MySQL Replication的实现 MySQL的复制功能是MySQL成为开源(Open Source) DBMS中最重要的功能。虽然实现不难,但是这是实现MySQL集群的基本功能。MySQL的集群基本是由复制功能实现的。
我在之前就说过复制的原理了,在这里就不扯了。直接讲配置方法
-、Master-Slave模型
Master-Slave是最常见的模型之一,当然这个也包括一主多从架构。
优点
-使用一个或者多个从来降低读压力,这样就会大大提升MySQL的性能。特别是读多写少的场景,Master只负责写入数据(数据只能由Maste复制),其他Slave复制响应请求,当然这种读写分离就需要前端有读写分离器来完成。
缺点
- 一主模型主永远都是单点故障点(以后介绍高可用,或者叫冗余),在数据规模较大场景,一旦主节点宕机,从服务器肯定会出现数据丢失,这是因为Master和Slave之前永远都是Dump和I/O thread这一条线连接(可以使用同步复制或者是GTID来实现数据规模很大的场景的快速同步),数据量大的时候,单线程肯定不能迅速将完成对资源快速复制。而且当Master宕机之后。整个系统还无法响应写请求
Master的配置
- 修改主配文件/etc/my.cnf
- log-bin=/二进制日志存放地点(记得权限)
- binglog-format=二进制日志格式
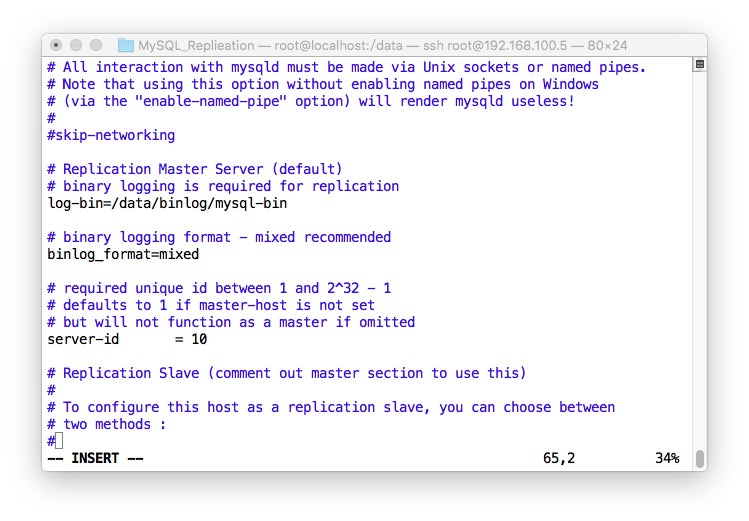
- 重启MySQL的,加入复制用户并刷新权限
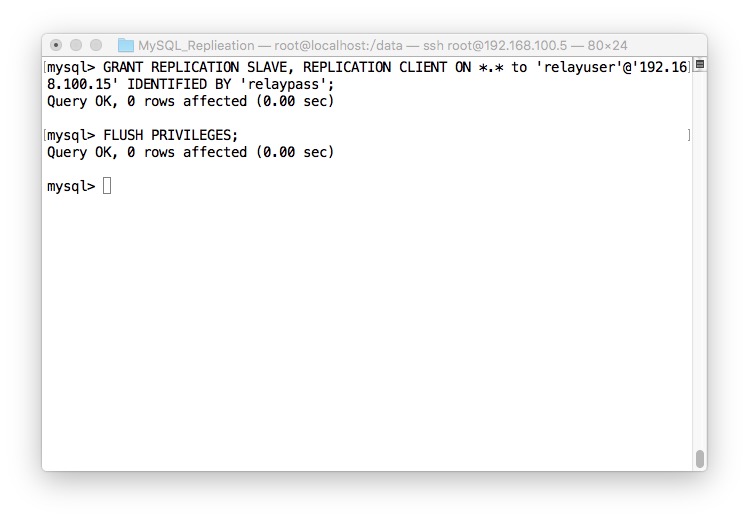
Slave的配置
- 修改主配文件
- relay-log = /复制日志存放地(记得权限)
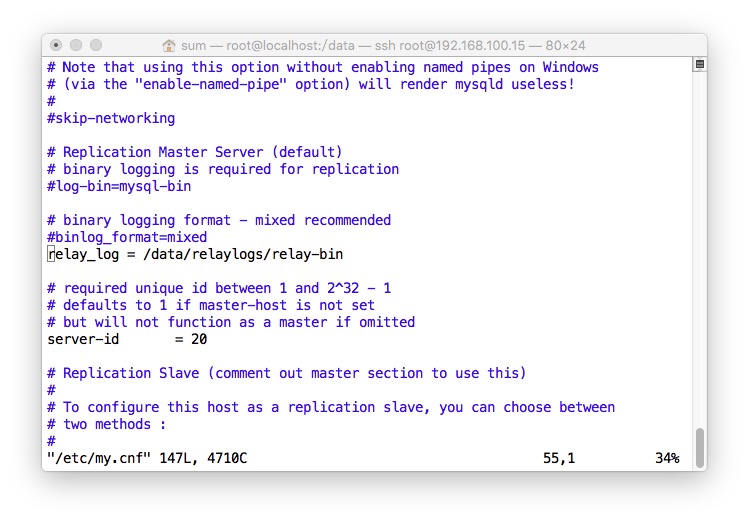
- 连接Master,用在Master创建的userName和passWord
- 输入START SLAVER;以启动I/O thread和SQL thread.(忘记截图了)
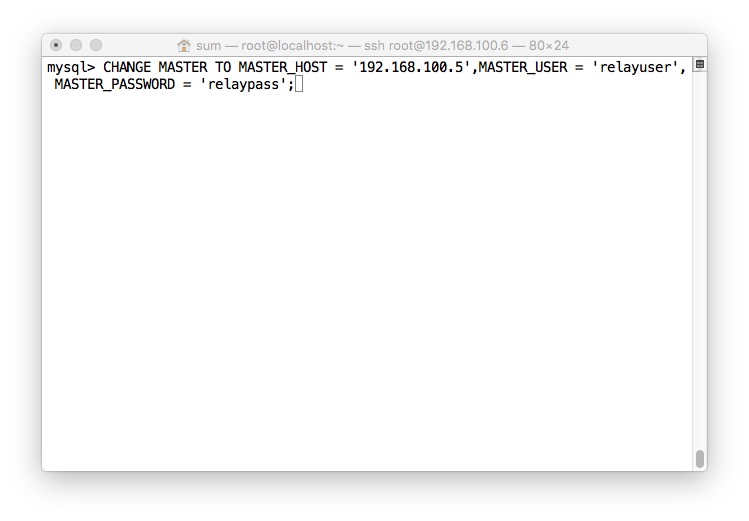
- 查看relay日志等设置
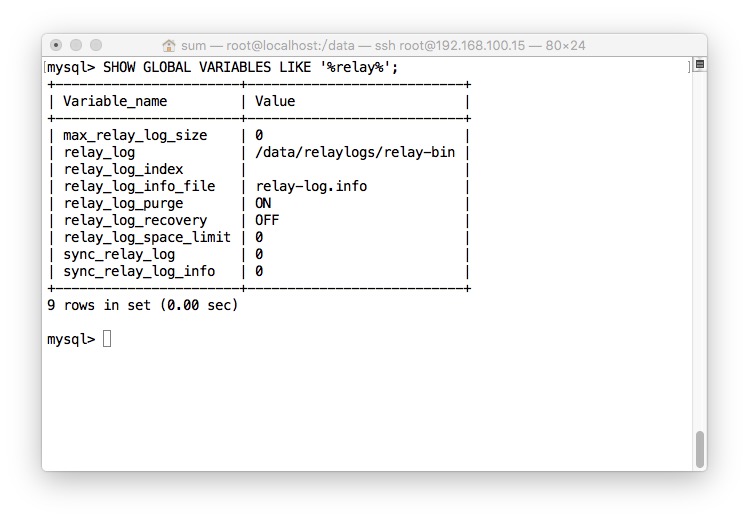
- 查看复制的详细信息
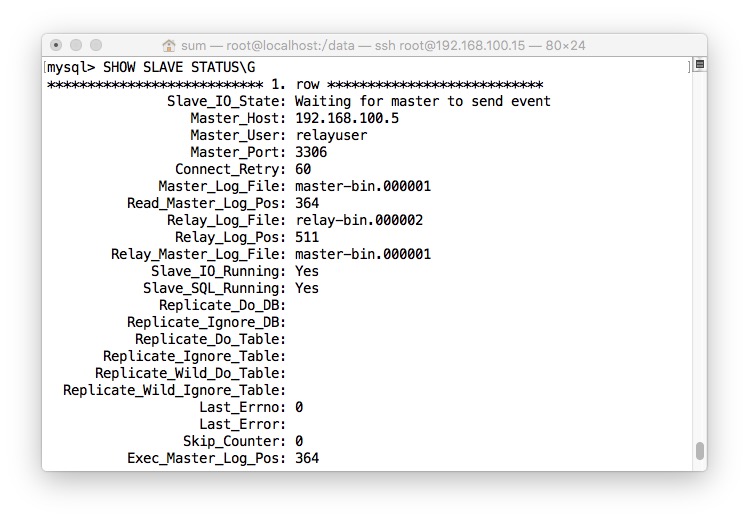
- 效果,因为数据太小,我在Master刚一写入,Slave就同步了
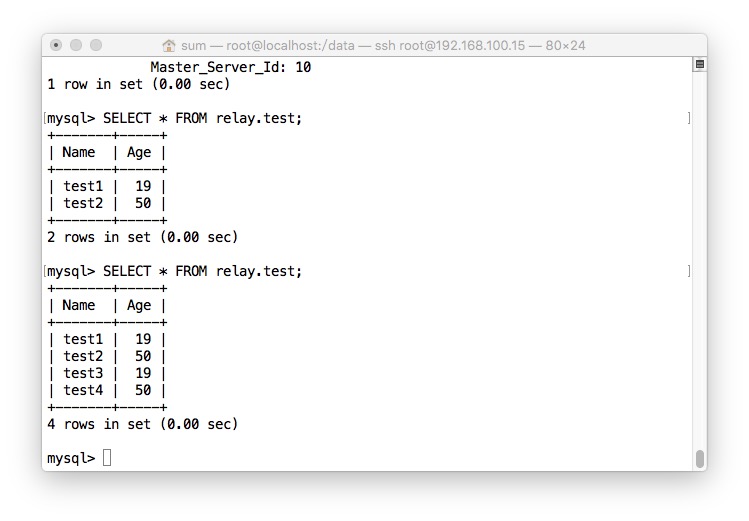
一从多主就和上面一样,就不介绍了。
Slave是不能够执行写操作的,一旦写了数据,Master肯定是不能同步的,所以整个集群就会数据的不一致,
在Slave上启动read-only=ON,这样可以限制那不具有super权限的用户无法执行写操作
二、半同步复制
半同步复制是Google回馈给MySQL的插件,能够实现主从架构中。手动指定哪些Slave是同步复制,哪些是异步复制,这样就可以实现和Master在一个机房的Slave使用同步复制Master的数据。这样不会太影响时间,并且,当Master宕机后,同步复制的这台Slave可以直接上来顶替Master的位置,只需要将IP改一下,并给予写权限(以后开篇详细讲)。
在主从复制已经配置完成的情况下,配置半同步
- Maste上面安装插件并启用插件
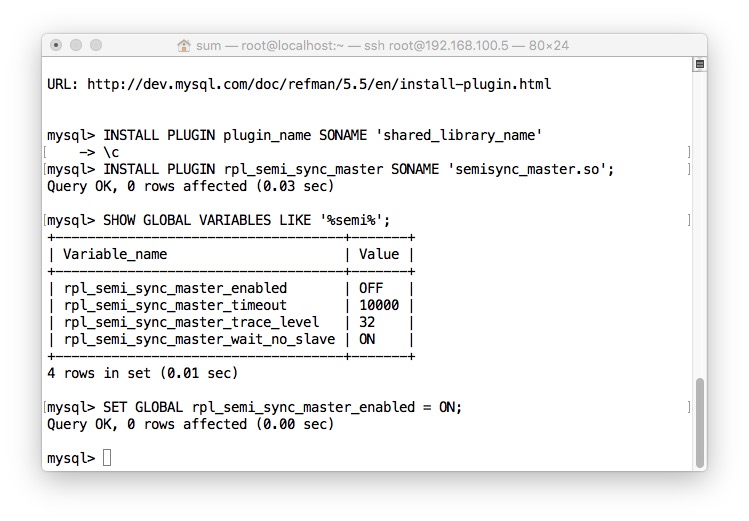
- Slave安装插件,并启用插件
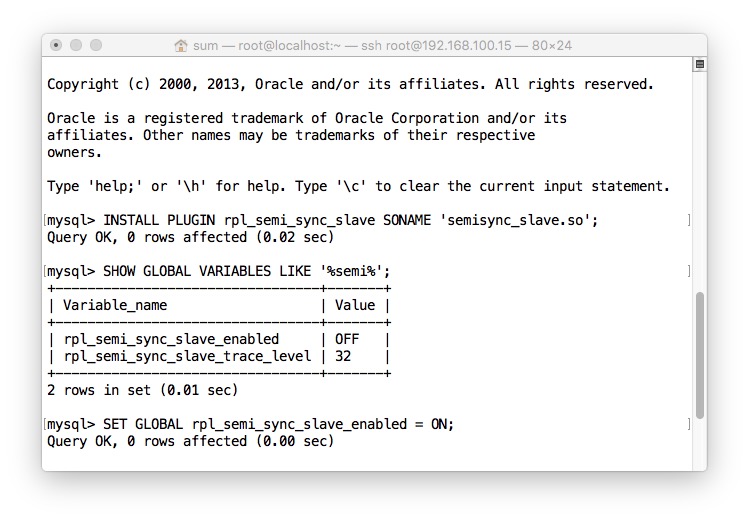
- Slave上面重启
IO_THREAD
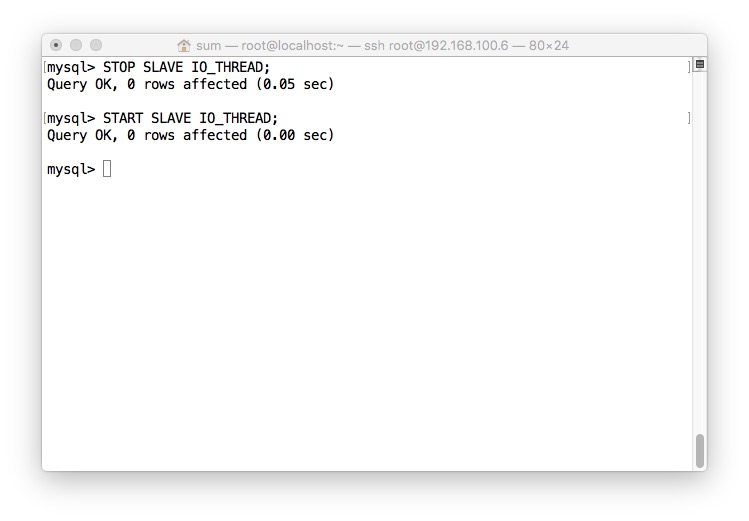
- Maste查看状态
- 好了,现在已经是成功状态了,同步原理前面已经提过了
- 卸载方法
三、复制过滤器
复制过滤器是用来限制过滤的黑白名单的
方法:在主配文件[mysqld]里面配置,do是白名单,ignore是黑名单
- Master
- binlog_do_db=
- binlog_ignore_db=
- slave
- replicate_do_db =
- replicate_ignore_db =
- replicate_do_table = db_name.table_name
- replicate_ignore_db = db_name.table_name
- replicate_wild_do_table = 正则
- replicate_wild_igonre_table = 正则
Master里面设置黑白名单会有问题,不建议使用,原因自己百度。
Slave里面正则匹配的方式最为精确
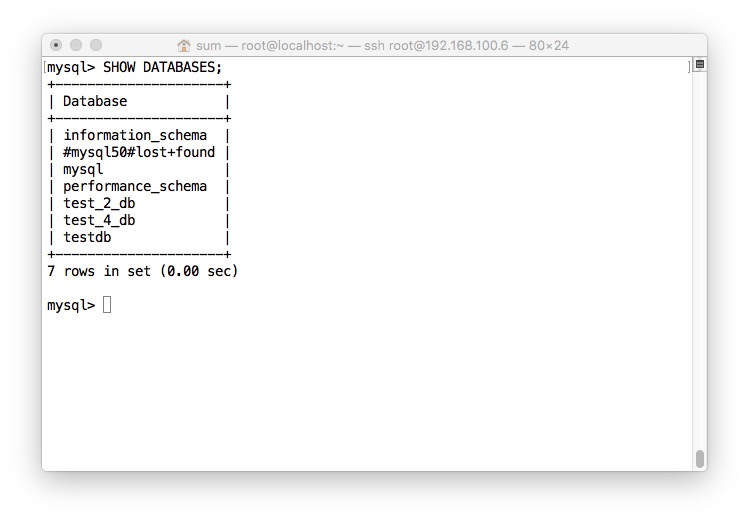
- 在Slave里面设置黑名单并重启数据库使其生效
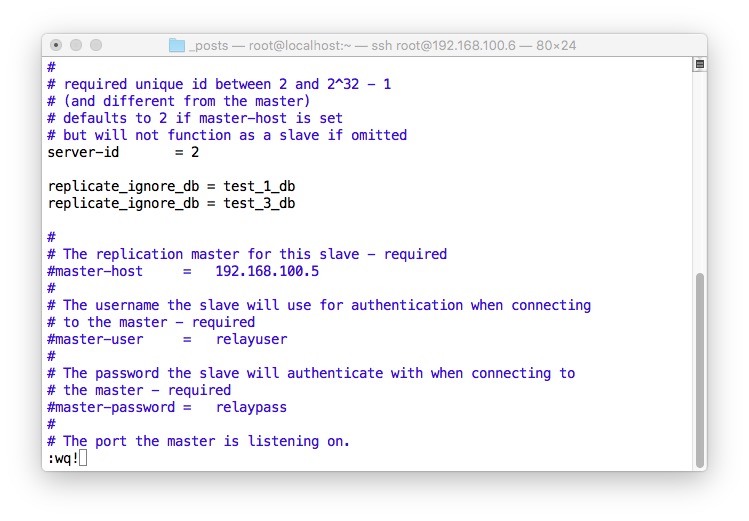
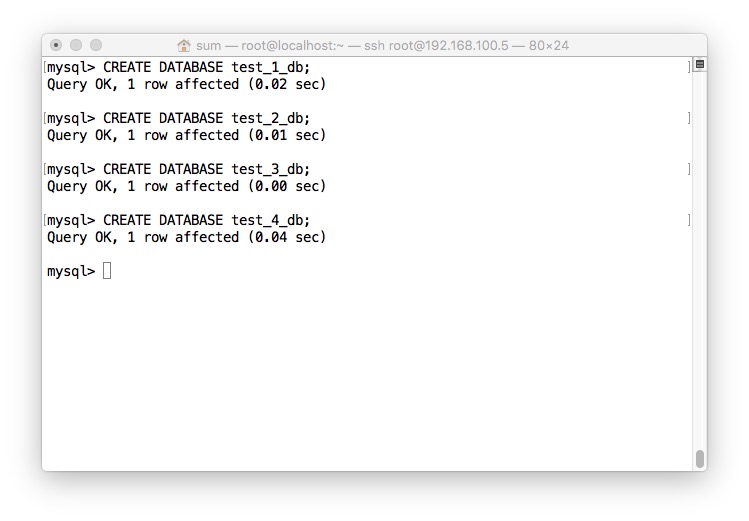
- Master创建测试库
- Slave查看效果
四、Multi-Master模型
双主模型在MySQL集群里面特别常见,当然是和Master-Slave结合一起使用,形成双主多从,我们这里不讲双主多从的实现(设计到高可用,以后再说),只讲Multi-Master的实现,Multi-Master说白了就是互为主从,直接把上面Master-Slave配置再反过来配置一遍就可以了。 标准的Multi-Master在一种情况绝对会出问题:
>SELECT * FROM testdb.table
col1 col2
1 1
当一个服务器讲col2的值当条件对col1的值进行处理
>UPDATA tables SET col1 = 2 WHERE col2 = 1;
而另一个服务器却正在用col1的值对col2进行操作
>UPDATA tables SET col2 = 2 WHERE col1 = 1;
这个时候就会出现数据不一致的情况
这个时候就需要使用监控程序来监控然后自己再进行手动修复
配置
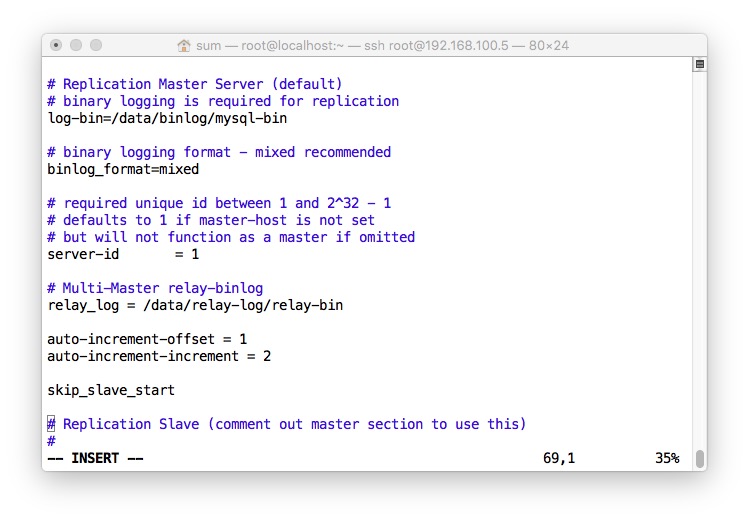
/etc/my.cnf配置
server-id必须不同,双主模型下,二进制数据都一样,怎么判断哪个需要重放?
这个时候就需要server-id来确定哪些是自己操作过的,哪些只在对方服务器上面进行过操作
auto-increment-offset : 对于auto-increment的数据来说,2边都同时从1开始计数,
这个时候就乱套了,所以就使用了不同的起点,一般来说在Multi-Master里面,一个为1,一个为2
auto-increment-incrment :步长,除了起步点不同之外,步长也需要调节,步长都是1的话,还是会重叠,
当步长为2的时候,前一个master增长为1357,后一个增长为2468,完全不会冲突
skip_slave_start : 跳过自启动slave,改为手动启动,slaveyou 的时候需要指定一些具体数值
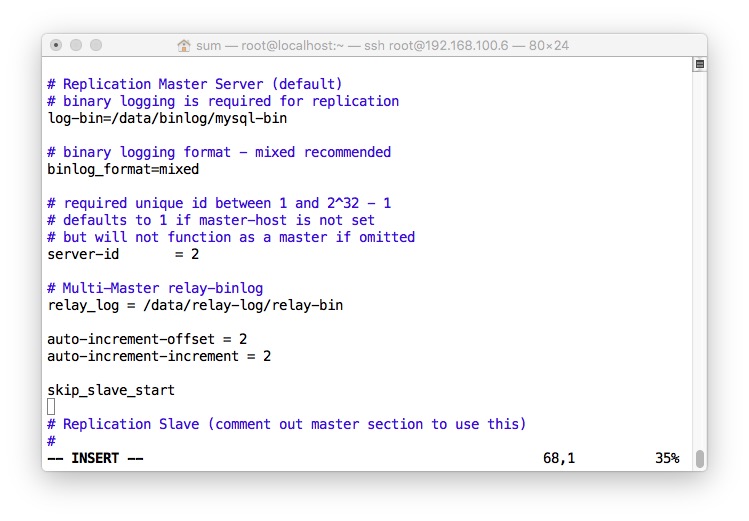
- 两边都创建用户
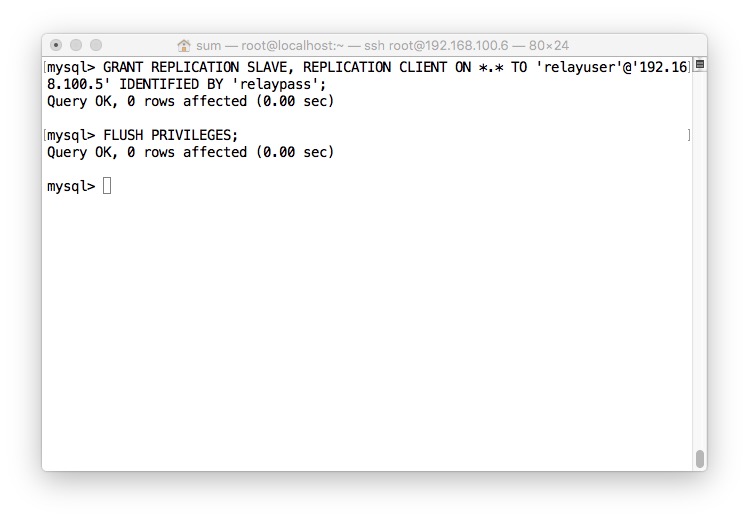
- 下面这张图片是为了方便才这么截图的,第二条命令中的值是第一条命令,但是两条并不在同一个服务器上面执行,第一个在第一个服务器上面执行后,第二条是给另一个服务器用的,反之亦然,
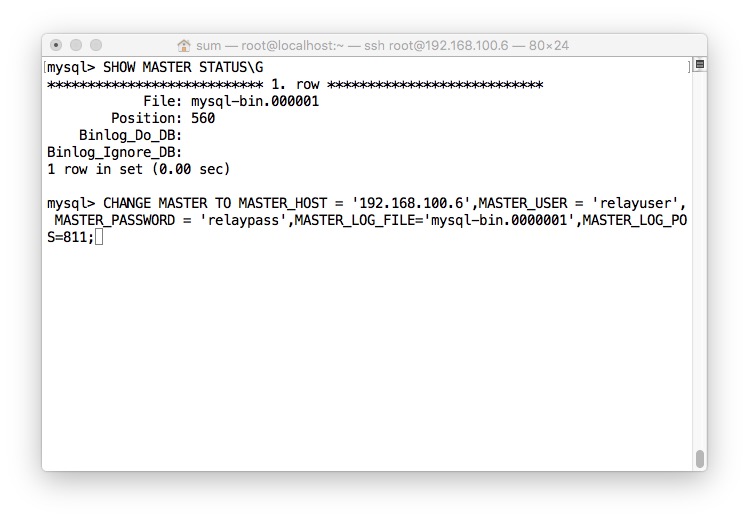
- 查看状态,2边都需要查看
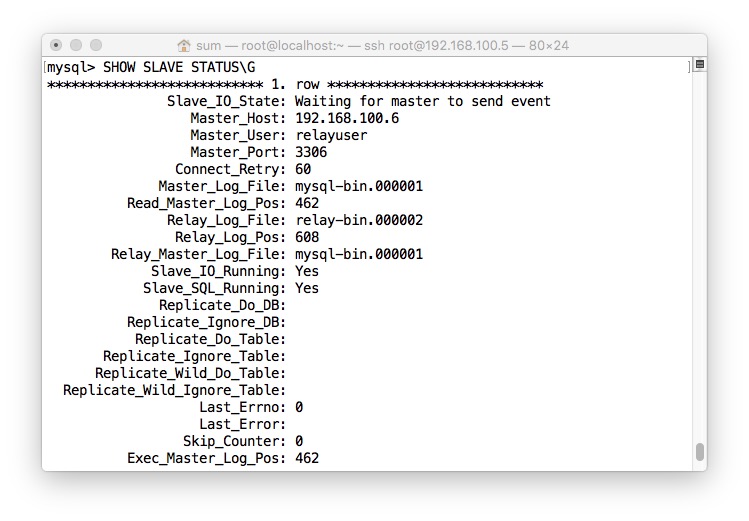
- 完成,基本上这样随便在哪台服务器上面写。在另一条服务器上面都能立马同步
这只是MySQL的基础架构,还有高可用和负载均衡没有进行实现。有时间再写。写的特别烂,可能是因为个人不太会总结归纳和分点,细节遗漏的比较多,如果还是处于学习阶段,看下倒是可以,要是真正部署了,还是先要去实验实验再上。