AI 大时代已然到来,本文将分享一个 AIOps 的落地实现,即实现 ChatAIOps 与 Prometheus 告警内容的 AI 初步研判。这基本上是一次抛砖引玉的探索,鉴于细节繁多,文中将省略一些简单的配置过程,重点阐述核心思路和最终效果。感叹一句,AI 的进化实在太快,拥抱 AI,即拥抱未来!
一、目标
- 能够通过 Chat 进行 Kubernetes OPS 操作。
- Prometheus 的告警,LLM 能够通过 MCP 获取到对应资源的具体状态,然后进行一个判断和总结,最后再将告警信息通知给告警端。
- 使用 LLM 每日对 Kubernetes 集群巡检。
- 让 LLM 主动巡检(主动巡检多轮 MCP 后,上下文太大,可能要更换超大上下文模型,或者每资源,每 namespace 单独发起,也可以自己实现一个支持巡检功能的 MCP Server 给 LLM 用)。
- 脚本巡检汇总内容给到 LLM 进行总结。
二、基础组件
1. N8n
n8n 是一款采用公平代码 (fair-code) 许可的开源工作流自动化工具。它允许用户通过基于节点的可视化界面连接不同的应用程序和服务,创建复杂的自动化流程,而无需编写大量代码 。n8n 的可扩展性使其能够通过社区节点或自定义节点集成几乎任何具有 API 的服务。其自托管能力也为在私有环境中部署和运行自动化任务提供了灵活性。
2. manusa/kubernetes-mcp-server
manusa/kubernetes-mcp-server 是一个基于 Java 实现的 MCP 服务器,专门用于暴露 Kubernetes API 功能 。根据其项目描述,主要特性包括:
- 广泛的兼容性:支持与 Kubernetes 和 OpenShift 集群交互。
- 通用资源操作:能够对任意 Kubernetes 或 OpenShift 资源执行 CRUD (Create, Read, Update, Delete) 操作。
- 细化的 Pod 控制:提供针对 Pod 的特定操作,如列出、获取、删除、查看日志、执行命令 (exec) 以及运行新容器镜像。
- 集群信息查询:支持列出 Kubernetes 命名空间、查看集群事件以及列出 OpenShift 项目。
- 配置管理:能够查看当前的 Kubernetes 配置(无论是来自
.kube/config文件还是集群内配置),并能自动检测配置变更。 - 零外部依赖:不依赖
kubectl或helm等命令行工具,简化了部署。 - SSE 支持:可以通过命令行参数 –sse-port 启动 SSE (Server-Sent Events) 模式,允许客户端通过 SSE 接收来自服务器的事件和数据流
- 容器化部署:项目仓库中包含
Dockerfile文件,便于构建和部署容器镜像 。
二、Kubernetes 部署配置
1. 部署 n8n deployment 新版本。
使用 n8n MCP Server Client 功能,调用其他支持 SSE 的 MCP Server
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: n8n-data
namespace: aiops
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi # 根据需要调整存储大小
storageClassName: cbs
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: n8n-deployment
namespace: aiops
labels:
app: n8n
spec:
replicas: 1 # 根据需要调整副本数量以进行扩展
selector:
matchLabels:
app: n8n
template:
metadata:
labels:
app: n8n
spec:
securityContext:
fsGroup: 1000
containers:
- name: n8n
image: container-registry.tencentcloudcr.com/tools/n8n:1.91.3
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 5678
volumeMounts:
- name: n8n-storage
mountPath: /home/node/.n8n # n8n 的数据目录
resources: # 根据您的需求和集群容量调整请求和限制
requests:
memory: "2Mi"
cpu: "1m"
limits:
memory: "6Gi"
cpu: "3" # CPU核心数
livenessProbe:
httpGet:
path: /healthz # n8n 健康检查端点
port: 5678
initialDelaySeconds: 60 # 启动后多久开始探测
periodSeconds: 15 # 探测频率
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /healthz
port: 5678
initialDelaySeconds: 30
periodSeconds: 15
timeoutSeconds: 5
failureThreshold: 3
volumes:
- name: n8n-storage
persistentVolumeClaim:
claimName: n8n-data
---
apiVersion: v1
kind: Service
metadata:
name: n8n-service
namespace: aiops
spec:
type: ClusterIP # 外部访问请考虑使用 LoadBalancer, NodePort 或 Ingress
selector:
app: n8n # 确保这与 Deployment template labels 匹配
ports:
- name: http
protocol: TCP
port: 80 # Service 监听的端口
targetPort: 5678 # n8n 容器监听的端口 (N8N_PORT)
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: n8n
namespace: aiops
labels:
name: n8n
spec:
ingressClassName: nginx
rules:
- host: kubernetes-n8n.orvibo.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: n8n-service
port:
number: 80
2. 配置 kubernetes-mcp-server 所需的 rbac 权限和 service account 账户。
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kubernetes-mcp-server-role
namespace: aiops
rules:
- apiGroups: [""] # Core API group
resources:
- pods
- pods/log
- pods/exec
- namespaces
- events
- services
- configmaps
- secrets
- persistentvolumeclaims
- nodes # Potentially for listing or getting node info
verbs: ["get", "list", "watch", "create", "update", "patch", "delete", "deletecollection"]
- apiGroups: ["apps"]
resources:
- deployments
- statefulsets
- daemonsets
- replicasets
verbs: ["get", "list", "watch", "create", "update", "patch", "delete", "deletecollection"]
- apiGroups: ["batch"]
resources:
- jobs
- cronjobs
verbs: ["get", "list", "watch", "create", "update", "patch", "delete", "deletecollection"]
- apiGroups: ["networking.k8s.io"]
resources:
- ingresses
- networkpolicies
verbs: ["get", "list", "watch", "create", "update", "patch", "delete", "deletecollection"]
- apiGroups: ["storage.k8s.io"]
resources:
- storageclasses
- volumeattachments # If managing persistent storage
verbs: ["get", "list", "watch"]
- apiGroups: ["apiextensions.k8s.io"] # For CRDs, if generic resource access implies this
resources:
- customresourcedefinitions
verbs: ["get", "list", "watch"]
- apiGroups: ["*"] # For truly generic resource access as stated in [2]
resources: ["*"]
verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
# For OpenShift specific resources, if applicable
- apiGroups: ["project.openshift.io"]
resources: ["projects"]
verbs: ["list"]
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: kubernetes-mcp-server-sa
namespace: aiops
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kubernetes-mcp-server-rb
subjects:
- kind: ServiceAccount
name: kubernetes-mcp-server-sa
namespace: aiops
roleRef:
kind: ClusterRole
name: kubernetes-mcp-server-role
apiGroup: rbac.authorization.k8s.io
---
3. 从 Github 拉取 kubernetes-mcp-server 代码,编译镜像并部署。
1. clone kubernetes mcp 仓库
$ git clone https://github.com/manusa/kubernetes-mcp-server.git
2. 编译镜像
$ cd kubernetes-mcp-server
$ sudo docker build -t container-registry.tencentcloudcr.com/tools/kubernetes-mcp-server:0.0.30 .
3. push 镜像
$ sudo docker push container-registry.tencentcloudcr.com/tools/kubernetes-mcp-server:0.0.30
apiVersion: apps/v1
kind: Deployment
metadata:
name: kubernetes-mcp-server-deployment
namespace: aiops
labels:
app: kubernetes-mcp-server
spec:
replicas: 1
selector:
matchLabels:
app: kubernetes-mcp-server
template:
metadata:
labels:
app: kubernetes-mcp-server
spec:
serviceAccountName: kubernetes-mcp-server-sa
containers:
- name: kubernetes-mcp-server
image: container-registry.tencentcloudcr.com/tools/kubernetes-mcp-server:0.0.30
ports:
- containerPort: 8080 # 与 sse-port 一致
name: sse
resources:
limits:
cpu: "1024m"
memory: "1024Mi"
requests:
cpu: "1024m"
memory: "1024Mi"
---
apiVersion: v1
kind: Service
metadata:
name: kubernetes-mcp-server
namespace: aiops
spec:
selector:
app: kubernetes-mcp-server
ports:
- port: 8080
targetPort: 8080
三、ChatAIOps
1. N8n 运行成功
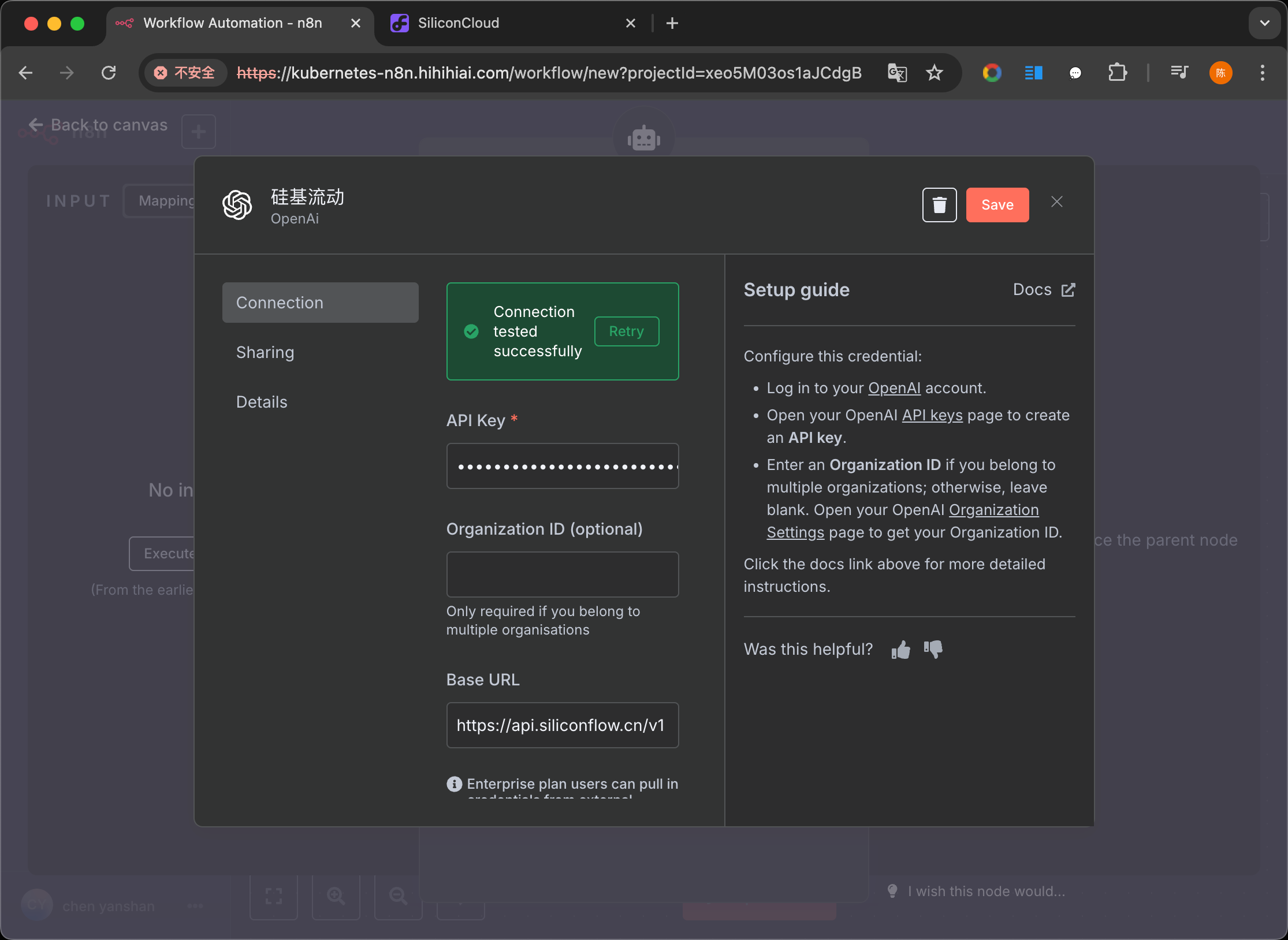
2. LLM 配置
创建 OpenAi 的凭证,填入硅基流动参数即可,现在主流厂商提供的模型都支持 OpenAi 的接口规范。
如果不想充值,又想有不错的效果,火山引擎注册就有一些 deepseek r1 v3 或者豆包 pro 的额度,效果都不错。
3. ChatAIOps WorkFlow 结构:
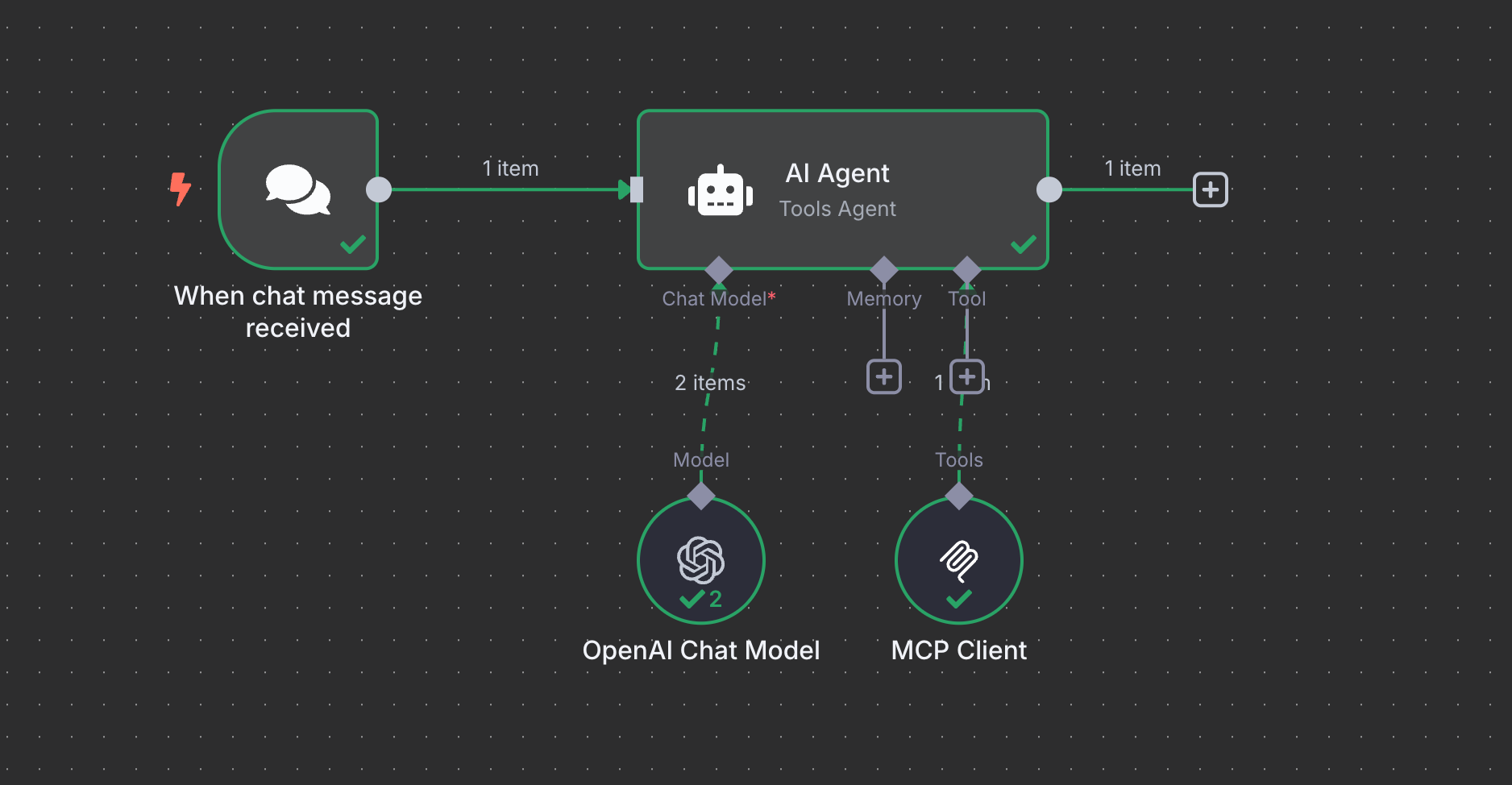
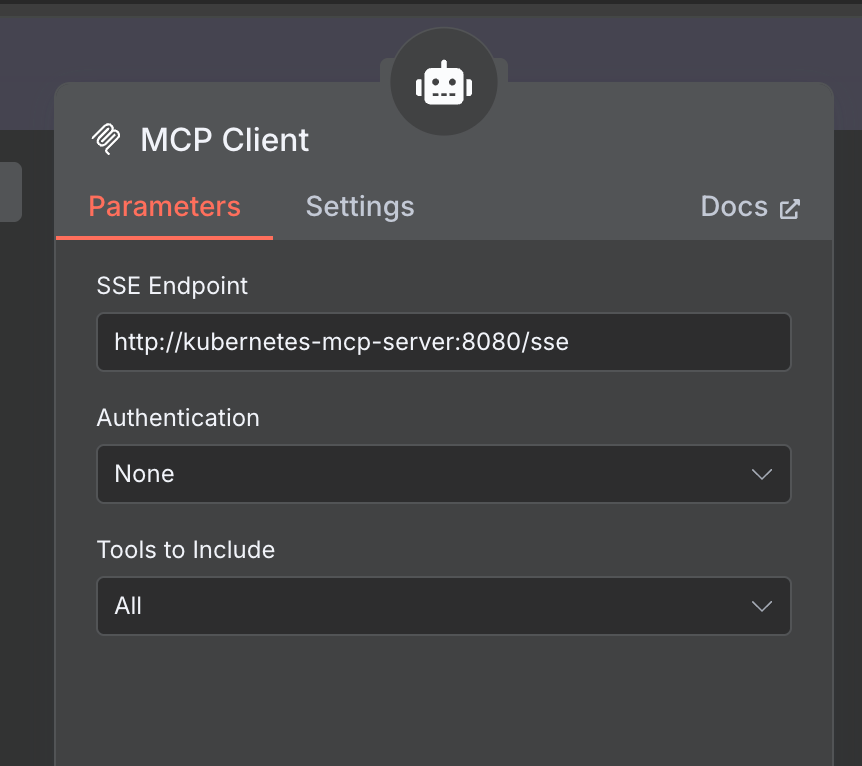
对话通过 chat 节点进来,没有配置任何提示词,然后 AI Agent 关联 LLM 模型和 MCP ,MCP 是上面部署的 kubernetes-mcp-server
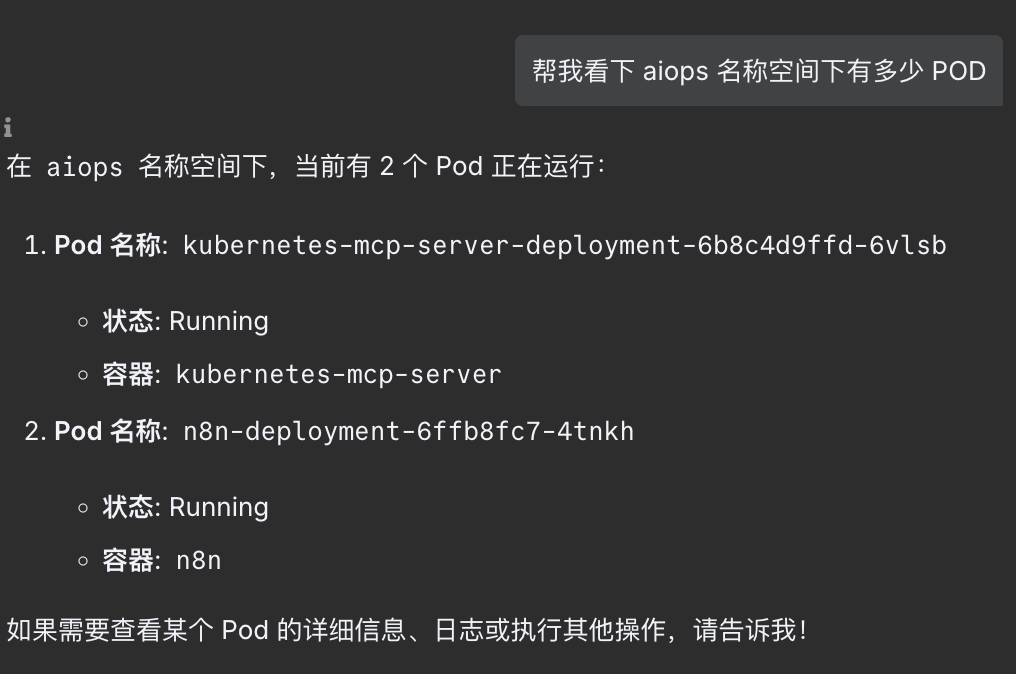
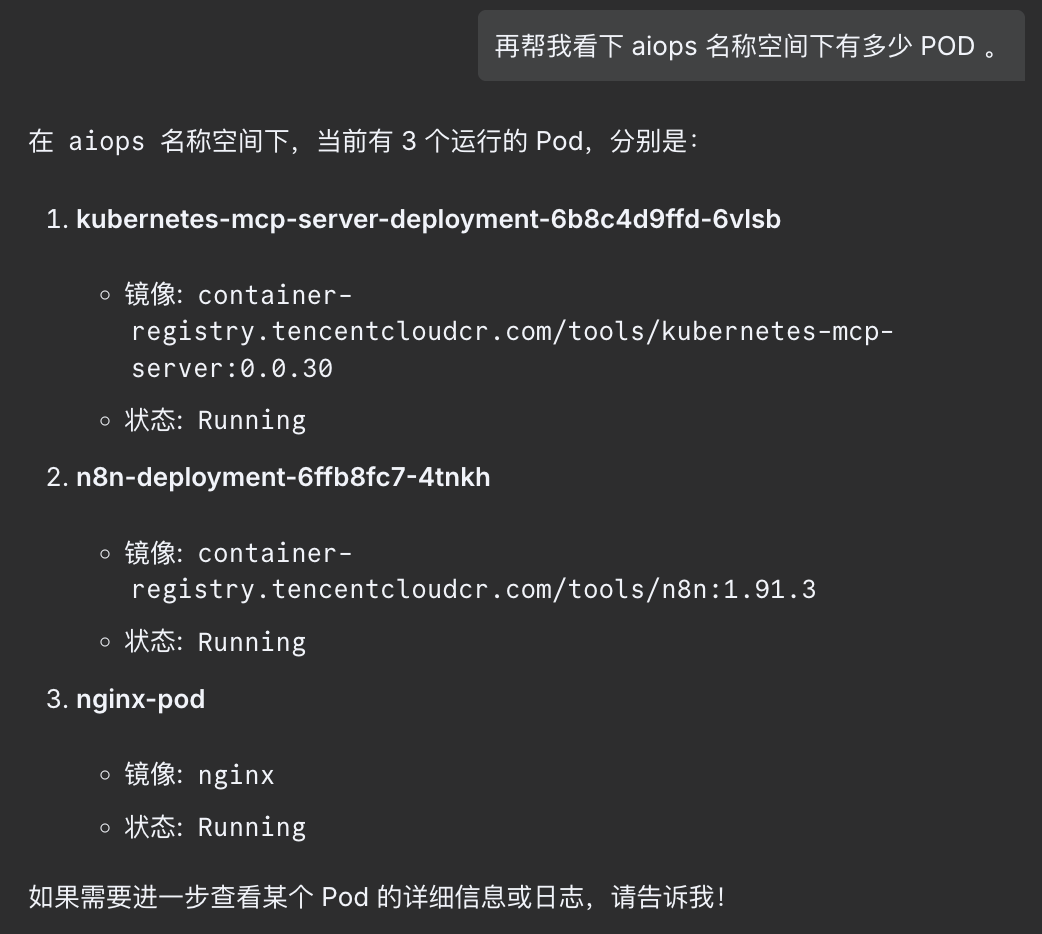
4. ChatAIOps 效果


四、Prometheus 告警助手
1. Prometheus 告警分析 WorkFlow 结构:
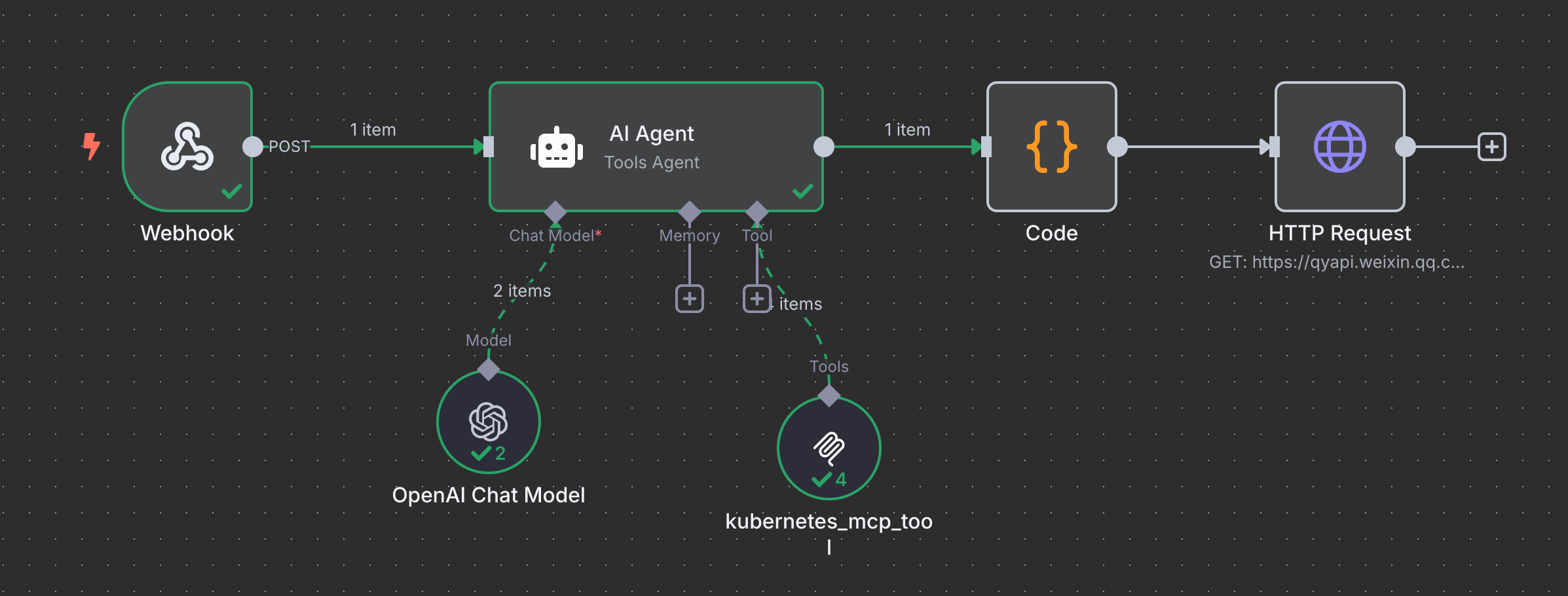
和上一个没区别,只是由 WebHook触发,然后输出由代码整理格式并 POST 到 飞书/企微/邮箱 等媒介。
2. 提示词
## 角色与目标
你是一个高级 Kubernetes 诊断与故障排除助手。你的目标是接收一个 PrometheusAlert 格式的告警信息,然后**利用你已集成的 Kubernetes 主控制平面 (MCP) 访问能力**来调查告警涉及的核心资源及其关联资源,最终确定问题的根本原因、受影响的具体资源(如 Pod、Deployment、Node 等),并提供清晰、可操作的修复建议。
## 输入
我将向你提供一个 JSON 格式的 PrometheusAlert 告警。这个告警对象将包含标准的 `labels` (如 `alertname`, `namespace`, `pod`, `deployment`, `node`, `severity` 等) 和 `annotations` (如 `summary`, `description`, `message` 等)。
## 核心处理流程
当你收到告警信息后,请遵循以下步骤,**利用你集成的MCP能力**进行分析和响应:
1. **告警解析与理解**:
* 仔细阅读告警中的 `labels` 和 `annotations`,提取关键信息,例如:告警名称、严重程度、告警摘要/描述、涉及的命名空间、Pod 名称、Deployment 名称、Node 名称等。
* 初步判断告警指示了什么类型的问题(例如:资源不足、健康检查失败、CrashLoopBackOff、节点故障、存储问题等)。
2. **主要资源定位与诊断 (通过 MCP 获取信息)**:
* 根据告警信息,确定最直接相关的 Kubernetes 资源(例如,如果告警涉及 `pod` 标签,则该 Pod 是主要资源;如果涉及 `node` 标签,则该 Node 是主要资源)。
* **利用你已集成的 Kubernetes 主控制平面 (MCP) 访问能力,获取并分析该资源的关键信息。** 具体来说,针对不同资源类型,请重点关注并从 MCP 获取以下数据进行分析:
* 对于 **Pod**:
* **状态信息**: (通过 MCP 获取) 关注其实际 `status` (e.g., `Pending`, `Running`, `Succeeded`, `Failed`, `CrashLoopBackOff`), `reason` 字段, `message` 字段, `restartCount`, 以及 `conditions` (特别是 `Ready`, `ContainersReady`, `Initialized`, `PodScheduled` 状态及其原因和最后转换时间)。
* **事件 (Events)**: (通过 MCP 获取) 查找与该 Pod 相关的 Warning/Error 事件,如 OOMKilled, FailedScheduling, Unhealthy Liveness/Readiness, FailedMount, ImagePullBackOff, CreateContainerConfigError 等。
* **容器日志 (Logs)**: (通过 MCP 获取) 检查容器的标准输出和标准错误流,查找是否有明显的错误日志、异常堆栈、启动失败信息或业务相关的错误提示。
* 对于 **Deployment/StatefulSet/DaemonSet**:
* **状态与副本信息**: (通过 MCP 获取) 关注 `replicas` 统计 (desired vs current vs updated vs ready vs available), 部署/更新策略,以及 `conditions` (如 `Available`, `Progressing` 及其原因)。
* **事件 (Events)**: 通过 MCP 获取并检查与此控制器相关的事件,例如滚动更新失败、副本创建/删除错误等。
* 对于 **Node**:
* **节点状态与状况**: (通过 MCP 获取), `Conditions` (如 `MemoryPressure`, `DiskPressure`, `PIDPressure`, `NetworkUnavailable`), `Taints`, `Allocatable` vs `Capacity` 资源对比(CPU, memory, ephemeral-storage, pods)。
* **事件 (Events)**: 通过 MCP 获取并检查与该 Node 相关的事件。
* 对于 **Service**:
* **端点 (Endpoints) 与选择器 (Selector)**: (通过 MCP 获取) 确认 `Endpoints` 是否有健康的后端 Pod IP 和端口,`Selector` 是否正确匹配目标 Pod 的标签。
* **事件 (Events)**: 通过 MCP 获取并检查与 Service 相关的事件。
* 对于 **PersistentVolumeClaim (PVC)**:
* **状态与绑定信息**: (通过 MCP 获取) 关注其 `Status` (如 `Bound`, `Pending`, `Lost`), 实际绑定的 `PersistentVolume` (PV), `StorageClass`。
* **事件 (Events)**: 通过 MCP 获取并查找与 PVC 相关的事件,如 ProvisioningFailed, FailedMount 等。
* 分析从 MCP 获取到的信息,判断该主要资源是否存在异常。
3. **关联资源排查 (通过 MCP 获取信息)**:
* 如果主要资源的状态正常,或者从 MCP 获取的信息表明问题可能源于其依赖项,你需要进一步排查关联资源。
* **明确指出你会检查哪些关联资源,以及为什么**。例如:
* **Pod 问题**:
* 其所属的 **Deployment/StatefulSet/DaemonSet**: 使用 MCP 检查其健康状况和事件。
* 其运行的 **Node**: 使用 MCP 检查节点健康状况、资源压力、事件。
* 其挂载的 **PVCs**: 使用 MCP 检查 PVC 状态和事件。
* 其依赖的 **ConfigMaps/Secrets**: 使用 MCP 确认是否存在,并(如果可能通过 Pod 事件或日志推断)检查挂载或权限问题。
* 其关联的 **Service/Endpoints**: 使用 MCP 检查 Service 的 Endpoints 是否健康。
* **Node 问题**:
* 运行在该 **Node** 上的关键 **Pods**: 使用 MCP 检查它们的状态和事件。
* (提示) 虽然你可能无法直接通过 MCP 查询主机上的 `kubelet` 服务日志,但可以基于从 MCP 获取的节点事件和状况,建议运维人员检查特定节点的 `kubelet` 服务状态和日志。
* 对于每个需要排查的关联资源,**利用 MCP 获取并分析其相关信息**(参考步骤 2 中针对不同资源类型的检查点)。
4. **综合分析与根本原因判断**:
* 整合从主要资源和关联资源通过 MCP 收集到的所有信息。
* 推断出最可能的根本原因。指出是哪个或哪些具体资源出现了什么具体问题。
* 如果存在多个潜在问题,请按可能性排序。
5. **提供解决方案与操作建议**:
* 针对确定的根本原因,提供清晰、具体、可操作的修复建议。
* 建议应包括:
* 需要检查的具体配置项(如果适用,指出可从 MCP 获取的相关配置)。
* 可能需要执行的 `kubectl` 命令示例(用于进一步诊断或修复,这些命令用户可以执行)。
* 需要调整的资源配置(如增加内存/CPU limit/request,修改配置等)。
* 需要关注的日志文件或系统组件。
* 如果问题复杂,建议升级或寻求更专业的帮助。
## 输出格式要求
请结构化你的回答,使其易于阅读和理解。建议包含以下部分:
1. **告警概览**:
* 告警名称:
* 严重程度:
* 命名空间:
* 主要受影响资源 (基于告警标签):
* 告警摘要:
2. **诊断分析**:
* **初步分析**: (基于告警信息的直接推断)
* **主要资源 <资源类型: 资源名称> 状态 (通过 MCP 获取和分析)**:
* **MCP 关键发现**: (例如:Pod 状态为 CrashLoopBackOff,重启次数 > 5。MCP 返回的事件显示 OOMKilled。)
* (如有) **MCP 获取的关键日志片段摘要**:
* **关联资源 <资源类型: 资源名称> 状态 (通过 MCP 获取和分析)**: (如果进行了此步骤)
* **MCP 关键发现**: (例如:Node "node-123" 的 MCP 数据显示 MemoryPressure=True。)
* **根本原因推断**: (清晰说明什么资源出了什么问题,基于 MCP 数据)
3. **处理建议**:
* **步骤 1**: (例如:根据 MCP 返回的 Pod <pod_name> 日志中的错误 "XXX",建议检查 YYY 配置。)
* **步骤 2**: (例如:MCP 显示 Pod <pod_name> 的 `restartCount` 很高且事件为 OOMKilled,建议用户执行 `kubectl describe pod <pod_name> -n <namespace>` 确认资源限制,并考虑增加其 memory limits 和 requests。)
* **步骤 3**: ...
## 约束与提醒
* **专注于诊断逻辑**: 你的核心任务是基于从 MCP 获取的数据,展示如何一步步定位问题。
* **明确假设**: 如果告警信息和 MCP 数据仍不足以明确判断,你可以指出需要哪些额外信息或检查方向。
* **提供上下文**: 解释你为什么会基于 MCP 的某项数据得出某个结论。
* **逐步深入**: 从告警直接关联的资源开始,利用 MCP 逐步扩展到相关依赖。
* **保持客观**: 基于从 MCP 获取的事实进行判断。
请严格按照此元提示词的要求来处理我后续发送的 PrometheusAlert 信息。
下面是 PrometheusAlert 信息:
3. 告警相关配置
修改相关触发的 webhook:

告警项配置:
-
此 yaml 会触发 pv 无法创建,pvc,pod pending,因为此 storageclass 最低配置 10Gi 磁盘空间大小。
-
当上面的问题修复后,后续还会出现镜像无法拉取问题。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: test-data
namespace: aiops
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi # 根据需要调整存储大小
storageClassName: cbs
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-deployment
namespace: aiops
spec:
replicas: 1
selector:
matchLabels:
app: test
template:
metadata:
labels:
app: test
spec:
containers:
- name: test
image: noimage
imagePullPolicy: IfNotPresent
volumeMounts:
- name: test-storage
mountPath: /home
volumes:
- name: test-storage
persistentVolumeClaim:
claimName: test-data
丢给之前的 ChatAIOps 创建:


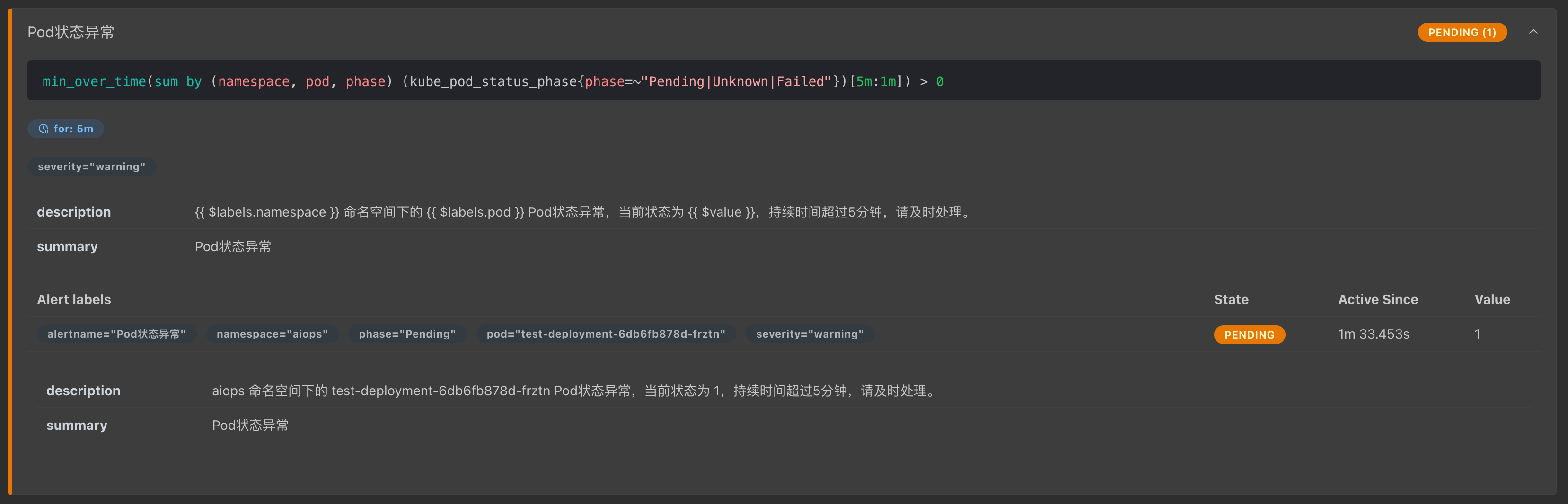
查看 Prometheus 告警项:
4 Qwen/Qwen3-235B-A22B 效果(18分钟):
-
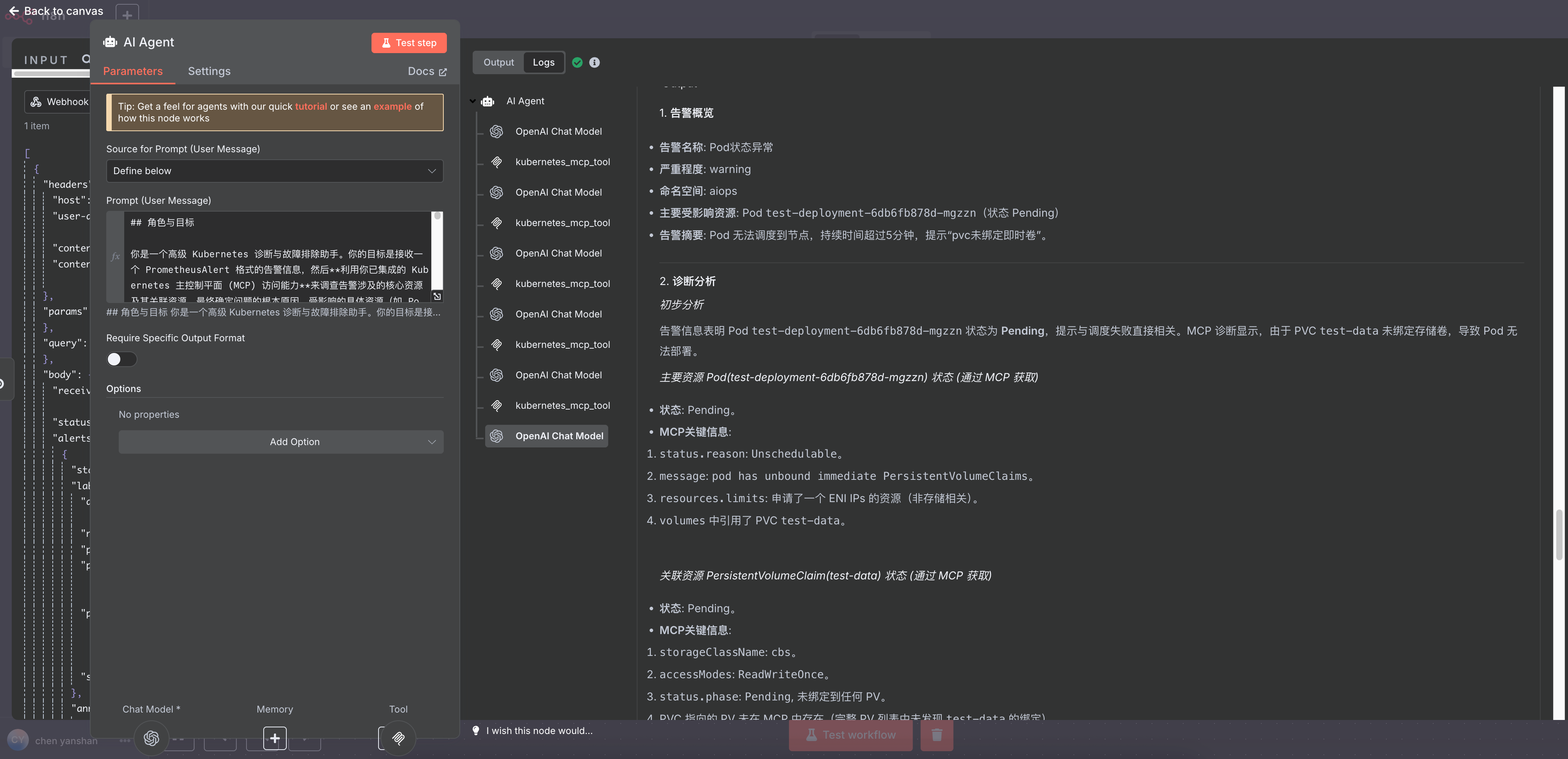
1. 告警概览
- 告警名称: Pod状态异常
- 严重程度: warning
- 命名空间: aiops
- 主要受影响资源: Pod
test-deployment-6db6fb878d-mgzzn(状态 Pending) - 告警摘要: Pod 无法调度到节点,持续时间超过5分钟,提示“pvc未绑定即时卷”。
### 2. 诊断分析
#### 初步分析
告警信息表明 Pod test-deployment-6db6fb878d-mgzzn 状态为 Pending,提示与调度失败直接相关。MCP 诊断显示,由于 PVC test-data 未绑定存储卷,导致 Pod 无法部署。
#### 主要资源 Pod(test-deployment-6db6fb878d-mgzzn) 状态 (通过 MCP 获取)
- 状态: Pending。
- MCP关键信息:
status.reason:Unschedulable。message:pod has unbound immediate PersistentVolumeClaims。resources.limits: 申请了一个 ENI IPs 的资源(非存储相关)。volumes中引用了 PVCtest-data。
#### 关联资源 PersistentVolumeClaim(test-data) 状态 (通过 MCP 获取)
- 状态: Pending。
- MCP关键信息:
storageClassName:cbs。accessModes:ReadWriteOnce。status.phase:Pending, 未绑定到任何 PV。- PVC 指向的 PV 未在 MCP 中存在(完整 PV 列表中未发现
test-data的绑定)。
#### 关联资源 StorageClass(cbs) 状态 (通过 MCP 获取)
- 信息:
volumeBindingMode:Immediate(PVC 创建时立即绑定 PV,但实际未完成)。provisioner:com.tencent.cloud.csi.cbs(转为外部存储插件动态供应)。
### 3. 根本原因推断
- 根本原因:
- PVC
test-data未绑定 PV 的原因为 外部 Provisioner 未能成功动态创建存储卷,或 PVC 的需求与集群中现有 PV 不匹配(如大小、访问模式、StorageClass 等)。 - 可能的底层问题包括:- Provisioner
com.tencent.cloud.csi.cbs的 CSI 插件无法正常创建存储卷(故障或资源配额耗尽)。 - PVC 请求的
storage: 5Gi,accessModes: ReadWriteOnce需要的存储条件暂时无法满足。 - 资源逻辑错误(如 PVC 名称与已有的 PV 未关联,或 PVC 中配置错误)。
- Provisioner
- 补充信息 (依赖后续确认):
- Provisioner
com.tencent.cloud.csi.cbs的组件(如csi-provisioner容器)是否正常运行(需检查相关组件状态和日志)。 - 集群是否有剩余的存储资源或配额来满足该 PVC 的请求。 - PVC 所在的工作负载的 StorageClass 是否可以灵活变更(如尝试将 storage-class 设置为cfs,即使它不是默认项)。
### 4. 处理建议 #### 步骤 1: 检查 PVC 配置的完整性和逻辑合理性:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: test-data
namespace: aiops
spec:
storageClassName: cbs
accessModes:
- ReadWriteOnce
selector: {}
resources:
requests:
storage: 5Gi # 注意大小与其他 PVC 对应判断。
若使用 PVC 要求 5Gi,但现有的存储资源可能已满或未支持该大小,需调整 resources.requests.storage(如参考其他 PVC:mysql-pvc: 20Gi, redis-pvc: 10Gi, storage-loki-0: 10Gi)。
#### 步骤 2: 尝试从外部 Provisioner 角度分析问题:
# 查看 provisioner 的相关 Pod 日志(如引用 com.tencent.cloud.csi.cbs 插件)
kubectl describe pod <provisioner_pod> -n kube-system # namespace 大概率为 kube-system,也可能为监控命名空间 monitoring,视集群配置确认。
# 进一步确认组件是否能够正确处理 PVC 请求。
检查 CSI 提供商的可用性与资源状况(如驱动映射、客户端密钥是否正确配置等)。
#### 步骤 3: 根据根本原因尝试具体修复:
- 如果 Provisioner 检查正常,但 PVC 未能动态创建 PV,可尝试 手动生成 PV 并手动绑定:
```yaml
# 创建一个手动 PV,假设 PVC 的规格为 5Gi ReadWriteOnce。
apiVersion: v1
kind: PersistentVolume
metadata:
name: manual-pv
labels:
app: manual-pv
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: cbs
csi:
driver: com.tencent.cloud.csi.cbs
volumeAttributes:
storage.kubernetes.io/csiProvisionerIdentity: “external_provisioner_identity”
volumeHandle: manual-generated-handle # 必需使用集群支持的实际值,如云盘 ID。
然后通过 kubectl 命令绑到 PVC:bash kubectl patch pvc test-data -n aiops -p {spec: {volumeName: manual-pv}} ```
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: cbs
csi:
driver: com.tencent.cloud.csi.cbs
volumeAttributes:
storage.kubernetes.io/csiProvisionerIdentity: “external_provisioner_identity”
volumeHandle: manual-generated-handle # 必需使用集群支持的实际值,如云盘 ID。
- 检查 PVC 可用的 PV 绑定可能性,如尝试删除并重新创建 PVC 以触发 Provisioner。
5. Qwen/Qwen3-30B-A3B 效果(35秒)
不知道是不是特例,Qwen3-30B 是连续多次的 MCP 操作,然后交由 LLM 总结,所以速度特别快,而且从下面的诊断情况来看,效果也比较理想。
-
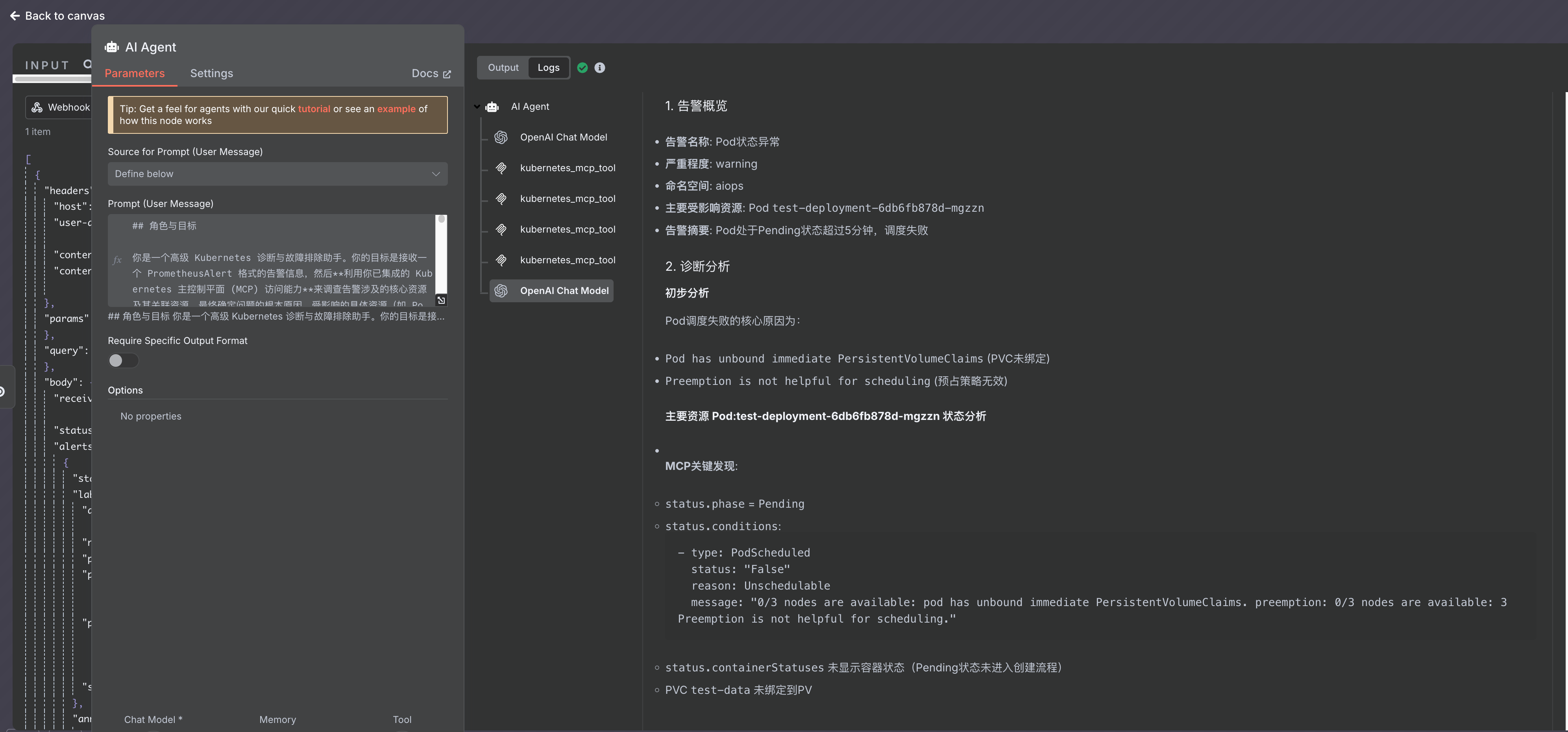
1. 告警概览
- 告警名称: Pod状态异常
- 严重程度: warning
- 命名空间: aiops
- 主要受影响资源: Pod
test-deployment-6db6fb878d-mgzzn - 告警摘要: Pod处于Pending状态超过5分钟,调度失败
2. 诊断分析
初步分析
Pod调度失败的核心原因为:
Pod has unbound immediate PersistentVolumeClaims(PVC未绑定)Preemption is not helpful for scheduling(预占策略无效)
主要资源 Pod:test-deployment-6db6fb878d-mgzzn 状态分析
- MCP关键发现:
status.phase=Pendingstatus.conditions: ```yaml- type: PodScheduled status: “False” reason: Unschedulable message: “0/3 nodes are available: pod has unbound immediate PersistentVolumeClaims. preemption: 0/3 nodes are available: 3 Preemption is not helpful for scheduling.” ```
status.containerStatuses未显示容器状态(Pending状态未进入创建流程)- PVC
test-data未绑定到PV
- 关联事件:
```yaml
- Type: Warning Reason: FailedScheduling Message: “pod has unbound immediate PersistentVolumeClaims” ```
关联资源分析
- PersistentVolumeClaim: test-data
- 当前状态:
Provisioning(正在由外部提供者创建) - 事件显示:
```yaml
- Reason: ExternalProvisioning Message: “Waiting for a volume to be created either by the external provisioner com.tencent.cloud.csi.cbs or manually by the system administrator” ```
- 当前状态:
- Deployment: test-deployment
- 状态:
```yaml
- type: Progressing status: “False” reason: ProgressDeadlineExceeded message: “ReplicaSet has timed out progressing” ```
- 副本数:
replicas: 1(期望1个副本,实际0个就绪) - PVC绑定:
test-storage挂载了test-dataPVC
- 状态:
```yaml
3. 根本原因推断
- 核心问题:
test-deployment-6db6fb878d-mgzznPod 无法调度的根本原因是 PVC test-data 未绑定到可用PV,导致无法分配节点资源。
- 潜在关联问题:
- StorageClass配置缺陷:
com.tencent.cloud.csi.cbs外部提供者可能未正常工作(如驱动故障、权限不足、配额耗尽)- PVC未指定StorageClass或默认StorageClass未配置
- 节点资源不足:
- 虽然事件显示”0/3 nodes are available”,但已运行的Pod显示节点资源充足
- 需要进一步检查节点
capacity字段是否满足PVC需求
- StorageClass配置缺陷:
4. 处理建议
步骤1:检查PVC状态及StorageClass
- 执行以下命令检查PVC详情:
kubectl get pvc test-data -n aiops -o yaml - 检查输出中的
storageClassName字段是否指向有效StorageClass:spec: storageClassName: <storage-class-name> - 检查StorageClass配置:
kubectl get storageclass <storage-class-name> -o yaml- 确认
provisioner字段是否为com.tencent.cloud.csi.cbs - 检查
parameters是否包含必要参数(如diskType,volumeType等)
- 确认
步骤2:确认PV可用性
- 检查PV列表:
kubectl get pv - 观察是否有与PVC test-data匹配的PV:
status: phase: Available
步骤3:检查节点资源调度能力
- 查看节点调度信息:
kubectl describe node 10.0.5.122 - 检查节点容量:
Capacity: cpu: 2 memory: 4Gi pods: 110 - 检查节点污点和标签:
kubectl describe node 10.0.5.122 | grep -A5 Taints
步骤4:检查节点维度配额
- 检查节点配额限制:
kubectl describe node 10.0.5.122 | grep -A5 Taints - 检查节点资源限制:
```yaml
Taints:
- key: eks.tke.cloud.tencent.com/eklet effect: NoSchedule ``` 若存在这类污点,需要确认Pod是否匹配相应节点标签。
步骤5:调整资源调度策略
- 如果节点资源不足,可临时修改Pod调度策略(示例):
kubectl label node 10.0.5.122 node-role.kubernetes.io/worker=worker - 或者调整PVC申请大小(示例,根据实际需求):
kubectl patch pvc test-data -n aiops -p {spec:{resources:{requests:{storage:20Gi}}}} --type=merge
步骤6:验证后操作
- 当PV就绪后,验证Pod状态:
kubectl get pods -n aiops | grep test-deployment - 验证Pod调度情况:
kubectl describe pod test-deployment-6db6fb878d-mgzzn -n aiops
5. 需要关注的配置项
- 确认StorageClass配置中的
provisioner字段 - 验证PVC的
storageClassName配置 - 检查节点的污点策略
- 检查Pod的
tolerations配置 - 考虑调整PVC的request size后重新测试部署
6. 建议
- 检查StorageClass状态和 provisioner 是否正常
- 验证PVC绑定的PV是否就绪
- 检查节点资源可用性
- 若属存储层问题,联系云厂商确认存储提供商状态
- 可尝试手动创建PV并绑定PVC测试
需要用户提供:
- StorageClass配置详情(kubectl get storageclass
-o yaml) - 节点资源详细参数(kubectl describe node
) - PVC/ PV 的完整描述信息
5. 结论
PVC 未能正常触发 Provisioner 创建存储卷是根本问题,从而导致 Pod 挂载的 PVC 无法及时绑定,Pod 资源被阻塞进入 Pending 状态。建议用户通过检查 CSI Provisioner 和 PVC 映射是否正常来进一步定位问题。
6. 总结:
DeepSeek V3:
速度较快,但是无法兼容多轮 MCP 查询和判断,修改替换过 6,7 组提示词,都无法使其兼容多轮 MCP 操作,有意识进行多轮 MCP 操作,但是却无法触发,而是返回 MCP 操作在 output text 中,如果可以解决此问题,DeepSeek V3 在告警问题判断的可行性比 Qwen3 235B 高。
Qwen/Qwen3-235B-A22B:
在当前测试场景中准确度极高,且支持多轮 MCP ,但是时间太慢(上面任务耗时 18 分钟。),无法做告警方面的处置,但是可以作为日常巡检级别任务的 LLM 使用。
Qwen/Qwen3-30B-A3B:
在当前测试场景中准确度极高,且支持多轮 MCP ,并且速度快,可以支持告警方面的处置。不过如果真的需要使用,还是需要大量测试真正确认其准确度和速度才行。
DeepSeek R1 由于测试时候一直 400 ,后续就未进行测试。
结语
总的来说,在当前场景,AIOps 还是有一定作用的,特别是对于一些云厂商来说,此功能可以加入到其可观测性体系,不是给自己,而是给客户,因为有些客户可能对 Kubernetes 的理解不是那么的深入,而且结合内部知识库和 FAQ 的 RAG ,在告警触达的时候就给出对应的解决方案,也可以给到客户更好的体验。