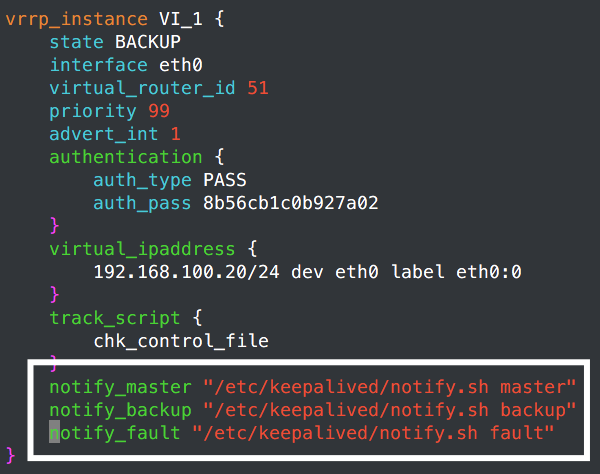
通知机制有2种 1、执行单个脚本
notify_master /path/to_master.sh //当当前node成为Master的时候,会执行后面这个脚本
notify_backup /path/to_backup.sh //成为Backup的时候
notify_fault /path/fault.sh //出故障的时候
2、能接受master,backup,fault参数
notify /etc/notify.sh
建立测试脚本测试一下
# cat /etc/keepalived/notify.sh
#!/bin/bash
#
#
vip=192.168.100.20
notifyForm=root@localhost
physicsIP=`ifconfig eth0 | awk -F":" '/inet addr/ {print $2}'|awk '{print $1}'`
notify() {
mailBody="`date '+%F %H:%M:%S'`:vrrp transaction,$pysicsIP changed to be $vip $1"
mailSubject="$physicsIP is to be $vip $1"
echo $mailBody | mail -s "$mailSubject" $notifyForm
}
case $1 in
master)
notify master
exit 0
;;
backup)
notify backup
exit 0
;;
fault)
notify fault
exit 0
;;
*)
echo "Usage: `basename $0` {master|backup|fault}"
exit 1
;;
esac
# chmod +x /etc/keepalived/notify.sh
在实例段进行调用:
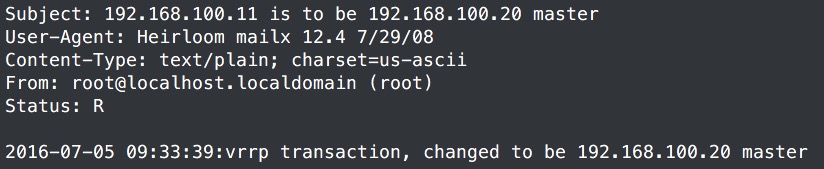
建立backup文件之后查看mail,
这样的话,因为会自动调用脚本,所以监控起来就简单了,短信,监控软件,mail。
使用keepalived使其它服务能高可用。
我这里使用Nginx做演示,因为测试脚本的原因,基本上任何service都可以进行这样的高可用。
这里演示node1比node2性能强场景:服务只要能运行在node1上面就不要运行到node2上面去。
更改notify.sh脚本。
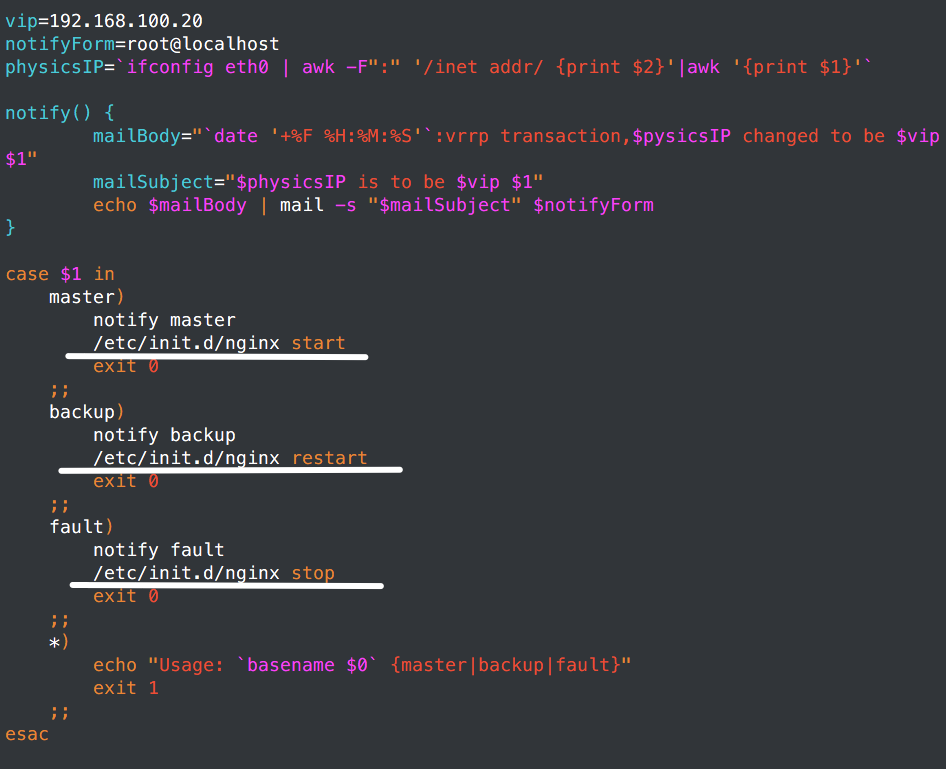
比上面就多了这3项,当然这个是node1,node2还是有所不同:
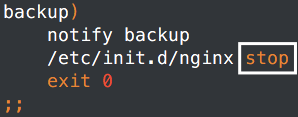
node1一旦成为buckup就会立马restart nginx,如果能启动,那么服务就转回,但是node2一旦成为buckup就需要stop nginx。当然如果2节点性能一致,又不是双Master模型。其实可以让node1成为backup的时候,也进行nginx stop。让资源停留在node2节点上面。不过这样手动修复node1之后,资源还是会转移到node1节点上面去,除非在主配置文件中使用如果监控到nginx启动,那么weight增加。
之后又修改了一下,stop有的时候不知道为啥停止不了
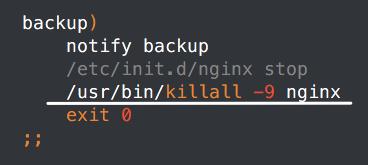
所有的stop都改成了killall
修改master主配置文件:

script测试方法(方法肯定很多,只列出下面简单且通用的):
1、pidof process
2、"server process status" or "systemctl status process"
3、killall -0 process
//测试一下,对照着上面的也应该会使用了
# service nginx status; \
> echo $? ;\
> killall -9 nginx; \
> service nginx status; \
> echo $?
nginx (pid 4780) is running...
0
nginx dead but pid file exists
1
这个buckup检测nginx status的脚本:
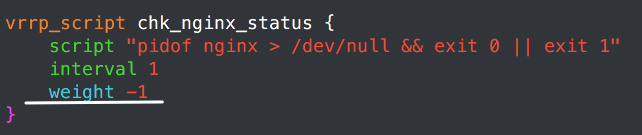
weight和上面减的不一样是因为node1开机就会成为master,然后就会启动nginx,其优先级就会是100,node2因为是backup节点,所以nginx会stop。其优先级会先减去weight,为98。当node1的nginx起不来,优先级就会是97,资源就会转移。如果2个节点weigeht减少的都一样,那么node1就算检测到Nginx停止工作,也无法成为backup,因为node2优先级至少要比node1少1,然后nginx就会死掉,集群也不会有任何其它的操作。
测试:
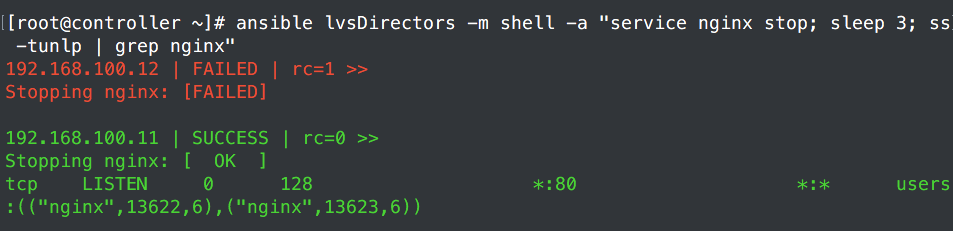
服务直接就起来了,再测试起不来的状态。将配置文件备份了。
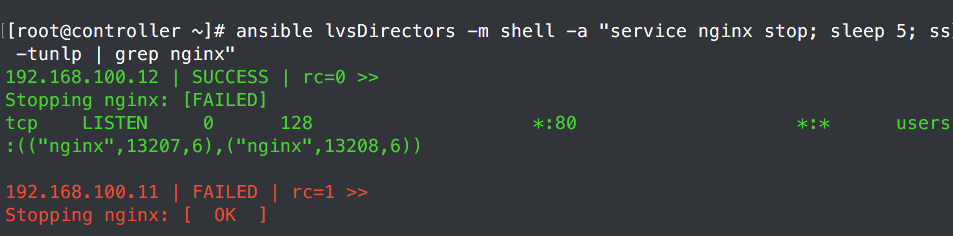
这次测试是5s之后再转移的,不过上面的restart的很快。
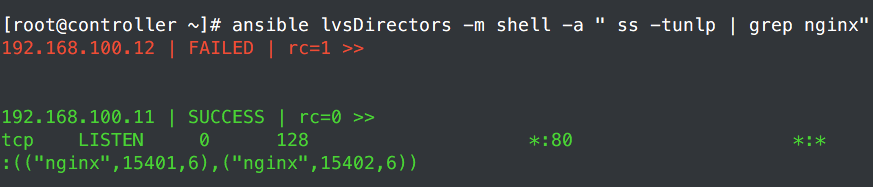
修复node1上面的nginx,启动之后资源自动转移回来。
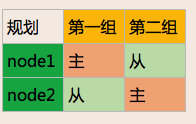
双Master模型
有的时候1台性能不够,只能用2台。这个时候就需要双主模型了。其实就是再定义一组资源。第一组node1为master,node2为backup,那么第二组就node1为backup,node为master。
配置nofity.sh脚本,这个时候就需要2组脚本,毕竟主备节点脚本不同。且2组脚本的vIP也不同。
主使用:
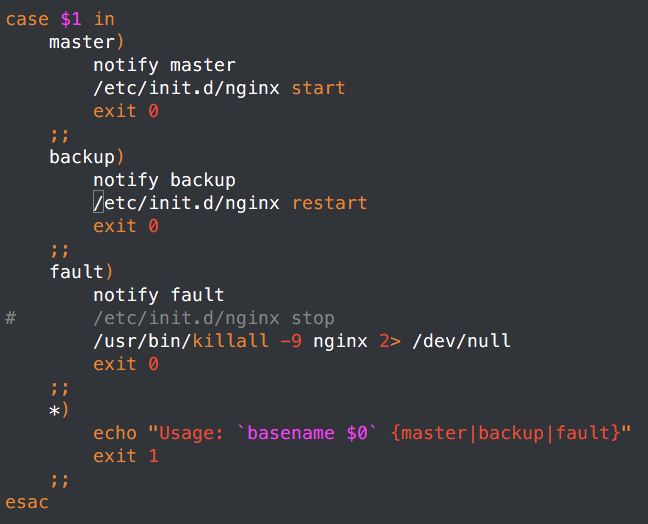
从使用:
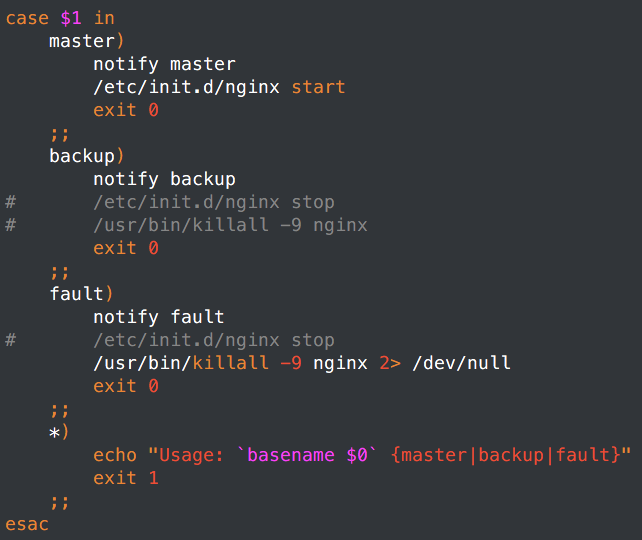
vIP另算。已经将另一组vIP给了192.168.100.30
node1:
vrrp_script chk_nginx_status {
script "pidof nginx >> /dev/null && exit 0 || exit 1"
interval 1
weight -2
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 8b56cb1c0b927a02
}
virtual_ipaddress {
192.168.100.20/24 dev eth0 label eth0:0
}
track_script {
chk_nginx_status
}
notify_master "/etc/keepalived/notify_1.sh master"
notify_backup "/etc/keepalived/notify_1.sh backup"
notify_fault "/etc/keepalived/notify_1.sh fault"
}
vrrp_instance VI_2 {
state BACKUP
interface eth0
virtual_router_id 52
priority 99
advert_int 1
authentication {
auth_type PASS
auth_pass 8b56cb1c0b927a02
}
virtual_ipaddress {
192.168.100.30/24 dev eth0 label eth0:1
}
track_script {
chk_nginx_status
}
notify_master "/etc/keepalived/notify_2.sh master"
notify_backup "/etc/keepalived/notify_2.sh backup"
notify_fault "/etc/keepalived/notify_2.sh fault"
}
node2:
vrrp_script chk_nginx_status {
script "pidof nginx > /dev/null && exit 0 || exit 1"
interval 1
weight -2
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 99
advert_int 1
authentication {
auth_type PASS
auth_pass 8b56cb1c0b927a02
}
virtual_ipaddress {
192.168.100.20/24 dev eth0 label eth0:0
}
track_script {
chk_nginx_status
}
notify_master "/etc/keepalived/notify_1.sh master"
notify_backup "/etc/keepalived/notify_1.sh backup"
notify_fault "/etc/keepalived/notify_1.sh fault"
}
vrrp_instance VI_2 {
state MASTER
interface eth0
virtual_router_id 52
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 8b56cb1c0b927a02
}
virtual_ipaddress {
192.168.100.30/24 dev eth0 label eth0:1
}
track_script {
chk_nginx_status
}
notify_master "/etc/keepalived/notify_2.sh master"
notify_backup "/etc/keepalived/notify_2.sh backup"
notify_fault "/etc/keepalived/notify_2.sh fault"
}
那我把重点列出来,这些都是修改过的或者是要对应的:
node1:
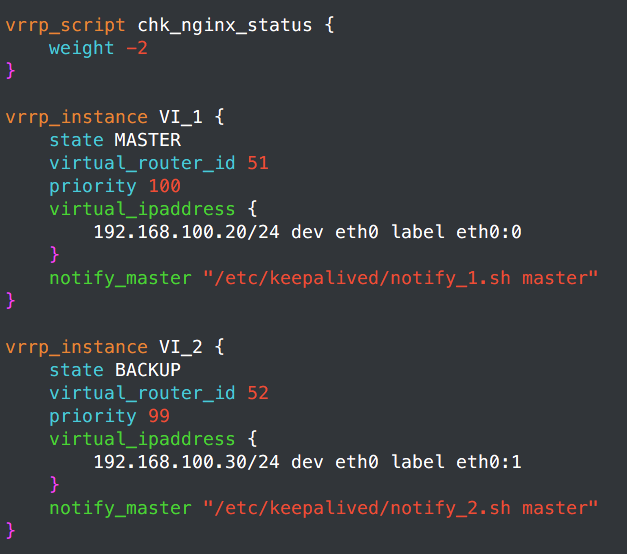
node2:

具体我也不扯了,就是把2个实例合并在一起,忒简单了。测试了一下,效果也和预料的差不多,2个节点都运行Nginx,并且倾向性都为只要当前节点不故障就不转移,Nginx可以这样,HAproxy也差不多。其它的也感觉不难实现,当然双主模型如果要使用的话,要使用DNS进行调度,让域名解析到2个vIP上面。