现在这个服务为重的时代,服务的重要性越来越高,但是在服务器这一块,服务器总会有宕机的时候。服务器一旦宕机,服务器就会停掉,那怎么样才能让服务在服务器宕机的时候,服务还在呢?那就是高可用技术来实现了。高可用,顾名思义:高度可用,也就是所谓的冗余,说白点就是一个国家有一个总理一个副总理,总理挂了副总理顶上。从而实现国家的运转不停止,在Linux高可用集群中也差不多是这样,为了保证服务的高可用,必须保证集群中不能出现可能发生单点故障的点。当然,很多小企业因为资金问题,不可能去搭建高可用集群。
一般高可用集群都专注这两个点: failover:故障转移 当一节点出现故障,其上的资源能自动转移到正常的节点继续提供服务 failback:故障转回 当主节点故障修复上线后,之前顶替主服务器工作的备份服务自动将资源转回,当然这个不是必须的。
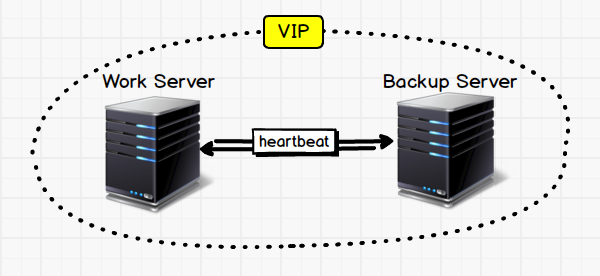
像上面这张图,就极其明白了阐述了高可用的特点,内部一主一备,向外只提供一个IP,它们之间通过Heartbeat联系
Heartbeat: 要说高可用架构,就不得不说Heartbeat(心跳检测),这个既是一款软件,又是一种通信方式。我们现在讲通信方式,HeartBeat就是高可用集群内的服务器不停的将自己的心跳信息进行通告,其他服务器收到其发出的心跳消息,就认为其在线。而且heartbeat程序一般都会提供API供httpd,ipvs等服务调用。
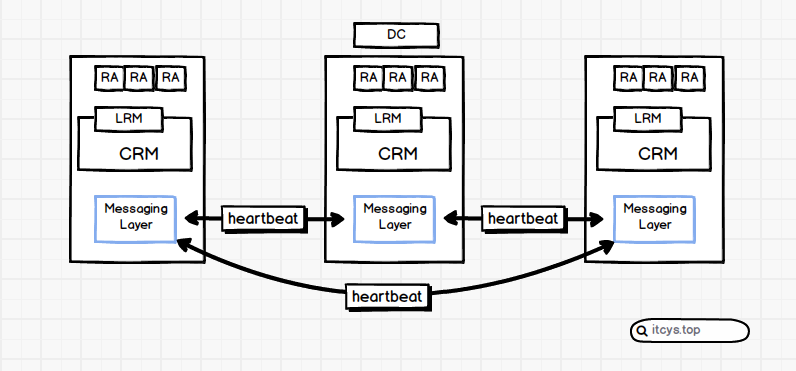
Messaging Layer(信息层):
说白了就是Heartbeat层,通过提供给服务的API检测服务状态,发送Heartbeat消息,接收其他服务器的Heartbeat消息,并提供API给上层集群管理器进行调度
CRM:Cluster Resources Manages(集群资源管理器):
集群中实际的决策者。CRM调用Messaging Layer的API接收Heartbeat消息,顺带通过Messaging Layer向外发送消息。对内部主机的操作都是通过LRM来实现的
LRM:Local Resources Manages(本地资源管理器):
CRM的消息都发送给LRM,LRM接收到消息之后通过RA进行调度。并且会通过RA获取服务状态,发往CRM,由CRM调度Messaging Layer向外发送心跳包。
RA:Resource agent(资源代理):
说白了就是脚本。LRM调度集群服务对应的脚本,通过stop,start对服务进行调度,通过status对服务状态进行检测。一般说来,RA里面至少能进行start,stop,status。而且status必须running就是running,是Stopped就不能是Not Running。不然LRM可能检测不到。不同的RA对参数的需求也不同,RA类型有4种,后面再讲述。
DC:Designated Coordinator(指定的协调员):
整个集群的大脑,由DC来协调集群中各节点资源的运行,比如在某个节点故障之后,其上的资源应该转移到哪个节点,应该是集体转移还是分别转移到不同的节点。如果DC挂了,剩余的服务器会自己推选出DC。
如果上面的是一个正在运行的集群,A一旦出问题,DC就会接收到,然后由Messaging Layer向B传递启动资源的消息,B的CRM通过Messaging接收到启动资源的请求。就会调用CRM启用资源,CRM就会使用RA讲资源启动起来。从而实现高可用集群中“当一个节点出现故障的时候其上的资源可以自动转移到正常节点启动起来”。这种转移就叫做failover,翻译成中文就是故障转移。当A起来之后,根据之前的设定,B的资源要是再转回A。就叫做failback,也就是故障转回
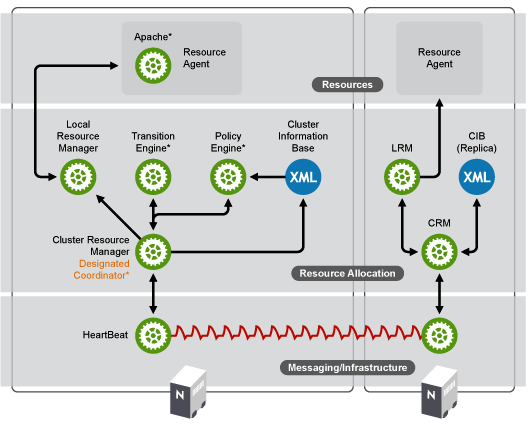
我们再来看Suse文档中的架构图。这种只是为了区分DC和普通集群成员的区别。这个架构分三层,最底下的massaging(信息传递层)是由HeartBeat(心跳)实现的,最上面的Resources(资源层)是由RA实现的。
具体讲述Roseocure Allocation(资源管理层)
CIB:Cluster Information Base(集群信息库):
集群的所有的配置都会以XML的形式保存在CIB。其中包括资源约束,资源粘性等配置情况,不管在哪个节点上面修改配置,配置都会先到达DC,再由DC进行全集群通告同步配置信息
PE:Policy Engine(策略引擎):
它会通过massaging收集集群所有节点的信息,并且和CIB中的资源配置信息结合。从而决定某个挂掉的Server上面的服务应该怎么转移。往哪台Server转移,转移的资源启动顺序谁先谁后,如果挂掉的Server修复上线之后,又应该怎么办?这些统统由PE来决定。
TE:Transition Engine(事务引擎)
负责具体实现PE发出的决策,和PE的关系就差不多是CRM和LRM的关系一样。不过大家可不要把PE和CRM搞混了,觉得怎么会有2个决策者。其实想想就明白了,只有DC上面有PE和TE嘛。
还拿上面那个ABC的例子来说,大家想象着将右边这个节点拷贝一份。就成ABC了。 当A节点出现故障。CRM会通过Messaging接收到A出问题的消息,并将其传递给PE,PE接收到A宕机的消息,会查看CIB中的配置情况,根据配置进行决策,然后告诉TE,由TE通过Messaging层向B的CRM发送启动资源的消息….
各层的实现方案:
Messaging Layer:
hearteat v1, v2, v3
OepnAIS,corosync
cman
Roseocure Allocation
haresources
CRM
pacemaker
rgmanager
Roseocures(RA):由于是脚本实现,所以下面都是说脚本的类型
heartbeat Leagacy heartbeat传统风格
LSB 我们用service调用的那种脚本
OCF Open Cluster Framework
STONITH 资源隔离类型
好了,站在架构角度给大家讲了这么多。到这里大家应该对HA(高可用)有一个整体性的认知了,我们再来讲下它们之间的运行方式和一些实现的过程需要解决的问题。
问题1:
上面的DC的介绍中介绍了一旦DC挂了,那么其他成员就会自动推举DC。如果集群出现网络问题,集群分裂成两部分,那么那些没有和DC分配在一起的岂不是要再推举出DC,然后启动资源提供服务?
这个时候就的引出votes-票数,total-总票数,quarum-过半票数,一般来说,当集群发生分裂,那么持有票数低于总票数一半的集群将会自己放弃成为集群成员,而票数达到quarum的集群将会继续提供服务。votes-票数可以根据性能来设定
问题2:
如果在共享存储中,一方正在写入数据,而网络出现问题,另一方也启动服务,挂载共享存储,然后写入数据,那么当一个数据同时被两个进程写入,轻则数据损坏,重则整个文件系统崩溃,怎么避免?
这个时候就的引出资源隔离的概念来,这个词是不是在哪看到过?没错,就在上面的RA类型还说了。STONITH就是专门用来隔离资源的。比如它就可以用大家最常用的ssh实行一个节点在启动资源之前会向前面那个出问题的节点发送shutdown命令。当然STONITH有很多种资源隔离方法。
问题3:
一个服务中的资源谁先启动谁后启动,怎么决定?比如NFS在HTTPD服务器上面就可以运行在HTTPD服务的前面,也可以运行在HTTPD的后面。但是NFS如果和MySQL结合。那么必须要NFS运行在前面。
还有,怎么让一个资源倾向于运行在当前节点?
怎么让2个资源结合在一起运行?比如VIP+HTTPD+NFS。如果开始规划时将它们组合在一起,那么之后这仨就必须在同一节点上面运行,少一不可
这个在rgmanager中是由failover domain priority来定义的。
在pacemake中
资源约束
- 位置约束:资源更倾向于运行在哪个节点上
- 排列约束:不同资源运行在同一节点上面的倾向性
- 顺序约束:资源的启动次序以及关闭次序
资源粘性:当位置约束相同的时候,资源转不转移。
概念性的东西就讲的差不多了,当然我这里只是初略的过一遍,想要用好高可用,还得继续学。下一篇依旧是实现,图形界面的。相信大家有了这个理论知识再看实现,应该不难。