计算机的发展遵循”摩尔定律”已经多年,在计算机发展的同时,基于计算机的方方面面也在飞速发展,其中互联网的发展可以用变态来形容,而在这种发展下,数据量的增长几乎是几何式的,海量数据带来大量的问题,使用集中式存储已经完全不能满足需求了。这个时候就需要换一种方式,而最先出现这种需求的公司一般都是站在世界最前沿的公司,Google因为其搜索引擎爬来的海量数据,而不得不考虑将集中式存储改变成其他存储方式。在其研究出不少成果之后,Google发了一篇论文,名字叫做The Google File System,拉开了DFS(Distributed File System)的序章。
原文:https://github.com/chenyanshan/blog/blob/master/GFS.pdf
中文翻译版:https://github.com/chenyanshan/blog/blob/master/Google-File-System_CN.docx
大数据带来的挑战非常大。数据从TB级别到PB级别,其变换不亚于开车从100km/h到1000km/h。其中的变化根本就不是换一辆车能解决的事情,可能由人驾驶要换成机器驾驶,普通的道路要换成固定的轨道。甚至直接就把概念换掉了,由车到飞机了。换到大数据处理这里,对应的就是数据采集、数据存储、数据搜索、数据分析、数据可视化等,数据的变迁差不多和汽车速度的变迁是一样的。在这个阶段,存储就好像是汽车的发动机,发动机不解决了。其他方面再好再好。速度可能一直保持原速不变。分布式文件系统需要建立,就需要解决节点通信、数据存储、数据空间平衡、容错、文件系统支持等问题。然而分布式文件系统始终面临着缺乏全局时钟、面对故障的独立性、单点故障、事务等难点。
分布式文件系统设计目标:
- 访问透明
- 位置透明
- 并发透明
- 失效透明
- 可拓展性强
- 复制透明
- 迁移透明
CAP:
在理论计算机科学中,CAP定理(CAP theorem),又被称作布鲁尔定理(Brewer’s theorem),该定理由2000年被作为一个猜想提出,2002年被证实。它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistence) (所有节点在同一时间所访问到数据一致)
- 可用性(Availability)(每个请求都能获得最终的结果,就算是失败了)
- 分区容错性(Partition tolerance)(分布式系统在遇到任何网络分区故障的时候,仍然能够保证对外提供满足一致性和可用性的服务,除非是整个网络环境都发生了故障)
根据定理,分布式系统只能满足三项中的两项而不可能满足全部三项。对于分布式数据系统,分区容忍性是基本要求,下图中展示的NoSQL都是基于分区容错性,而在一致性和可用性中取舍。
- 关注一致性:系统可能因为故障而导致写操作失败
- 关注可用性:可能不能精确的读取到新写入的值
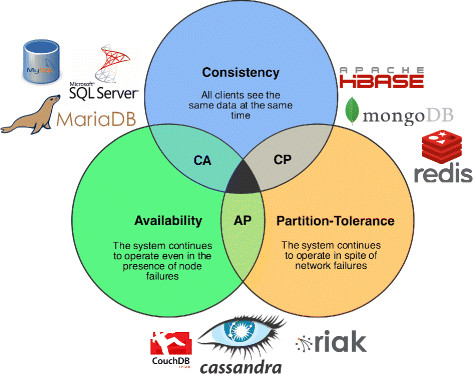
在不论分布式系统的情况下,大型网站对于可用性和分区容错性的优先级基本都高于数据一致性,一般都会朝着可用性和分区容错性的方向发展并使用其他手段保障数据一致性;
而不同的数据对数据一致性的要求也不同:
- 在商品评价就对数据一致性要求很低,一般不会造成太大的影响 - 商品价格和商品数量这些敏感数据对数据一致性要求就非常高。
DTP:Distributed Transcationn Processing Reference Model
分布式事务处理参考模型
定义了三个组件
- AP:Application Program 应用程序
- RM:Resourse Manager,资源管理器
- TM:Transaction Manager 事务管理器
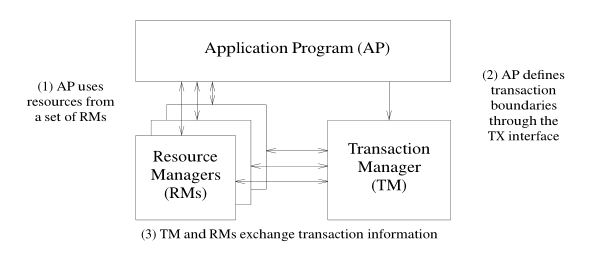
它们之间的关系为:
- AP通过TM来操作多个RM,AP也可以通过RM的本地事务接口来操作单个RM
- TM和RM可以互相通信,他们之前的通信协议就是XA协议
关系数据库的ACID模型拥有高一致性-可用性:
- Atomicity原子性:一次事务要么成功、要么失败,不能处于中间状态
- Consistency一致性:一旦一个事务完成,将来的所有事务都必须基于这个完成后的状态
- Isolation隔离层. 未完成的事务不会互相影响。
- Durability. 一旦事务完成,数据就会持久。
BASE模型完全不同ACID模型,它牺牲高一致性,获得可用性或可靠性:
- Basically Available 基本可用。支持分区失败
- Soft state 软状态 状态可以有一段时间不同步,异步
- Eventually consistent 最终一致,最终数据是一致的就可以了.
一致性:
可以通过Paxos算法(这里只拿其中一部分理论)得出:
- N:node 数据复制成功的节点数,基本相当于集群所有节点数
- R:read 成功完成读操作所依赖的最少节点数
- W:write 成功完成读操作所依赖的最少节点数
W+R>N
强一致性,在单机环境中,强一致性可以由数据库的ACID模型保证,在集群环境中,强一致性很难做到。因为分布式事务对网络要求高,比如MySQL复制中的主从同步复制。W=2,R=1,N=2.虽然实现了W+R>N,但是大大降低了MySQL的性能,不过也保证了数据的强一致
W+R<=N
弱一致性(包括最终一致性),也可以用MySQL的主从复制来表示,不过这个主从不是同步,而是异步。W=1,R=1,N=2.在数据同步量大或者主从服务器之间网络不佳的情况下,主从数据不一致很正常。不过让主的停止写,从的就会跟上主的,这个就叫最终一致
为了保障分布式系统的高可用,一般N>=3。
- 如果N=W,R=1,任何一个写节点失效,都会导致写失败,因此可用性会降低,但是由于数据分布的N个节点是同步写入的,因此可以保证强一致性。
- 如果N=R,W=1,只需要一个节点写入成功即可,写性能和可用性都比较高。但是读取其他节点的进程可能不能获取更新后的数据,因此是弱一致性。这种情况下,如果W<(N+1)/2,并且写入的节点不重叠的话,则会存在写冲突
分布式存储:
现有的分布式存储基本是由GFS发展而来,GFS全名Google File System。当然GFS也值集中式文件系统,为什么说都是由GFS发展而来呢,这是因为现有的所以的分布式存储或者分布式文件系统的理论架构都是Google在2003年发布的The Google File System论文。
主流的分布式文件系统
- GFS: Google File System
- HDFS: Hdoop File System:适合存储海量大文件
- TFS: Taobao File System:适合存储海量小文件
- GlusterFS: 适合存储PB级别企业级数据。可以实现上千台节点同时访问
- MogileFS: 适合存储海量小文件
- FastDFS: 国内实现的MogileFS的C语言clone版,元数据存放在内存中