长期以来,基于 Netfilter 的 kube-proxy 都是 Kubernetes 服务网络的标准实现。但随着 eBPF 技术演进为强大的内核网络引擎,一个新机遇随之而来:我们能否彻底绕开 kube-proxy?Cilium 以其 eBPF 方案给出了肯定答案。实际上,绕过 Netfilter 本就是 Cilium 的一贯设计思路,此次替代方案亦不例外。它通过 Socket-LB 与 DSR 技术,在内核的 Socket 层构建了一套更高性能的负载均衡模型,为我们揭示了 K8s 网络的新可能。
文中只提及了 Cilium 替代 Kube-Proxy 的核心原理,使用指南请参考官方文档: Kubernetes Without kube-proxy
一、传统 Kube-Proxy
Kube-Proxy 基本历经三个阶段:
- 用户空间进程实现(已被弃用)。
- 内核 Netfilter 实现匹配以及 NAT 。
- 工作原理:
kube-proxy在iptables模式下,会为集群中的每一个 Service 创建一系列iptables规则链。当一个请求到达节点的网络接口时,它需要顺序遍历这些iptables规则,直到找到匹配的规则,然后将流量 DNAT 到后端的一个 Pod IP。 - 复杂度:这种工作方式的算法复杂度是线性的,即 O(n),其中 “n” 是 Service 和 Endpoint 的数量。随着集群规模(特别是 Service 数量)的增长,
iptables规则会变得非常庞大,导致内核在处理每个网络包时都需要进行大量的计算和匹配,从而增加网络延迟并消耗更多 CPU。
- 工作原理:
- IPVS 实现
- 工作原理:
IPVS模式下,使用 哈希表(Hash Table) 作为其底层数据结构来存储 Service 和后端 Pod 的映射关系。当请求到达时,IPVS 可以通过一次哈希查找快速定位到对应的后端服务,其效率远高于iptables的线性扫描。 - 复杂度:IPVS 的算法复杂度接近于常数时间,即 O(1)。这意味着无论集群中有多少个 Service,其转发性能几乎不受影响,提供了极佳的可伸缩性。
- NodePort/SNAT: 还是依赖 iptables 实现。
- 工作原理:
二、Socket-LB
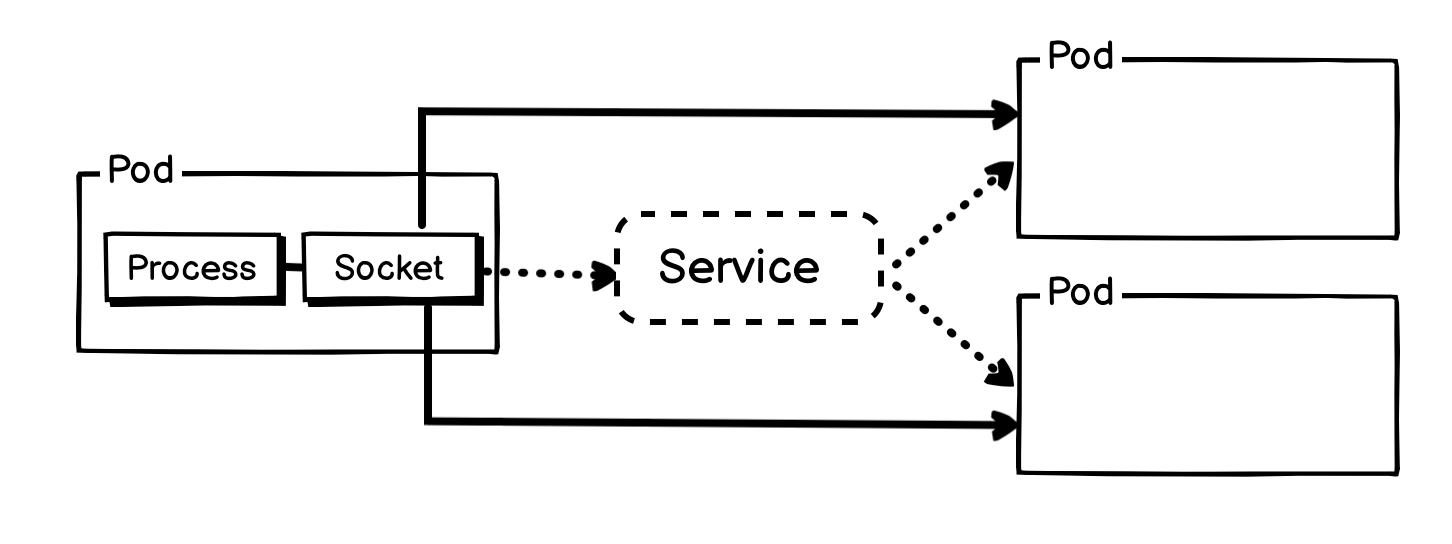
1. SocketLB (基于套接字的负载均衡)
SocketLB 专门处理一种场景:集群内的 Pod 访问一个 Kubernetes Service(通常称为东西向流量)。
工作原理:
-
挂载点 (Hook Point): 它使用一个 eBPF 程序,挂载在
socket操作相关的内核函数上,比如connect()系统调用。 -
拦截与转换:
当一个 Pod 内的应用程序(比如
curl my-service) 尝试与一个 Service IP (ClusterIP) 建立连接时:connect()系统调用被触发。- 挂载在
connect()上的 eBPF 程序被激活。 - 这个 eBPF 程序会识别出目标 IP 是一个 Service IP。
- 它会查询 eBPF map,找到该 Service 对应的所有健康后端 Pods。
- 通过负载均衡算法(如随机、轮询)选择一个具体的
Pod IP。 - 在内核将要为这个连接建立网络数据包之前,直接修改
socket结构体中的目标地址,将其从Service IP无缝替换为选定的Pod IP。
-
结果: 应用程序以为自己在连接
Service IP,但实际上内核后续建立的 TCP 连接直接就是Pod -> Pod的。
请求 Pod 抓包,可以看到 DNS 还是正常请求,但是本来应该请求到 Service IP 的流量,直接转到目标 Pod 上面。
- 源 Pod IP: 10.0.0.106
- 目标 Pod IP: 10.0.1.123
- Service IP: 10.96.156.172
net-pod1:~# tcpdump -pne -i eth0
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
09:01:51.687720 da:41:5e:f3:ba:55 > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 10.0.0.99 tell 10.0.0.106, length 28
09:01:51.687735 72:6a:f4:a8:b3:2d > da:41:5e:f3:ba:55, ethertype ARP (0x0806), length 42: Reply 10.0.0.99 is-at 72:6a:f4:a8:b3:2d, length 28
09:01:51.687739 da:41:5e:f3:ba:55 > 72:6a:f4:a8:b3:2d, ethertype IPv4 (0x0800), length 102: 10.0.0.106.52148 > 10.0.0.184.53: 13898+ [1au] A? nginx.default.svc.cluster.local. (60)
09:01:51.687832 da:41:5e:f3:ba:55 > 72:6a:f4:a8:b3:2d, ethertype IPv4 (0x0800), length 102: 10.0.0.106.52148 > 10.0.0.184.53: 31087+ [1au] AAAA? nginx.default.svc.cluster.local. (60)
09:01:51.688194 72:6a:f4:a8:b3:2d > da:41:5e:f3:ba:55, ethertype IPv4 (0x0800), length 195: 10.0.0.184.53 > 10.0.0.106.52148: 31087*- 0/1/1 (153)
09:01:51.688445 72:6a:f4:a8:b3:2d > da:41:5e:f3:ba:55, ethertype IPv4 (0x0800), length 149: 10.0.0.184.53 > 10.0.0.106.52148: 13898*- 1/0/1 A 10.96.156.172 (107)
09:01:51.688655 da:41:5e:f3:ba:55 > 72:6a:f4:a8:b3:2d, ethertype IPv4 (0x0800), length 74: 10.0.0.106.60592 > 10.0.1.123.80: Flags [S], seq 18963605, win 64240, options [mss 1460,sackOK,TS val 2386644761 ecr 0,nop,wscale 7], length 0
09:01:51.688892 72:6a:f4:a8:b3:2d > da:41:5e:f3:ba:55, ethertype IPv4 (0x0800), length 74: 10.0.1.123.80 > 10.0.0.106.60592: Flags [S.], seq 3789997924, ack 18963606, win 65160, options [mss 1460,sackOK,TS val 1771901782 ecr 2386644761,nop,wscale 7], length 0
09:01:51.688903 da:41:5e:f3:ba:55 > 72:6a:f4:a8:b3:2d, ethertype IPv4 (0x0800), length 66: 10.0.0.106.60592 > 10.0.1.123.80: Flags [.], ack 1, win 502, options [nop,nop,TS val 2386644761 ecr 1771901782], length 0
09:01:51.689340 da:41:5e:f3:ba:55 > 72:6a:f4:a8:b3:2d, ethertype IPv4 (0x0800), length 134: 10.0.0.106.60592 > 10.0.1.123.80: Flags [P.], seq 1:69, ack 1, win 502, options [nop,nop,TS val 2386644761 ecr 1771901782], length 68: HTTP: GET / HTTP/1.1
09:01:51.689495 72:6a:f4:a8:b3:2d > da:41:5e:f3:ba:55, ethertype IPv4 (0x0800), length 66: 10.0.1.123.80 > 10.0.0.106.60592: Flags [.], ack 69, win 509, options [nop,nop,TS val 1771901782 ecr 2386644761], length 0
09:01:51.689777 72:6a:f4:a8:b3:2d > da:41:5e:f3:ba:55, ethertype IPv4 (0x0800), length 304: 10.0.1.123.80 > 10.0.0.106.60592: Flags [P.], seq 1:239, ack 69, win 509, options [nop,nop,TS val 1771901783 ecr 2386644761], length 238: HTTP: HTTP/1.1 200 OK
09:01:51.690097 72:6a:f4:a8:b3:2d > da:41:5e:f3:ba:55, ethertype IPv4 (0x0800), length 681: 10.0.1.123.80 > 10.0.0.106.60592: Flags [P.], seq 239:854, ack 69, win 509, options [nop,nop,TS val 1771901783 ecr 2386644761], length 615: HTTP
09:01:51.690167 da:41:5e:f3:ba:55 > 72:6a:f4:a8:b3:2d, ethertype IPv4 (0x0800), length 66: 10.0.0.106.60592 > 10.0.1.123.80: Flags [.], ack 854, win 496, options [nop,nop,TS val 2386644762 ecr 1771901783], length 0
09:01:51.690611 da:41:5e:f3:ba:55 > 72:6a:f4:a8:b3:2d, ethertype IPv4 (0x0800), length 66: 10.0.0.106.60592 > 10.0.1.123.80: Flags [F.], seq 69, ack 854, win 501, options [nop,nop,TS val 2386644763 ecr 1771901783], length 0
09:01:51.690802 72:6a:f4:a8:b3:2d > da:41:5e:f3:ba:55, ethertype IPv4 (0x0800), length 66: 10.0.1.123.80 > 10.0.0.106.60592: Flags [F.], seq 854, ack 70, win 509, options [nop,nop,TS val 1771901784 ecr 2386644763], length 0
09:01:51.690809 da:41:5e:f3:ba:55 > 72:6a:f4:a8:b3:2d, ethertype IPv4 (0x0800), length 66: 10.0.0.106.60592 > 10.0.1.123.80: Flags [.], ack 855, win 501, options [nop,nop,TS val 2386644763 ecr 1771901784], length 0
简单描述就是 Socket-LB 就是 Pod 内的应用程序在准备创建 Socket 的时候,调用一段 eBPF 函数,在 socket 层将 Service IP 替换为 Pod IP
这样做有什么好处?
Cilium 利用 eBPF 技术优化 Pod 间流量路径,旨在绕过内核中效率较低的 Netfilter。然而,在 Kubernetes 集群中,大部分流量都通过 Service 转发,而 Service 的实现恰恰依赖于 Netfilter。
这就导致了一个核心矛盾:即便 Cilium 在底层优化了网络路径,但只要流量经过 Service,就必须回到内核协议栈由 Netfilter 处理,这使得 Cilium 此前绕过内核 Netfilter 的努力付诸东流。
所以 Socket-LB 特性对于不使用 eBPF 的 CNI 来说可能并无特别大的作用,但是在 Cilium 中,却是性能提升的核心特性(Calico 中也有类似实现方案)。
2. 宿主机名称空间的 Service 转 Pod IP 特性
有的时候 Pod 内部会依赖 Service 做一些自定义操作,例如 Istio Sidecar 模式,其 envoy-proxy sidecar ,Listener 监听就是 Service IP ,如果 Cilium 在业务 Pod 访问的时候把 Service IP 替换成了 Pod IP ,那么 Istio 就无法劫持和管理访问 Service 的流量。
还有的情况是,如果采用一些特殊的容器运行时(例如 KubeVirt、Kata Containers、gVisor),也会使得 socket-lb 无法工作。
这种情况下,Cilium 提供了另外一种方案,就是在 veth-pair 侧的 TC Hook 执行 Service 到 Pod 的转变,即,在 from_container 除执行 DNAT 。
启用参数: --set socketLB.hostNamespaceOnly=true
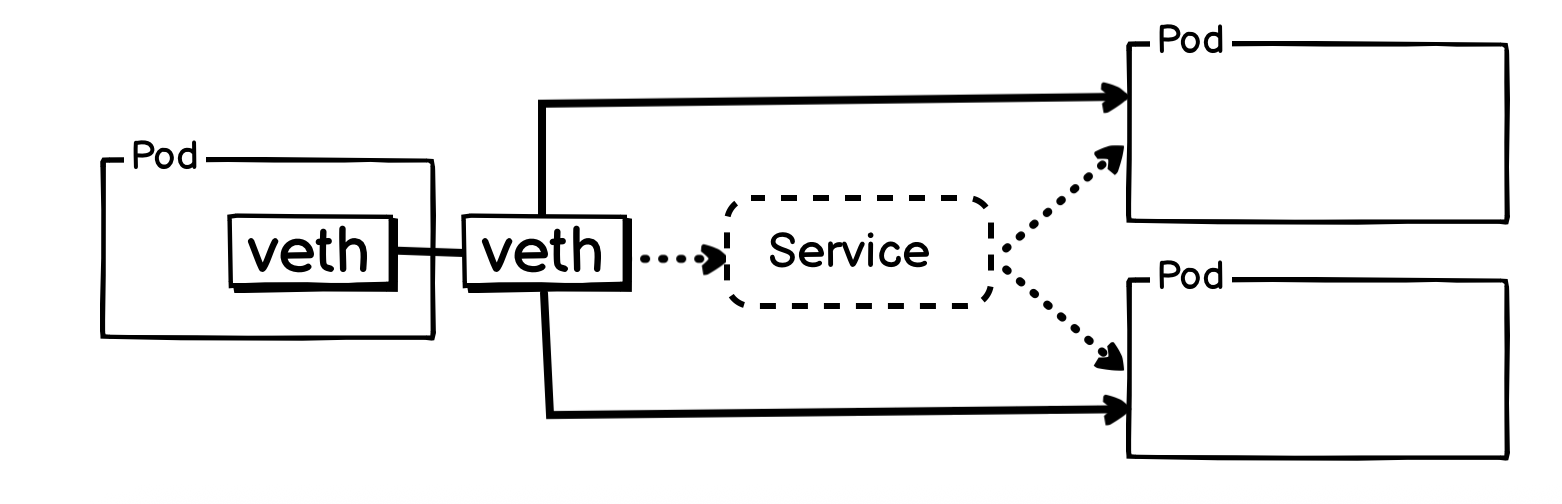
严格来说,此方案只是把 Service 的实现往数据路径的更前端挪动了些,从宿主机网络协议栈,挪动到了 Pod 的 veth-paic 宿主机侧网卡的 TC Hook Ingress 处。不过这样也能实现跳过内核协议栈的路径优化。
二、Cilium kubeProxyReplacement
Cilium 在安装的时候可以指定 loadBalancer.mode,一共有4种,dsr 、 snat 、 annotation 和 hybrid,默认是snat。
-
snat: 由 eBPF 实现的,与传统的 kube-proxy NodePort 类似的流量路径。 -
dsr: 直接服务器返回,基本是由 eBPF 实现的 LVS-DR 模式。 -
hybrid: 混合模式,即 TCP 用dsr,UDP用snat正常情况下,DSR 会在 TCP 建立的第一个报文,SYN 报文中增加额外信息,来向目标端通告这个 TCP 连接的 Service 信息,以便服务响应端在返回数据的时候,使用 Service 信息作为源 IP 信息返回。
但是 UDP 不同,UDP 没有连接概念,每个报文都需要添加额外信息,这是需要降低 MTU 实现的。
-
annotation: 基于注解的 DSR 和 SNAT 模式,也就是说,服务可以通过默认的 SNAT 模式暴露,也可以在需要时通过 DSR 模式暴露(反之亦然)
SNAT 模式
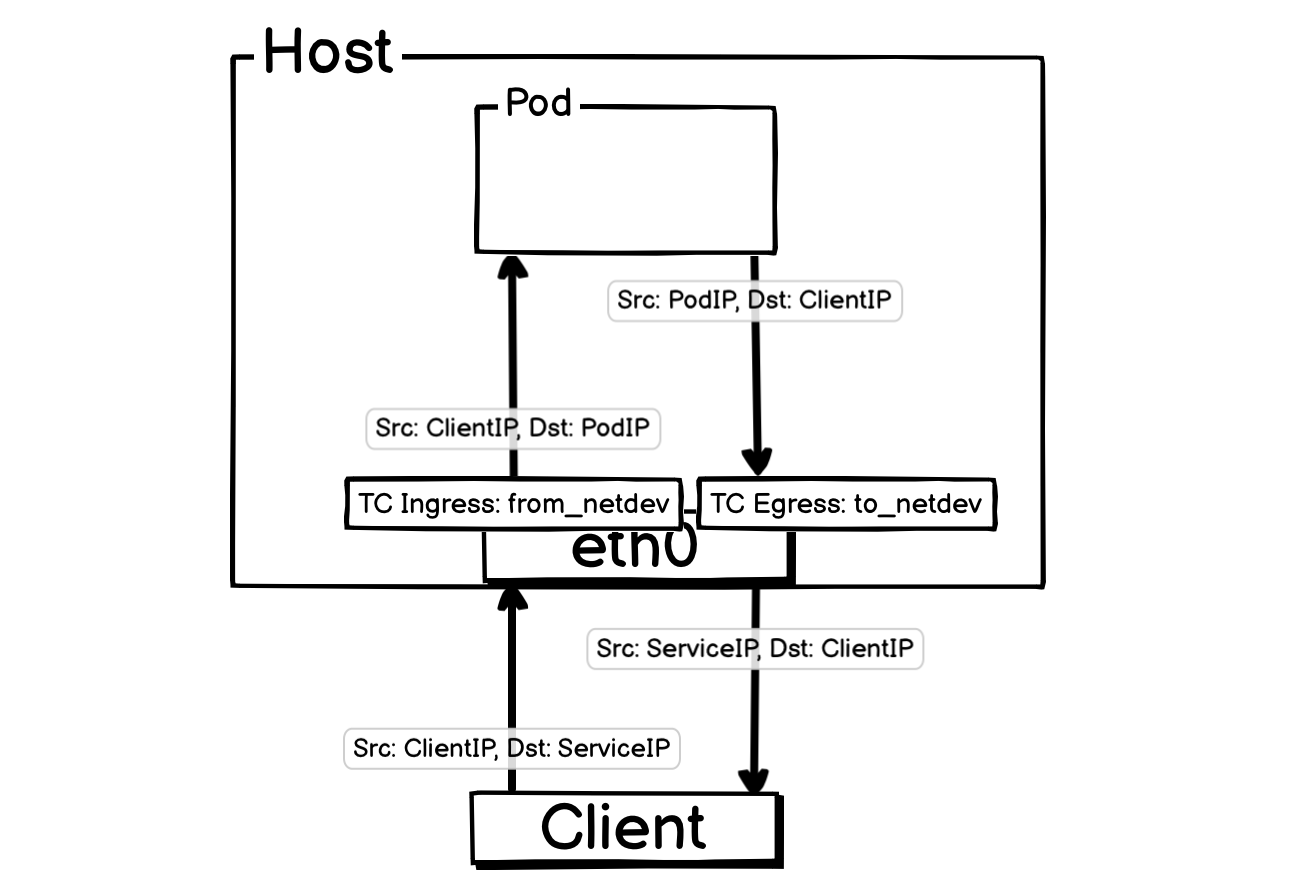
目标 Pod 在当前宿主机:
目标 Pod 在其他宿主机:
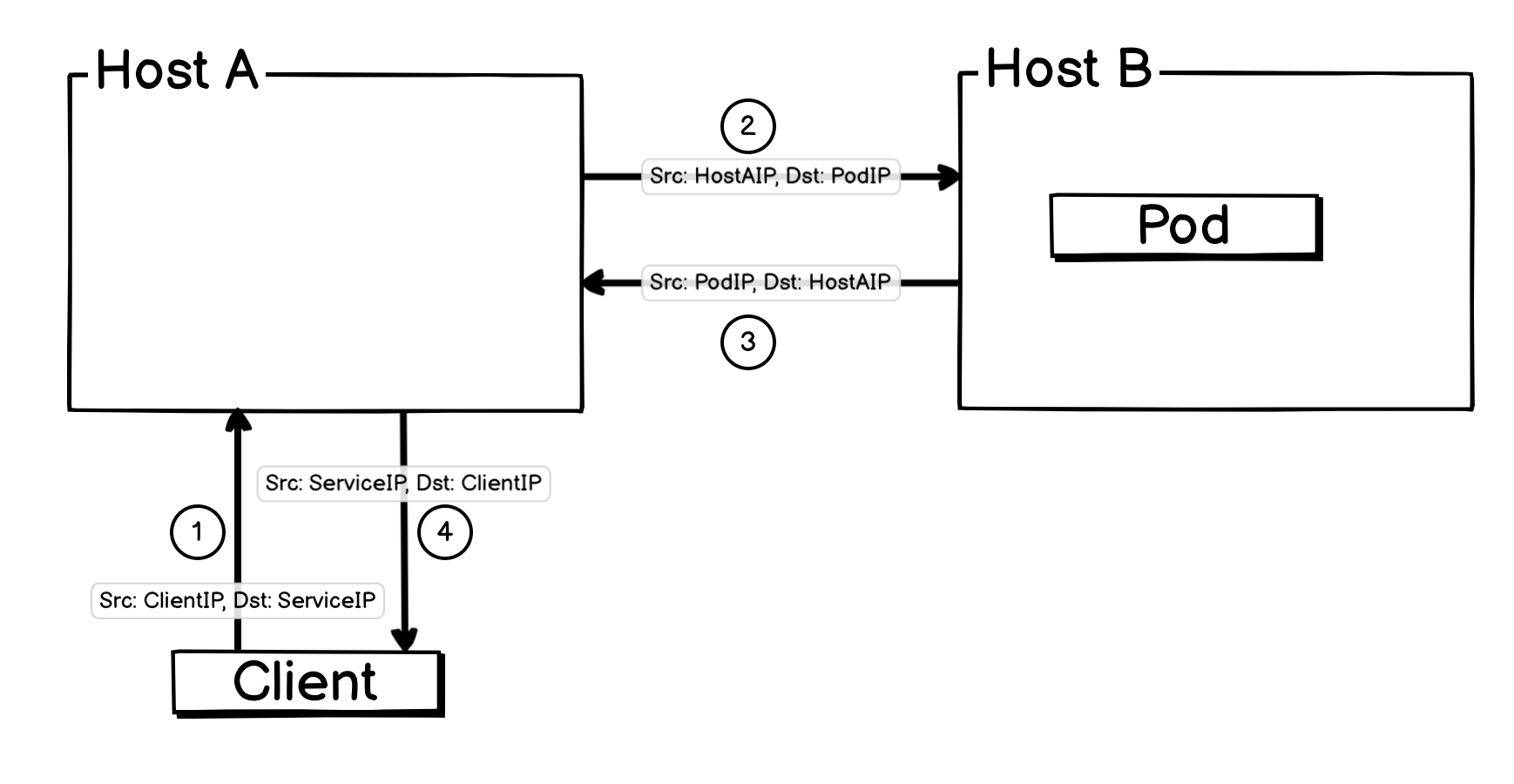
上面两张图没有填写端口信息,是因为端口信息是隐含信息,ServiceIP 隐含 ServicePort,PodIP 隐含 PodPort。
数据流转情况描述:
-
数据包到达: 客户端发送一个数据包,源地址
ClientIP,目标地址SvcIP。这个数据包通过外部网络到达 Node 1 的物理网卡(例如eth0)。 -
TC Ingress Hook (
from_netdev): 数据包一进入eth0,就会触发挂载在 TC Ingress Hook 上的 eBPF 程序from_netdev。 -
NAT(
from_netdev):eBPF 程序发现目标地址为 Service,它会根据负载均衡算法从 Cilium 维护的数据,也是 CRD ciliumendpoints 中,取出一个 PodIP,然后对其报文执行 NAT:- 如果 Pod 就位于当前宿主机,那么只会把目标 IP 修改为 Pod IP ,源 IP 不变。
- 如果 Pod 位于其他宿主机,那么会将源 IP 更换成当前机器 IP,目标IP修改为 PodIP ,并记录 NAT 信息。
-
流量转发:
bpf_netdev查询系统路由表,然后根据路由表情况转发报文。报文到达目标 Pod 后,又会经过同样的路径回到 eth0 网卡。 -
反向 NAT:
-
本机 Pod 返回的报文,会被
to_netdev处理,并由其执行反向 NAT,把源 IP 更换成 Service IP ,然后由 eth0 发出。 -
其他宿主机 Pod 返回的报文,会被
from_netdev截获,并由其执行反向 NAT ,把源 IP 更换成 Service IP ,目标 IP 更换成客户端 IP ,然后直接 redirect 到 eth0 发出。
-
-
客户端收到报文。
就是用 from_netdev eBPF 程序实现了传统的 NodePort 模式。
DSR 模式
1. 什么是 LVS-DR 模式。
LVS 是一种非常流行的高性能 L4LB 方案,DSR 的实现原理和他比较类似。
首先,在同一个二层网络中,所有相关节点(包括负载均衡器和后端服务器)均需配置两个 IP 地址:一个是节点自身的数据 IP,用于正常通信;另一个是统一对外服务的虚拟 IP (VIP)。对于后端业务服务器,此 VIP 必须配置在环回接口(Loopback)上。
接着,为避免 ARP 冲突,后端业务服务器必须配置严格的 ARP 响应策略,确保其物理网卡只响应针对自身数据 IP 的 ARP 请求,而抑制对 VIP 的 ARP 响应。
与此同时,负载均衡器(Director/LB)需将 VIP 配置在物理网卡上,并通过 IPVS 规则设定流量转发策略,将所有发往 VIP 的请求分发至后端的业务服务器。
当外部请求到达网关时,其目标地址为 VIP。此时,网络中只有负载均衡器会响应针对该 VIP 的 ARP 请求,从而成功接收到数据包。
数据包到达负载均衡器后,IPVS 模块会匹配相应规则,在不改变 IP 头(源 IP 为客户端 IP,目标 IP 仍为 VIP)的前提下,将数据包的目标 MAC 地址改写为所选后端服务器的 MAC 地址,并在二层网络上直接转发。
后端服务器收到此数据包后,因其环回接口上配置了该 VIP,故可合法处理该请求。请求处理完毕后,服务器会以 VIP 作为源 IP,将响应数据包直接返回给客户端,不再经过负载均衡器。
至此,便完成了一次完整的 LVS-DR 模式请求处理流程。
2. DSR 的实现原理
注: DSR 不适用于
hostNetworkPod。
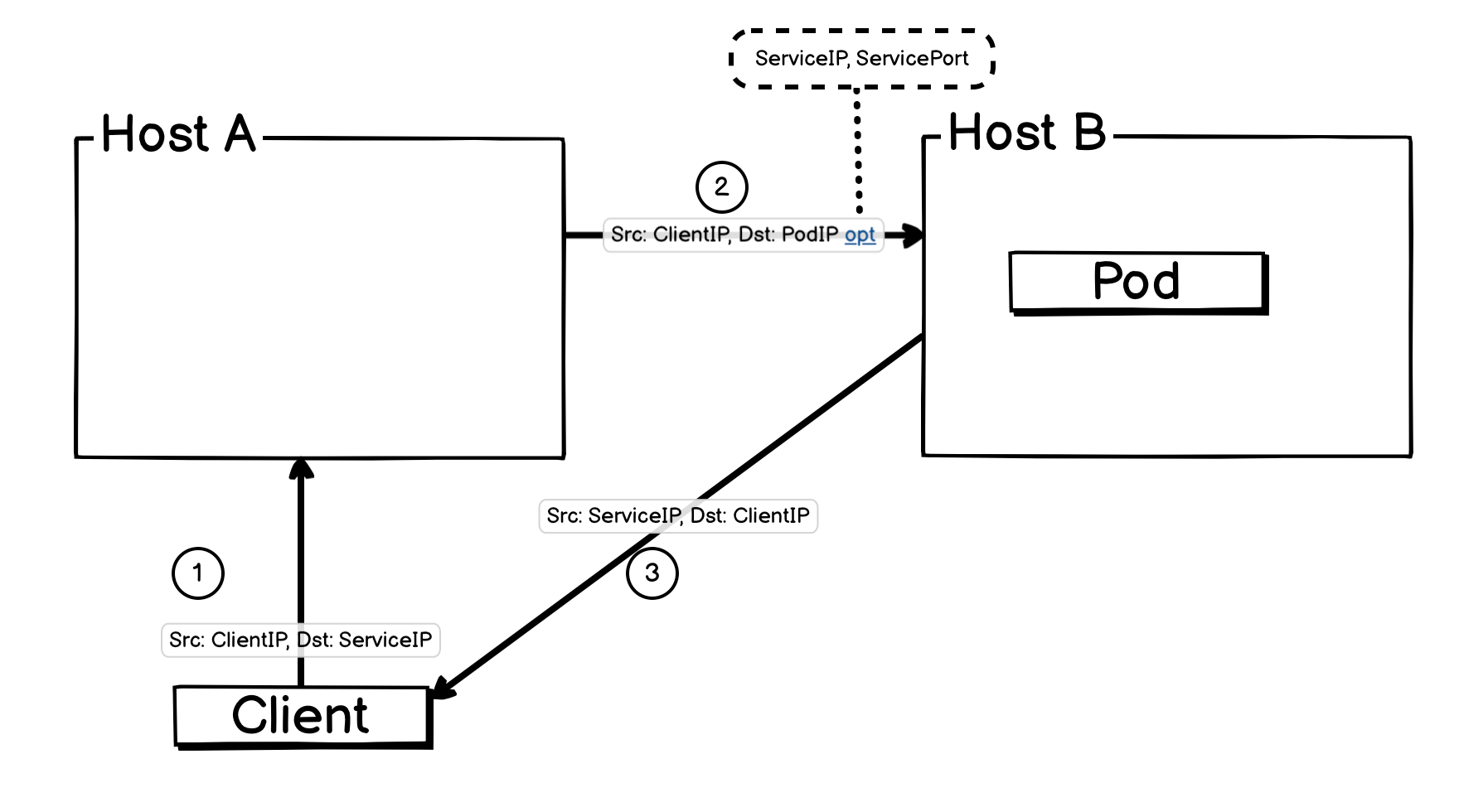
- 数据包到达: 客户端发送一个数据包,源地址
ClientIP,目标地址ServiceIP。这个数据包通过外部网络到达 Host A 的物理网卡(例如eth0)。 - TC Ingress Hook (
from_netdev): 数据包一进入eth0,就会触发挂载在 TC Ingress Hook 上的 eBPF 程序from_netdev。 - 修改报文(
from_netdev):eBPF 程序发现目标地址为 Service,它会根据负载均衡算法从 Cilium 维护的数据,也是 CRD ciliumendpoints 中,取出一个 PodIP,然后对其报文处理后转发:- 报文源 IP 修改成 客户端 IP ,目标 IP 修改为 Pod IP ,并在报文中增加 Service IP,Service Port 元信息(TCP 第一个 SYN 报文会加扩展信息,UDP 所有报文都会加扩展信息)。
- 流量转发:
bpf_netdev查询系统路由表,然后根据路由表情况转发报文。 - Pod 收到报文,会返回一个
Src: PodIP, Dst:ClientIP的报文,此报文会被 Pod vets 上面的from_containereBPF 程序处理,最后会变成Src: ServiceIP, Dst:ClientIP,然后再发出去。 - 客户端收到报文。
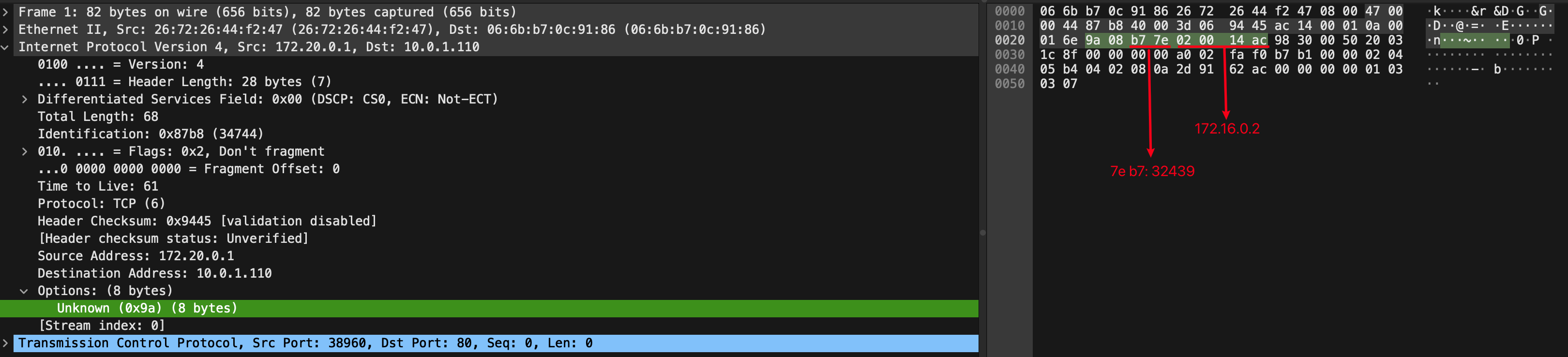
Cilium 中可以找到 dsr 扩展信息。
# https://github.com/cilium/cilium/blob/main/bpf/lib/nodeport.h#L76
struct dsr_opt_v4 {
__u8 type;
__u8 len;
__u16 port;
__u32 addr;
};
抓包也可以看到。
3. DSR 有什么优点?
除了报文直接返回优化路径之外,其实一般 request 是小报文,response 一般数据量较多,在这种逻辑下,整个请求场景,LB 节点受到的压力会小很多。
业务服务收到的请求 IP 是客户端的源 IP 。
4. DSR 有什么问题?
-
由于会出现节点发出报文,但是源 IP 信息并不是节点本身,在云厂商网络,一般都需要特殊配置之后,才能支持 DSR,甚至直接不支持 DSR 模式。
-
默认模式下,DSR 是通过报文新增额外信息来传递特有信息的,这个时候,某些公有云提供商环境可能无法正常工作,且某些网络设备在一些拥塞情况下,会丢弃这些报文。一些严格模式的防火墙或者老旧的网络设备也可能丢弃掉此报文。
默认情况下,DSR 会在 TCP 建立的第一个报文,SYN 报文中增加额外信息,来向目标端通告这个 TCP 连接的 Service 信息,以便服务响应端在返回数据的时候,使用 Service 信息作为源 IP 信息返回, 而且UDP 没有连接概念,每个报文都需要添加额外信息,这是需要降低 MTU 实现的。
如何解决?
在配置 DSR 的时候,会有一个参数
--set loadBalancer.dsrDispatch=opt,默认是 opt,即报文额外扩展,可以修改为--set loadBalancer.dsrDispatch=geneve,即,替换掉由报文扩展信息中携带扩展信息,转而将原始的 IP 包封装在一个基于 UDP 的 Geneve 隧道包中。这种方式由于使用了标准的 UDP 协议进行传输,因此在公有云和各种网络环境中的兼容性很好,但是因为报文需要封装,所以性能会弱于 opt 模式。
结束语
Cilium 利用 eBPF 实现 kube-proxy 的功能,其意义远不止于通过 Socket-LB 与 DSR 技术实现的性能优化。它更核心的价值在于证明了一点:借助 eBPF 远超传统内核的迭代效率,像 Cilium 里面各种全新的数据路径和网络方案可以被迅速创造出来并投入应用。
Cilium 的成功,并不仅仅是一个网络插件(CNI)的胜利,它更像是一个宣言:它宣告了一个时代的到来,一个 eBPF 的时代。