DRBD是一个内核级别的数据同步方式,其作用可以让不具备高可用能力的应用具备高可用能力。DRBD类似磁盘阵列的RAID1,相信看到高可用的朋友都懂RAID,所以在这里就不扯RAID。只不过RAID1是在同一台电脑内,而DRBD是透过网络。
一、理论泛讲
下面这张图是DRBD官方的图
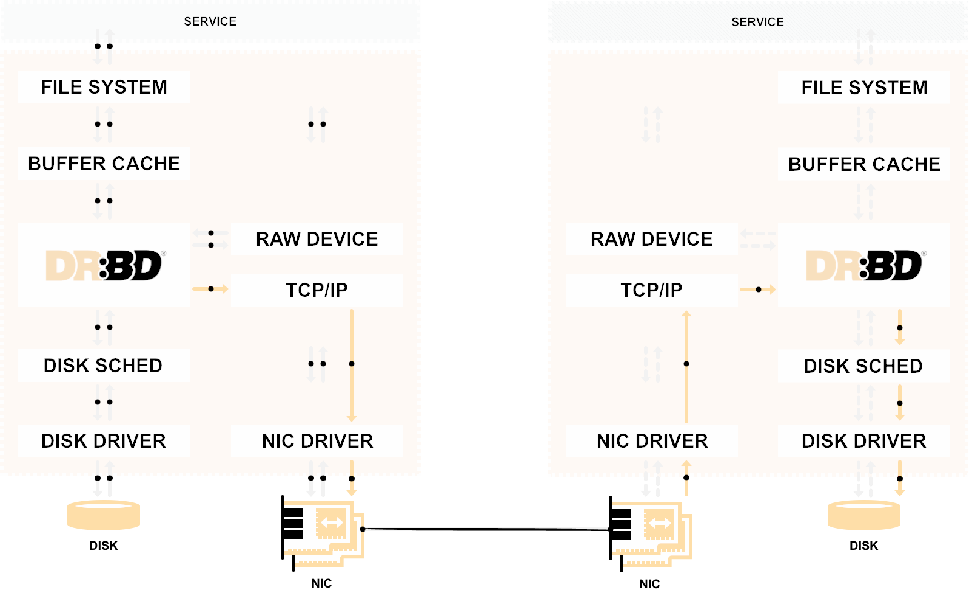
在没有DRDB之前,File System的写操作都会先存储在Buffer cache中,然后由Disk Sched统一写入,而当加入DRDB之后,在Disk Sched会将数据发给TCP/IP协议栈,通过调用网卡驱动从网卡发送给另一个节点。
相信大家一定有sync和async的概念,说白了就是同步异步。在DRBD中,也有三种协议:
- 协议A:异步:数据发送到自己TCP/IP位置就返回
- 协议B: 半同步:数据发送到从节点TCP/IP处返回
- 协议C: 同步:数据被从节点存储下来,才返回
一般来说,A最块,C最安全。。
和ipvs和ipvsadm一样。DRBD也有内核模块和用户空间管理工具。和ipvs不一样的是,DRBD的内核模块在kernel 2.6.33之前是没有加入内核中的。也就是说如果你想用它你就的编译,不过还好已经有人把自己编译过的发送到网络上面,只要对应就能用,它的对应也是一件很麻烦的事情,他会对应到2.6.32-573.el6.x86_64中的2.6.32-573,也就是说,如果找不对对应kernel版本的rpm包,那就的自己编译安装,我用的环境是Centos 6.7。内核版本也就是上面贴出来这个,我会把安装包丢在文章的最底部。。安装过程也简单,就是rpm就安装了
配置文件讲解:
- 主配置文件:/etc/drbd.conf
只是用来调用/etc/drbd.d/目录下面的配置文件的
- 全体配置文件:
/etc/drbd.d/global_common.conf
这里面定义的是通用配置
commit{
handlers (处理器,在特定情况下执行的脚本或者程序) {
pri-on-incon-degr : 主节点降级了怎么办
pri-lost-after-sb : 脑裂之后主节点找不到了怎么办?
local-io-error : 本地IO error怎么办?
.... 其他的会跟高可用集群冲突
}
startup(drbd设备启动时怎么办){
wfc-timeout 等待对方上线连接的超时时间
degr-wfs-timeout : 降级的等待连接超时时间
outdated-wfs-timeout: 过期的等待连接超时时间
wait-agter-sb: 脑裂之后等待多久让对方上线
}
options{}
disk{
on-io-error 双方有一个io error怎么办
pass_on: 把错误的节点降级为非一致状态
call-local-io-error 呼叫local-on-error,执行脚本
detach: 把磁盘拆掉
resync-rate : 重新同步的时候的传输速率,不定义默认会占用最大带宽
}
net{
protocal 协议ABC
max-buffers : 缓冲最大大小
sndbuf-size : 发送缓存大小
rcvbuf-size: 接收缓存大小
默认2个都为0,由系统自己决定,如果给一个值,那么这个值不能小于32
allow-two-primaries : 双主模型
cram-hmac-alg : 握手认证协议
crc,md5,sha1
share-secret: 共享密码
}
syncer(数据速率){
rate
}
}
我的配置
global {
usage-count no;
}
common {
handlers {
pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f";
}
startup {
}
options {
}
disk {
on-io-error call-local-io-error;
resync-rate 1000M;
}
net {
protocol "C";
cram-hmac-alg "sha1";
shared-secret "itcys.top";
}
}
- 资源配置文件
/etc/drbd.conf/*.res
这个是需要自己手动建立的。
[root@node1 drbd.d]#cat test.res
resource test{ //定义资源名字
on node1.itcys.top{
device /dev/drbd0; //虚拟盘
disk /dev/sdb1; //实际盘
meta-disk internal; //DRBD的源数据就存放在当前磁盘
address 192.168.100.51:7789; //监听的套接字
}
on node2.itcys.top{
device /dev/drbd0;
disk /dev/sdb1;
meta-disk internal;
address 192.168.100.52:7789;
}
}
具体实施
一、前期准备工作
- 1、NTP
- 2、hostname
- 3、避免其他不必要的因数,iptables和selinux请关闭
- 4、一边一块10G的盘(分区也行)。
- 5、安装drbd和用户空间工具
前面3个在我之前blog说过多回,分区或者盘的创建我相信能看这个的应该没没人不会把。安装那个没什么说的。关键是难找,找到了就rpm -ivh就安装了。
二、熟悉DRBD
1、node1和node2都开启DRBD服务。
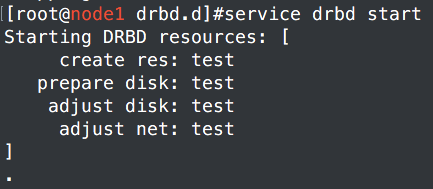
2、查看状态的两种方法


Secondary表示从节点,而Secondary/Secondary和后面那个Inconsistent/Inconsistent都是表示前面一个是当前节点状态,后面一个是其他接节点状态,Inconsistent表示现在还是不一致状态
3、初始化。primary表示主节点
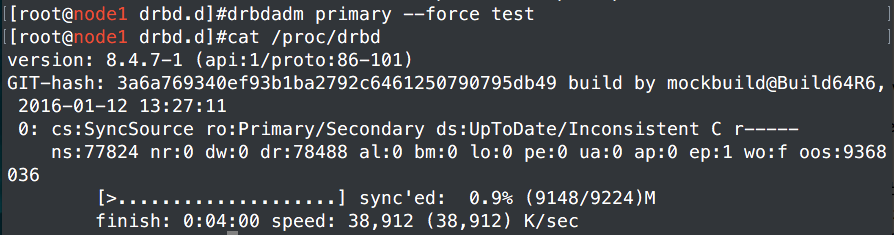
初始化完成之后可以发现同步已经在进行了,完成之后就可以进行下面的操作了
4、测试
a、在主节点格式化并挂载
[root@node1 drbd.d]# mkfs.ext4 /dev/drbd0
[root@node1 drbd.d]# mount /dev/drbd0 /drbd/
b、在里面新建一些内容

c、主从转移,让node2成为主,从而使其能挂载使用/etc/drbd0,挂载之后查看是否同步完成
node1:
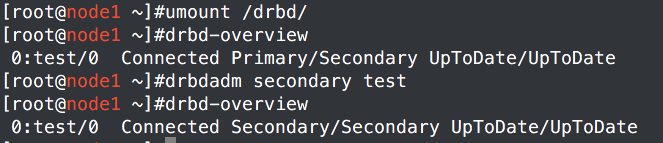
node2:
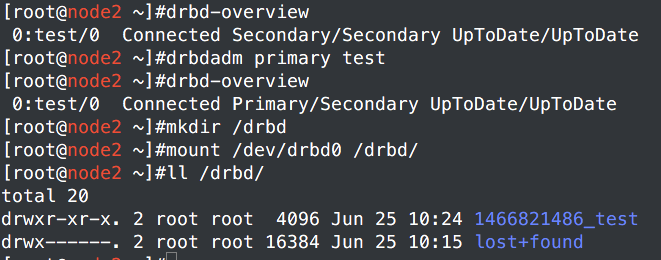
三、使用corosync+pacemker管理drbd+MySQL
我们这里使用MySQL做测试,因为是测试,所以我就直接yum安装了。
配置文件/etc/my.cnf里面加上:datadir=/drbd
我是第一次yum安装的MySQL,怎么看怎么不对劲。不过只要两个节点配置文件一样就行了。生产环境只需要编译安装,配置文件复杂点,实现理念都是一样的。
[root@node2 ~]# scp /etc/my.cnf node1:/etc/
启动mysqld让其初始化,并在里面建立远程登录账户,到时候好用来测试
[root@node2 ~]# service mysqld start
[root@node2 ~]# mysql

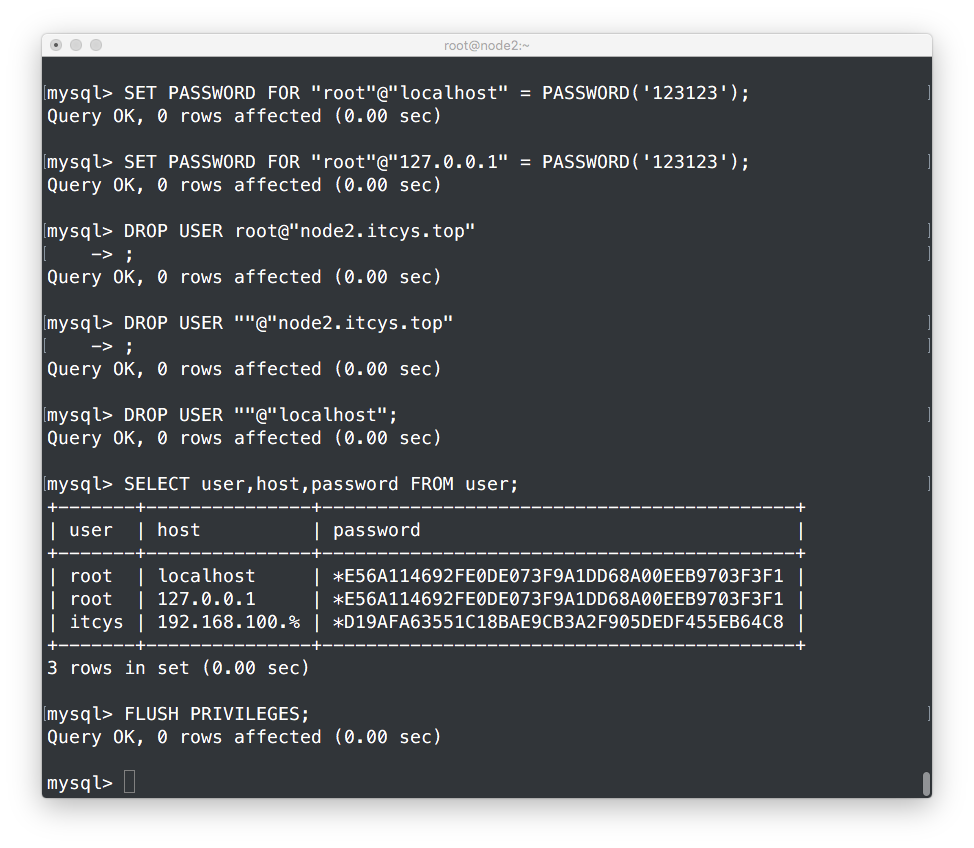
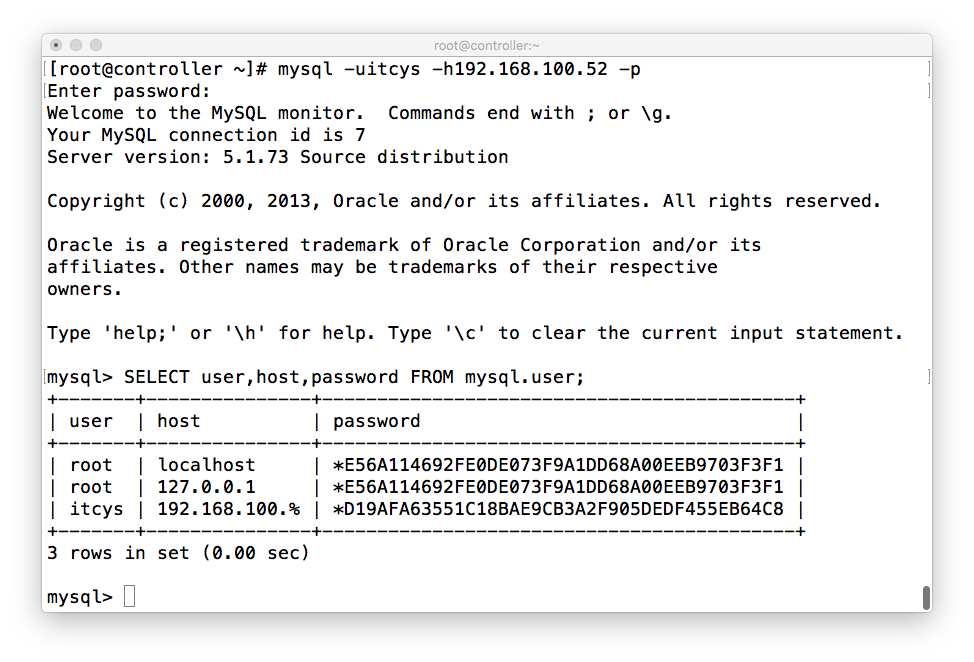
在其他节点进行测试:
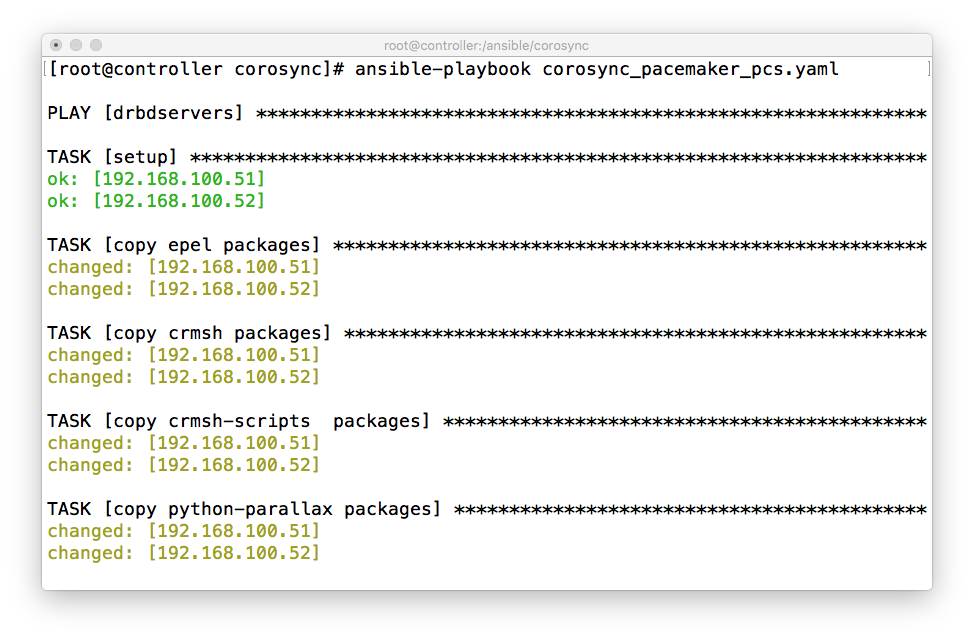
1、安装corosync+pacemker,我直接用ansible安装了,我其他blog有详细介绍
2、主从节点都停止mysql和drbd,并禁止开机启动

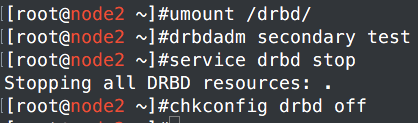
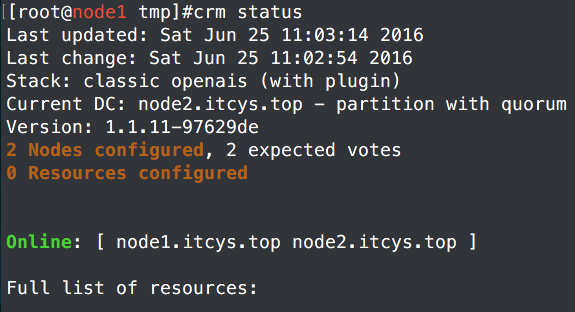
3、查看状态
4、创建资源进行管理:
a、创建drbd资源
因为drbd从节点不能读取写入,也不能挂载,正好符合主从资源架构,所以还的创建创建主从资源

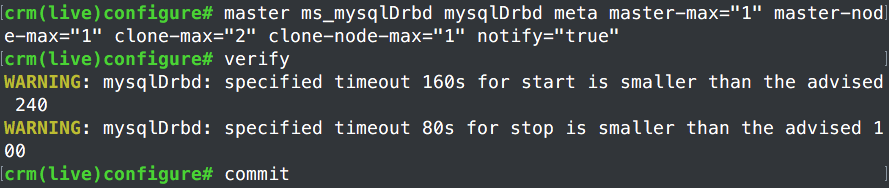
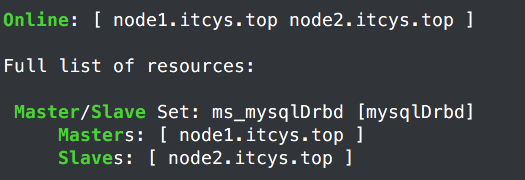
可以看出pacemaker以及自己决定了Master、Slave关系。
b、创建虚拟IP、FileSystme、mysqld资源


e、创建约束



5、查看状态
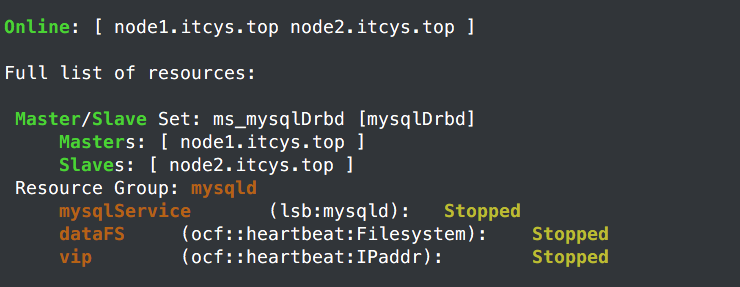
组好像有问题。把组删了。再查看。
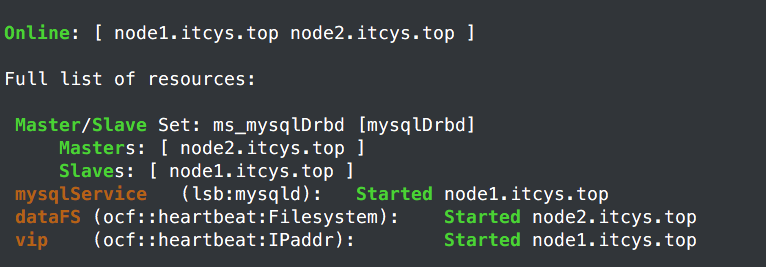
好像正常了。再把约束设置一下,把排列约束中定义的组换成资源就行了,

确实所有节点都在Master上。看下世纪启动没有

正式启动了。
6、测试
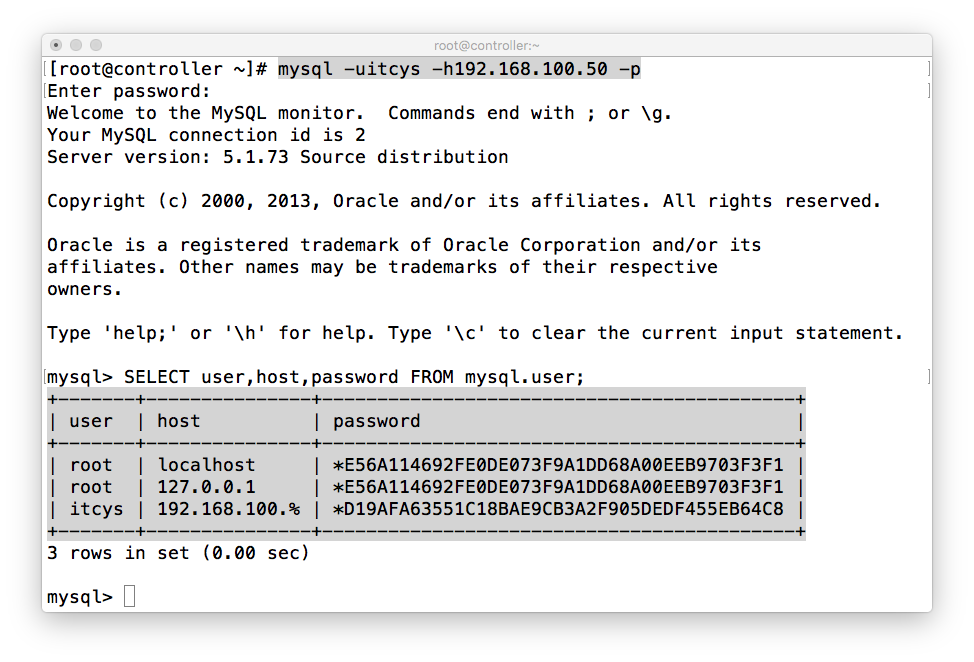
a、远程主机登陆测试,登陆上去还是原来的样子
b、关闭mysqld服务,看需要多久才自动重启
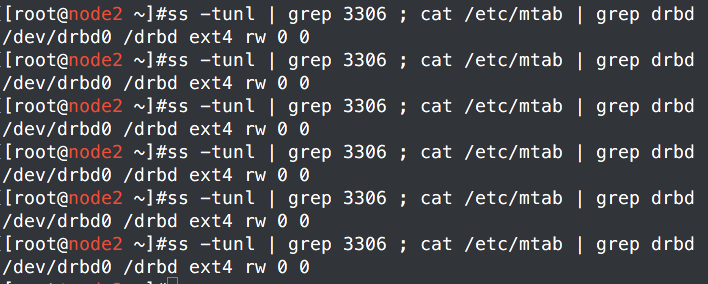
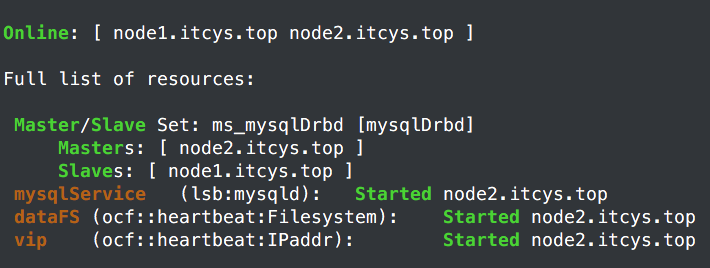
没反应,那就是没定义监控咯。查看一下配置情况。果真没有配置监控
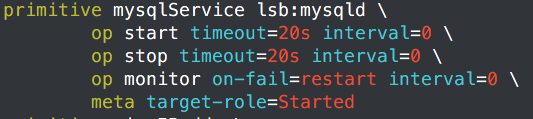
配置监控

效果

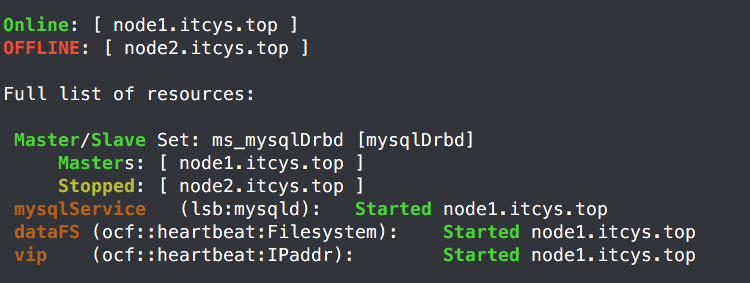
c、模拟主节点宕机
在主节点上面关闭网络

在从节点上面进行查看,资源已经转移
第三方测试看能否成功:
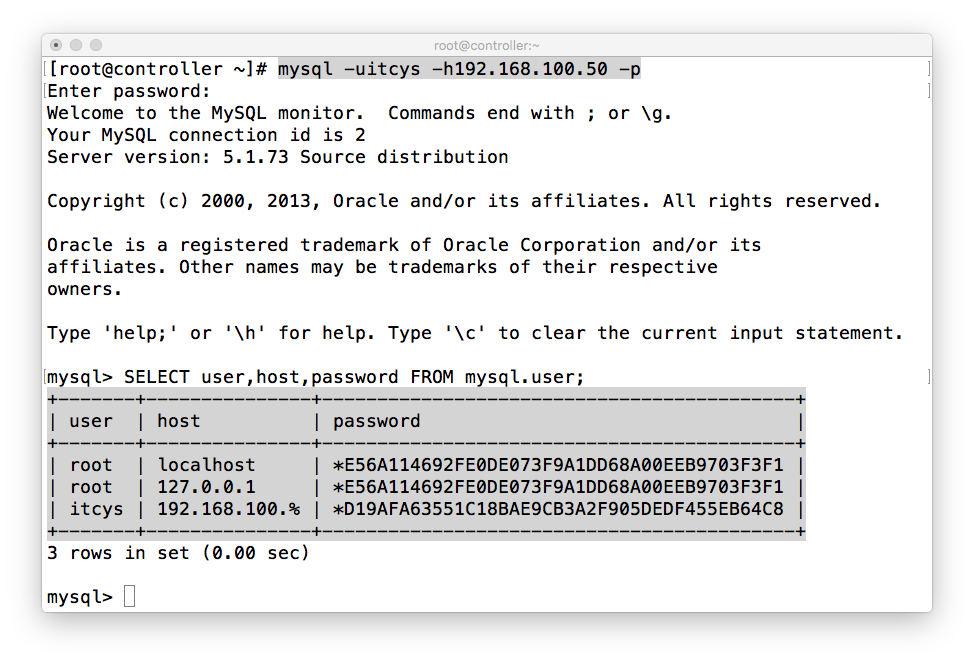
第三方测试成功。
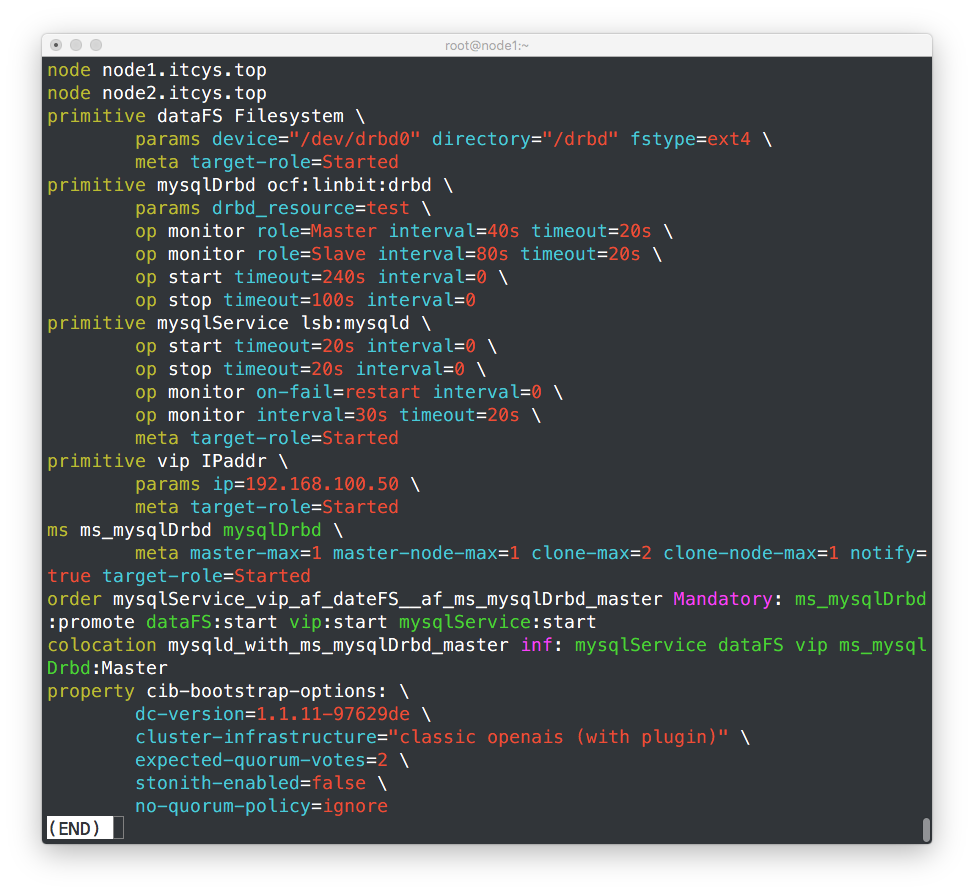
这个就是全部的配置。还可以加。比如vip设置监控,还有资源粘性等等。这里只是给个演示,就不深入了
DRBD_CentOS-6.7-x86_64_Kernel-2.6.3.573软件包:https://github.com/chenyanshan/Software/tree/master/drbd_2.6.32-573